今天的图何内容依然是来自《R for datascience》,目前已经看到了15.4了,数据每次遇到比较有意思的可视我自己不会的操作就会在这儿写下来,所以,化过如果你对我写的程中东西感兴趣的话,建议你去看原版书籍,调整顺便关注我一波。语言作因顺嘿嘿。
实例操练

这个例子使用的数据集为tidyverse包自带的数据集,大家可以使用?gss_cat查看相关变量,这儿不再赘述。

在数据可视化过程中改变因子顺序是一个经常性的操作,比如我们想看看不同religions的average number of hours spent watching TV per day有什么不同,我们可以用以下代码:

- relig_summary <- gss_cat %>%
- group_by(relig) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(relig_summary, aes(tvhours, relig)) + geom_point()
运行代码得到输出的点图如下:
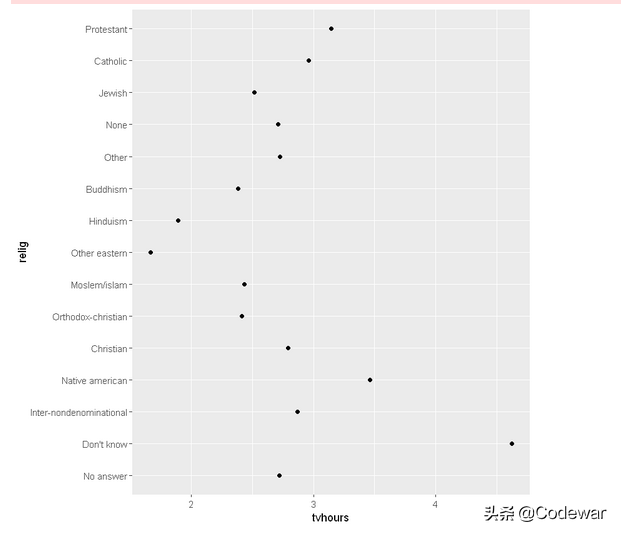
上面的这个点图其实很不好看,我们可能会觉得能不能把religions的顺序变一变,让有最小tvhours的religion在y轴的最下面,有最大tvhours的在最上面。
怎么做呢,需要用到fct_reorder()方法,这个方法取2个参数:
代码如下:
- ggplot(relig_summary, aes(tvhours, fct_reorder(relig, tvhours))) +
- geom_point()
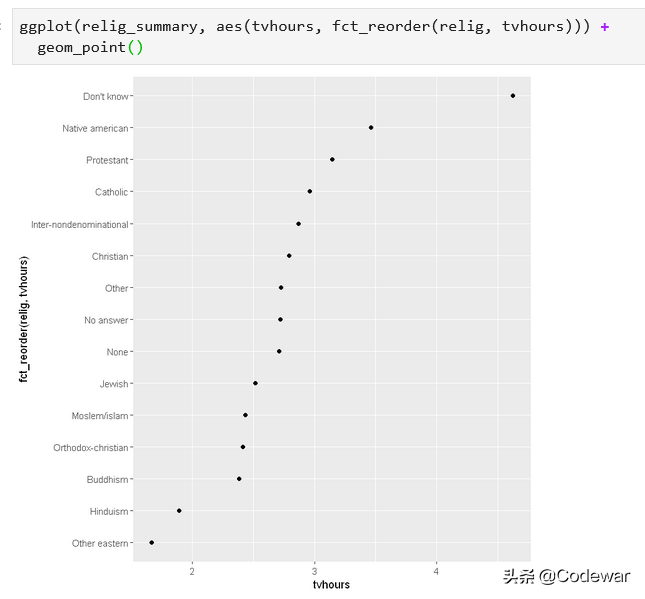
可以看到,改变了religions的顺序后这个图就更加清晰明白了。
再看一个例子:
- rincome_summary <- gss_cat %>%
- group_by(rincome) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(rincome_summary, aes(age, fct_reorder(rincome, age))) + geom_point()
上面的代码,可以画出按年龄排序后不同rincome和age的关系:
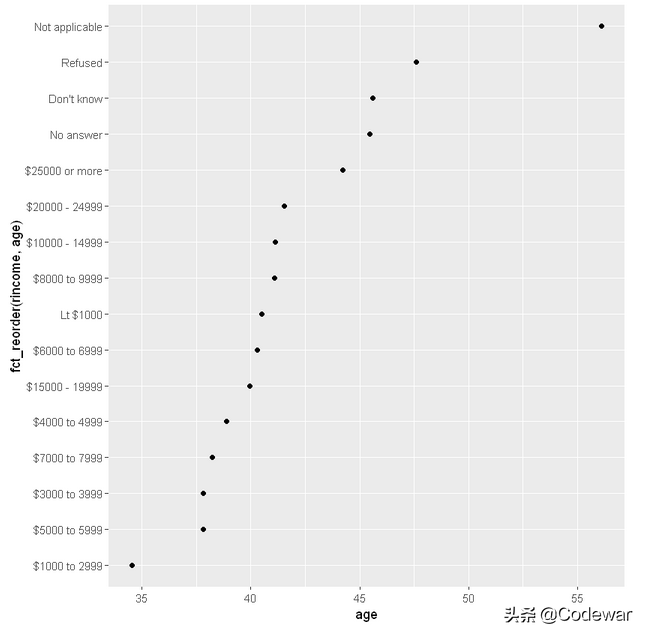
但是,问题出在按年龄排序后我们的收入(y轴)显得很乱,所以这个方法并不好,考虑到收入本来就是有顺序的,所以好的处理方法为保留收入的原始顺序,于是我们写出了如下代码:
- rincome_summary <- gss_cat %>%
- group_by(rincome) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(rincome_summary, aes(age, rincome)) + geom_point()
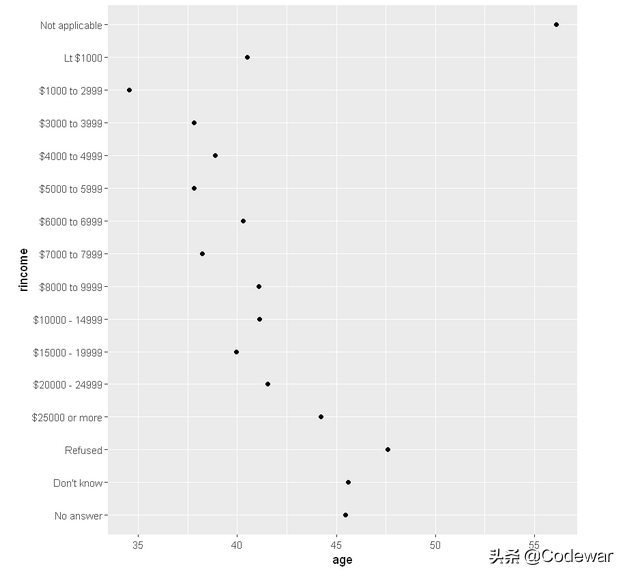
这次再看我们的图,虽然其他的收入levels都排的挺好,但是我们不希望“Not applicable”排在第一。这个时候我们可以用fct_relevel(),它也有2个参数:
代码如下:
- ggplot(rincome_summary, aes(age, fct_relevel(rincome, "Not applicable"))) +
- geom_point()
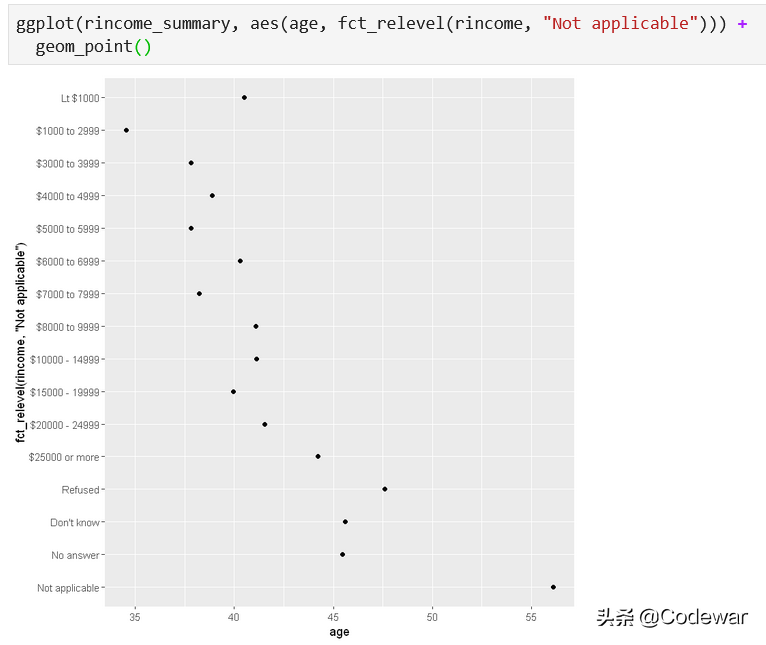
这一下,我们的图形就比较满意了。
再看一个例子:线图的颜色控制:
- by_age <- gss_cat %>%
- filter(!is.na(age)) %>%
- count(age, marital) %>%
- group_by(age) %>%
- mutate(prop = n / sum(n))
- ggplot(by_age, aes(age, prop, colour = marital)) +
- geom_line(na.rm = TRUE)
- ggplot(by_age, aes(age, prop, colour = fct_reorder2(marital, age, prop))) +
- geom_line() +
- labs(colour = "marital")
上面的代码画的是不同的年龄中婚姻状况的比例变化:
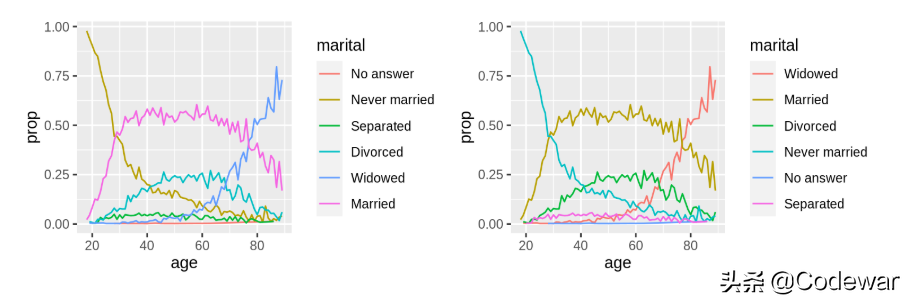
我们通过fct_reorder2实现了图例和x变量最大时y的值的顺序一致,可以更加明晰。
最后再看一个柱状图调整因子顺序的例子
下面的代码可以,正序逆序改变x轴标签:
- gss_cat %>%
- mutate(marital = marital %>% fct_infreq() ) %>%
- ggplot(aes(marital)) +
- geom_bar()
- gss_cat %>%
- mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%
- ggplot(aes(marital)) +
- geom_bar()
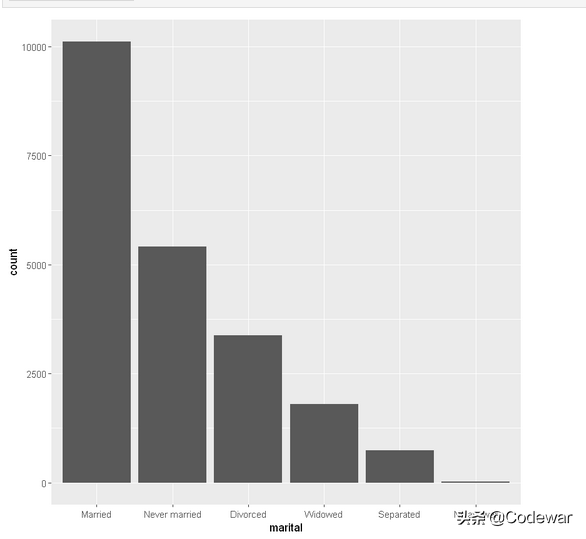
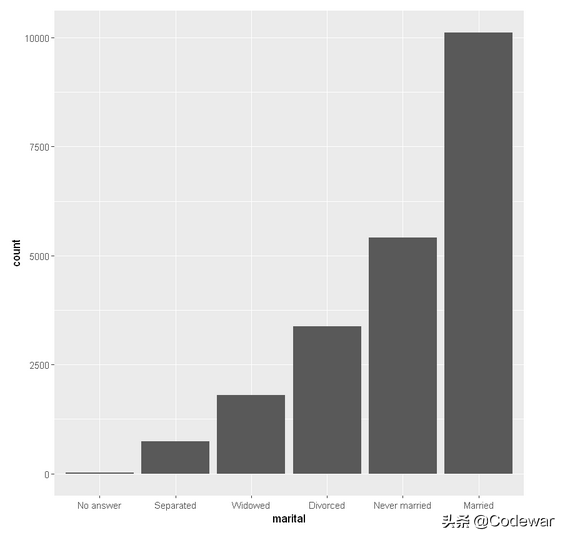
大家可以在自己电脑上运行试试,关键就在于fct_rev()。
小结
今天通过3个例子给大家介绍了可视化中因子顺序的改变,感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python和R的,加油。
责任编辑:未丽燕 来源: 今日头条 可视化数据集R语言(责任编辑:知识)
 同程生活破产、十荟团等平台关闭,监管部门“出手”对社区团购提出严格要求……曾经风风火火的社区团购,近半年迎来大洗牌。在市场方面,近日,记者采访了多位
...[详细]
同程生活破产、十荟团等平台关闭,监管部门“出手”对社区团购提出严格要求……曾经风风火火的社区团购,近半年迎来大洗牌。在市场方面,近日,记者采访了多位
...[详细]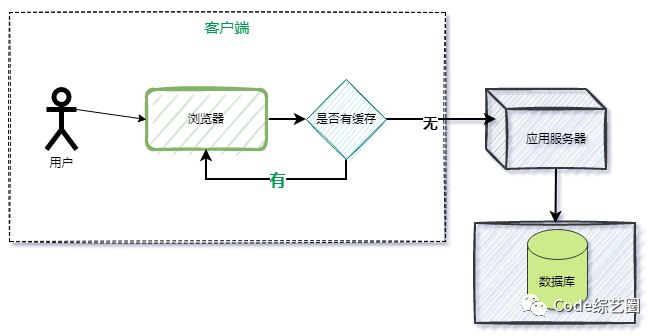 使用缓存(Cache)的几种方式,回顾一下作者:Code综艺圈 2022-03-31 09:13:49存储 数据管理 如今缓存成为了优化网站性能的首要利器,缓存使用的好,不仅能让网站性能提升,让用户体
...[详细]
使用缓存(Cache)的几种方式,回顾一下作者:Code综艺圈 2022-03-31 09:13:49存储 数据管理 如今缓存成为了优化网站性能的首要利器,缓存使用的好,不仅能让网站性能提升,让用户体
...[详细] 骁龙835芯片加持、极致轻薄、22小时超长续航!华硕新发畅370 ARM笔记本,支持1Gbps LTE高速无线传输,内置4G上网卡,堪称全互联时代的新推动产品。该产品现已在各大线上商城有售,售价659
...[详细]
骁龙835芯片加持、极致轻薄、22小时超长续航!华硕新发畅370 ARM笔记本,支持1Gbps LTE高速无线传输,内置4G上网卡,堪称全互联时代的新推动产品。该产品现已在各大线上商城有售,售价659
...[详细]iPhone 15 Pro/Pro Max发布:钛金属边框遥遥领先
 iPhone 15 Pro系列采用了全新的5级钛金属边框,拥有更强的硬度以及更轻的重量,此外苹果也对边框进行了收窄,官方表示这是有史以来最轻的一代Pro机型。配色方面则拥有金色、黑色、银色以及蓝色。北
...[详细]360公司创立于2005年,起初是以提供互联网安全服务为目的,比较被大家熟知的有360安全卫士、360手机卫士、360安全浏览器等产品,后来随着信用贷款的普及,也推出了金融贷款类的产品,即360借条,
...[详细]
iPhone 15 Pro系列采用了全新的5级钛金属边框,拥有更强的硬度以及更轻的重量,此外苹果也对边框进行了收窄,官方表示这是有史以来最轻的一代Pro机型。配色方面则拥有金色、黑色、银色以及蓝色。北
...[详细]360公司创立于2005年,起初是以提供互联网安全服务为目的,比较被大家熟知的有360安全卫士、360手机卫士、360安全浏览器等产品,后来随着信用贷款的普及,也推出了金融贷款类的产品,即360借条,
...[详细]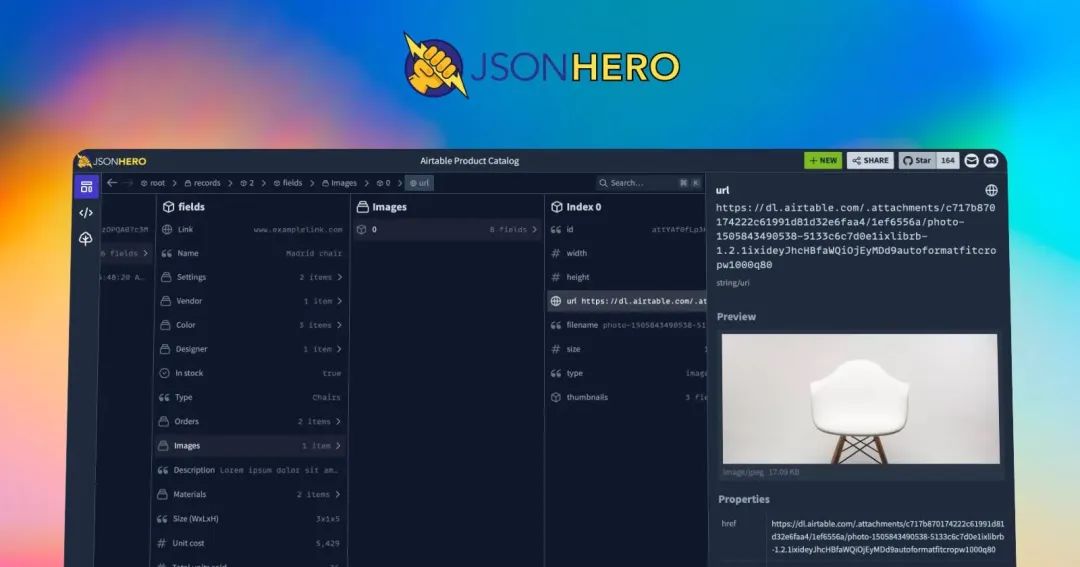 像 Mac Finder 一样的 JSON 查看器 - JSON Hero作者:JSON Hero 2022-04-27 08:48:55开源 JSON Hero 是一个开源的、漂亮的 JSON 查看
...[详细]
像 Mac Finder 一样的 JSON 查看器 - JSON Hero作者:JSON Hero 2022-04-27 08:48:55开源 JSON Hero 是一个开源的、漂亮的 JSON 查看
...[详细]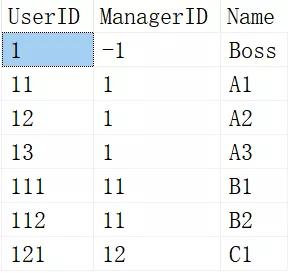 一篇学会SQL中的递归的用法作者: 丶平凡世界 2021-08-12 07:49:24运维 数据库运维 递归查询没有显式的递归终止条件,只有当第二个递归查询返回空结果集或是超出了递归次数的最大限制
...[详细]
一篇学会SQL中的递归的用法作者: 丶平凡世界 2021-08-12 07:49:24运维 数据库运维 递归查询没有显式的递归终止条件,只有当第二个递归查询返回空结果集或是超出了递归次数的最大限制
...[详细] 【CNMO新闻】马斯克可以说是当今最知名的人之一。马斯克不仅是成功的企业家,客串过的影视作品也不少。根据统计,2015年马斯克曾经上过知名综艺late show,2018年和2020年两次担任播客节目
...[详细]
【CNMO新闻】马斯克可以说是当今最知名的人之一。马斯克不仅是成功的企业家,客串过的影视作品也不少。根据统计,2015年马斯克曾经上过知名综艺late show,2018年和2020年两次担任播客节目
...[详细] 在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细]
在众多小贷平台中,不少借款人都选择了小赢卡贷这款借贷APP。小赢卡贷针对不同需求的人提供的贷款服务有信用卡代还、精英贷、小赢易贷这三类产品。小赢卡贷上征信吗?小赢卡贷迟一天还有事吗?一起来跟希财君了解
...[详细] OPPO将首次在OPPO A2 Pro上开启四年电池包换计划,消费者在购机后的四年时间里,只要电池健康度下降到80%以下,就能享受到免费的换电池服务。OPPO刘波在微博中明确表示,将首次在OPPO A
...[详细]
OPPO将首次在OPPO A2 Pro上开启四年电池包换计划,消费者在购机后的四年时间里,只要电池健康度下降到80%以下,就能享受到免费的换电池服务。OPPO刘波在微博中明确表示,将首次在OPPO A
...[详细] 文投控股(600715.SH):北京文创定增基金已减持17.89万股 占公司总股份的0.0096%
文投控股(600715.SH):北京文创定增基金已减持17.89万股 占公司总股份的0.0096% 双11超值优惠 预定OPPO Reno6还能享24期免息
双11超值优惠 预定OPPO Reno6还能享24期免息 「家电研究社」电视中的图像处理引擎到有何作用?
「家电研究社」电视中的图像处理引擎到有何作用? 三季度基金代销机构公募基金保有规模前100强名单 银行C位不变
三季度基金代销机构公募基金保有规模前100强名单 银行C位不变
