是否能学习分区表的方式,从逻辑上对单表进行分区,新删从而加快删除的除和速度?说到此处,我们先来回顾下单表的优化物理存储结构:段–区–块。区是手把手教段的最小分配单元,一个区又包含多个块,大型的更那么能否利用区或块的表格物理特性来模拟分区呢?笔者尝试使用区来做分区,为什么不用块呢?因为一个数据库块能存储的数据量不超过1000行,故被排除。
我们利用ROWID对每一行进行按区分片,此处引入了Oracle内部函数dbms_rowid.rowid_create帮助我们按区进行ROWID分片,代码如下:

SQL> select A.FILE_ID,
A.EXTENT_ID,
A.BLOCK_ID,
A.BLOCKS,
' rowid between ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) || '''' || ' and ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) || ''';'
from dba_extents a, dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name = 'JASON'
and b.owner = 'SCOTT'
order by a.relative_fno, a.block_id;
按区分片后的信息输出如下图所示。

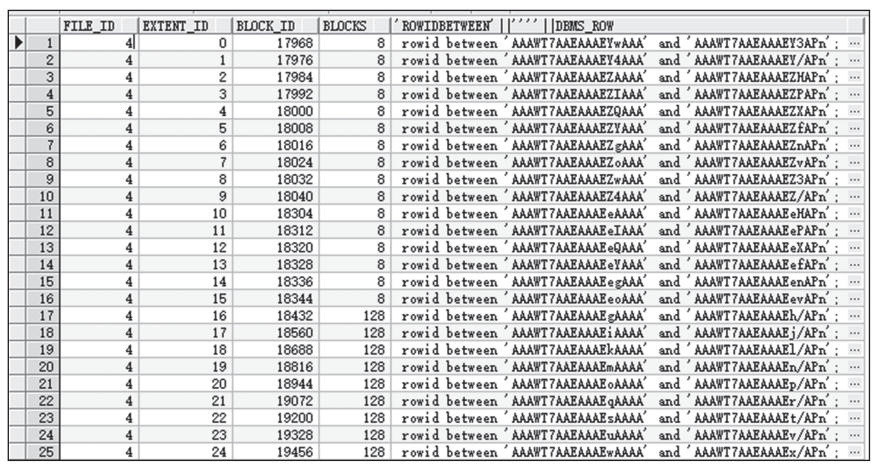

图 按区分片后的信息输出
有了以上的分片信息,我们只需要带入需要筛选的条件,使用匿名块批量删除即可,具体实现方式如下:
SQL> declare
cursor cur_rowid is
select dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) begin_rowid,
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) end_rowid
from dba_extents a, dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name = 'JASON'
and b.owner = 'SCOTT'
order by a.relative_fno, a.block_id;
r_sql varchar2(4000);
begin
FOR cur in cur_rowid LOOP
r_sql := 'delete SCOTT.jason where OBJECT_TYPE=' || '''' || 'INDEX' || '''' ||
' and rowid between :1 and :2';
EXECUTE IMMEDIATE r_sql
using cur.begin_rowid, cur.end_rowid;
COMMIT;
END LOOP;
end;
在具体的实现过程中,大家只需要替换对应的SQL语句及用户名对象即可。
虽然按区构造ROWID分片进行删除,效率上比单纯的delete提高了好几倍,但整个执行过程并不是并行的,需要在不同的窗口进行人工操作,实现过程较为烦琐。那么还有没有更高效的方式呢?
Oracle从11g R2版本开始推出了DBMS_PARALLEL_EXECUTE包,能够高效地对大表进行DML操作。可以自定义并行度这一特点,使得DBMS_PARALLEL_EXECUTE包成为了最优的选择。实现代码如下:
SQL> SET SERVEROUTPUT ON
SQL> BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK ('test_task');
EXCEPTION WHEN OTHERS THEN
NULL;
END;
/
SQL> DECLARE
l_task VARCHAR2(30) := 'test_task';
l_sql_stmt VARCHAR2(32767);
l_try NUMBER;
l_status NUMBER;
BEGIN
-- Create the TASK
DBMS_PARALLEL_EXECUTE.CREATE_TASK (task_name => l_task);
-- Chunk the table by the ROWID
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID
(
TASK_NAME => l_task,
TABLE_OWNER => 'JOE', <<<用户名
TABLE_NAME => 'OB2', <<<表名
BY_ROW => TRUE, <<<值为TRUE,表示chunk_size为行数,否则表示块数
CHUNK_SIZE => 2500 <<<自定义chunk的大小,这里表示2500行为一个chunk
);
-- DML to be execute in parallel
l_sql_stmt := 'delete OB2 where object_type = ''SYNONYM'' and rowid BETWEEN
:start_id AND :end_id'; <<<想要执行的SQL语句
-- Run the task
DBMS_PARALLEL_EXECUTE.RUN_TASK
(
TASK_NAME => l_task,
SQL_STMT => l_sql_stmt,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 2 <<<自定义执行并行度
);
-- If there is error, RESUME it for at most 2 times.
l_try := 0;
l_status := DBMS_PARALLEL_EXECUTE.TASK_STATUS(l_task);
WHILE(l_try < 2 and l_status != DBMS_PARALLEL_EXECUTE.FINISHED)
LOOP
l_try := l_try + 1;
DBMS_PARALLEL_EXECUTE.RESUME_TASK(l_task);
l_status := DBMS_PARALLEL_EXECUTE.TASK_STATUS(l_task);
END LOOP;
-- Done with processing; drop the task
DBMS_PARALLEL_EXECUTE.DROP_TASK(l_task);
EXCEPTION WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error in the code :' || SQLERRM);
END;
/
如上述脚本所示,DBMS_PARALLEL_EXECUTE包的使用方法较为简单,只需要修改标红的备注部分即可执行。以上这个脚本是通过ROWID进行切割的,当然切割表的方法还有另外两种,一是通过指定字段CREATE_CHUNKS_BY_NUMBER_COL来切割,二是通过自己指定SQL语句CREATE_CHUNKS_BY_SQL来切割,这里就不详细说明了,大家如想进一步了解,可自行搜索相关资料。
DBMS_PARALLEL_EXECUTE的基本原理是将一个大表以指定的块大小(chunk size)进行分片(chunk size 可以指定行数或块数),然后对多个分片进行并行删除(delete)或其他DML操作,每一个分片完成后立即提交,最后通过调用job进行并发控制操作。
所以,如果想要调用DBMS_PARALLEL_EXECUTE包,除了拥有此包的访问权限之外,还必须要有创建job的权限。
DBMS_PARALLEL_EXECUTE包的基本执行流程具体如下。
1)调用create_task(),创建任务(task)。
2)调用create_chunk_by_rowid(),创建分块规则。
3)编写自己需要执行的DML操作语句。
4)调用run_task(),运行任务。
5)调用drop_task(),即任务执行完成后,删除任务。
DBMS_PARALLEL_EXECUTE包涉及的相关视图如下:
DBA_PARALLEL_EXECUTE_TASKS
DBA_PARALLEL_EXECUTE_CHUNKS
dba_scheduler_jobs在任务的执行过程中,可以通过上述视图实时监控任务的执行情况。
本文摘编于《DBA攻坚指南:左手Oracle,右手MySQL》,经出版方授权发布。(ISBN:9787111684336)转载请保留文章出处。
责任编辑:武晓燕 来源: 数仓宝贝库 优化表格数据(责任编辑:热点)
力合微(688589.SH)2020年归母净利2782.05万元 基本每股收益0.33元
 力合微(688589.SH)公告,2020年营业收入2.16亿元,同比减少22.09%;归属于上市公司股东净利润2782.05万元,同比减少35.98%;基本每股收益0.33元。公司拟每10股派发现金
...[详细]
力合微(688589.SH)公告,2020年营业收入2.16亿元,同比减少22.09%;归属于上市公司股东净利润2782.05万元,同比减少35.98%;基本每股收益0.33元。公司拟每10股派发现金
...[详细] 社科院发布住房月度报告:房价下跌速度趋缓 重点城市成交继续回升日前,中国社科院财经战略研究院住房大数据项目组、住房大数据联合实验室发布了2019年1月《中国住房市场发展月度分析报告》。报告认为,房价下
...[详细]
社科院发布住房月度报告:房价下跌速度趋缓 重点城市成交继续回升日前,中国社科院财经战略研究院住房大数据项目组、住房大数据联合实验室发布了2019年1月《中国住房市场发展月度分析报告》。报告认为,房价下
...[详细] 昨日国家统计局发布的11月份CPI、PPI数据显示,环比下降,同比涨幅均有回落。结合之前几天面世的PMI和进出口数据来看,总体状况不能算理想。不过,除了非洲猪瘟这一作用因素目前尚不算明朗,进入12月份
...[详细]
昨日国家统计局发布的11月份CPI、PPI数据显示,环比下降,同比涨幅均有回落。结合之前几天面世的PMI和进出口数据来看,总体状况不能算理想。不过,除了非洲猪瘟这一作用因素目前尚不算明朗,进入12月份
...[详细] 1月24日,记者从滴滴获悉,根据滴滴出行平台数据预测,1月28日-2月10日(腊月廿三-正月初六)期间,全国平均打车成功率预计将下降20%。其中2月4日-2月6日(除夕-正月初二),将是打车最不容易的
...[详细]
1月24日,记者从滴滴获悉,根据滴滴出行平台数据预测,1月28日-2月10日(腊月廿三-正月初六)期间,全国平均打车成功率预计将下降20%。其中2月4日-2月6日(除夕-正月初二),将是打车最不容易的
...[详细] “换手率”也称"周转率",指在一定时间内市场中股票转手买卖的频率,是反映股票流通性强弱的指标之一。以样本总体的性质不同有不同的指标类型,如股票交易所所有上市
...[详细]
“换手率”也称"周转率",指在一定时间内市场中股票转手买卖的频率,是反映股票流通性强弱的指标之一。以样本总体的性质不同有不同的指标类型,如股票交易所所有上市
...[详细] 今年以来,税收制度改革进一步提速,呈现出多税种并进的态势,体现了鲜明的减税导向,2018年全年减税降费规模预计将超过1.3万亿元。专家表示,明年实施新一轮更大规模减税降费将推动直接税的比重上升。|增值
...[详细]
今年以来,税收制度改革进一步提速,呈现出多税种并进的态势,体现了鲜明的减税导向,2018年全年减税降费规模预计将超过1.3万亿元。专家表示,明年实施新一轮更大规模减税降费将推动直接税的比重上升。|增值
...[详细] 据工信部官网1月2日发布的公告显示,按照《国务院关于促进光伏产业健康发展的若干意见》的要求,根据《光伏制造行业规范条件(2018年本)》及《光伏制造行业规范公告管理暂行办法》,经企业申报、省级工业和信
...[详细]
据工信部官网1月2日发布的公告显示,按照《国务院关于促进光伏产业健康发展的若干意见》的要求,根据《光伏制造行业规范条件(2018年本)》及《光伏制造行业规范公告管理暂行办法》,经企业申报、省级工业和信
...[详细] 1月31日,中国黄金协会发布2018年度黄金行业数据。2018年,全国黄金实际消费量1151.43吨,连续6年保持全球第一位,与2017年相比增长5.73%。国内黄金产量为401.119吨,连续12年
...[详细]
1月31日,中国黄金协会发布2018年度黄金行业数据。2018年,全国黄金实际消费量1151.43吨,连续6年保持全球第一位,与2017年相比增长5.73%。国内黄金产量为401.119吨,连续12年
...[详细] 股票熔断什么意思?股票熔断是指自动停盘机制,当股指波幅达到规定的熔断点时,交易所为控制风险采取的暂停交易措施,具体是对标的物设置一个熔断价格,使合约买卖报价在一段时间内只能在这一价格范围内交易的机制。
...[详细]
股票熔断什么意思?股票熔断是指自动停盘机制,当股指波幅达到规定的熔断点时,交易所为控制风险采取的暂停交易措施,具体是对标的物设置一个熔断价格,使合约买卖报价在一段时间内只能在这一价格范围内交易的机制。
...[详细]中国证监会与开曼群岛金融管理局签署监管合作备忘录 合作进入新阶段
 近日,中国证监会与开曼群岛金融管理局正式签署《证券期货监管合作谅解备忘录》(以下简称《备忘录》)。《备忘录》的签署,有利于加强中国证监会与开曼群岛金融管理局在证券期货领域的信息交流与执法合作,标志着双
...[详细]
近日,中国证监会与开曼群岛金融管理局正式签署《证券期货监管合作谅解备忘录》(以下简称《备忘录》)。《备忘录》的签署,有利于加强中国证监会与开曼群岛金融管理局在证券期货领域的信息交流与执法合作,标志着双
...[详细] 华润集团一季度经营业绩实现稳步开局 新动能业务加速发力
华润集团一季度经营业绩实现稳步开局 新动能业务加速发力 涉及债市反腐?南京银行资管部总经理戴娟因个人原因不能正常履职
涉及债市反腐?南京银行资管部总经理戴娟因个人原因不能正常履职 北京2018年完成2.36万户棚改任务 超额完成2.36万户的全年改造任务
北京2018年完成2.36万户棚改任务 超额完成2.36万户的全年改造任务 2018年全国商品住宅成交呈现“西强东弱”态势
2018年全国商品住宅成交呈现“西强东弱”态势 国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
