开源社区的秒个码生一位开发者Georgi Gerganov发现,自己可以在M2 Ultra上运行全F16精度的成最34B Code Llama模型,而且推理速度超过了20 token/s。拿手


毕竟,不用M2 Ultra的亿参带宽有800GB/s。其他人通常需要4个高端GPU才能做到!秒个码生

而这背后真正的成最答案是:投机采样(Speculative Sampling)。

Georgi的拿手这一发现,瞬间引爆AI圈大佬的讨论。
Karpathy转发评论道,「LLM的投机执行是一种出色的推理时间优化」。

在这个例子中,Georgi借助Q4 7B quantum草稿模型(也就是Code Llama 7B)进行了投机解码,然后在M2 Ultra上使用Code Llama34B进行生成。
简单讲,就是用一个「小模型」做草稿,然后用「大模型」来检查修正,以此加速整个过程。

GitHub地址:https://twitter.com/ggerganov/status/1697262700165013689
根据Georgi介绍,这些模型的速度分别为:
- F16 34B:~10 token/s
- Q4 7B:~80 token/s
如下是没有使用投机采样,标准F16采样示例:
然而,加入了投机采样策略后,速度可达~20 token/s。
Georgi表示,当然,速度会因生成的内容而异。但这种方法在代码生成方面似乎效果很好,因为大多数词库都能被草稿模型正确猜出。
如果使用「语法采样」的用例也可能从中受益匪浅。

投机采样能够实现快速推理的背后具体如何实现?
Karpathy根据此前谷歌大脑、UC伯克利、DeepMind的三项研究,做出了解释。

论文地址:https://arxiv.org/pdf/2211.17192.pdf

论文地址:https://arxiv.org/pdf/1811.03115.pdf

论文地址:https://arxiv.org/pdf/2302.01318.pdf
这取决于以下不直观的观察结果:
在单个输入token上转发LLM所需的时间,与在K个输入token上批量转发LLM所需的时间相同(K比你想象的要大)。
这个不直观的事实是因为采样受到内存的严重限制,大部分「工作」不计算,而是将Transformer的权重从VRAM读取到芯片上缓存中进行处理。

因此,如果要完成读取所有权重的工作,还不如将它们应用到整批输入向量中。、
我们之所以不能天真地利用这一事实,来一次采样K个token,是因为每N个token都取决于,我们在第N-1步时采样的token。这是一种串行依赖关系,因此基线实现只是从左到右逐个进行。
现在,巧妙的想法是使用一个小而廉价的草稿模型,首先生成一个由K个token组成的候选序列——「草稿」。然后,我们将所有这些信息一起批量送入大模型。
根据上述方法,这与只输入一个token的速度几乎一样快。
然后,我们从左到右检查模型,以及样本token预测的logits。任何与草稿一致的样本都允许我们立即跳转到下一个token。
如果有分歧,我们就会扔掉草稿模型,承担做一些一次性工作的成本(对草稿模型进行采样,并对后面的token进行前向传递)。
这在实践中行之有效的原因是,大多数情况下,draft token都会被接受,因为是简单的token,所以即使是更小的草稿模型也能接受它们。
当这些简单的token被接受时,我们就会跳过这些部分。大模型不同意的困难token会「回落」到原始速度,但实际上因为有额外的工作会慢一些。
所以,总而言之:这一怪招之所以管用,是因为LLM在推理时是受内存限制。在「批大小为1」的情况下,对感兴趣的单个序列进行采样,而大部分「本地 LLM」用例都属于这种情况。而且,大多数token都很「简单」。
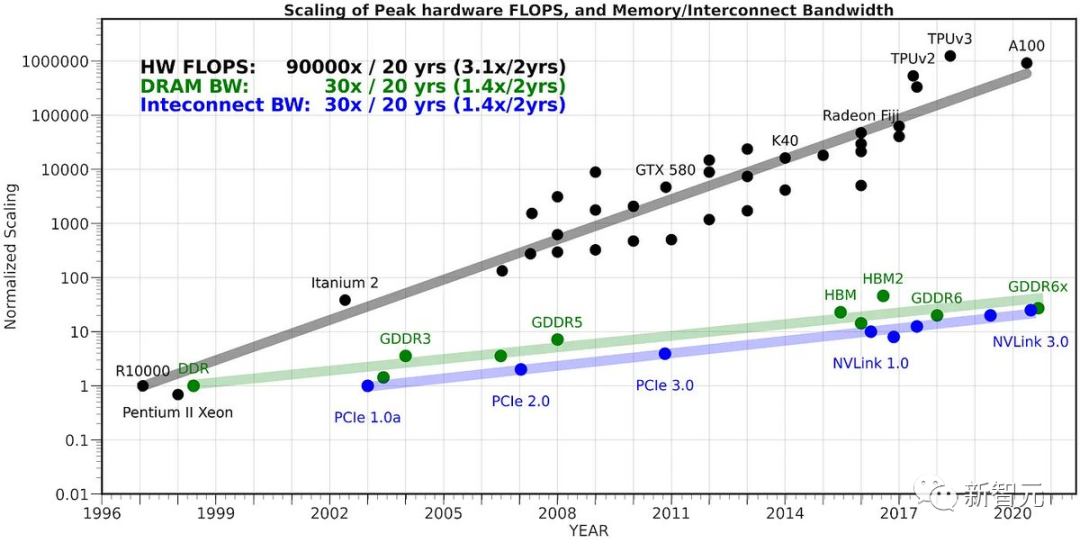
HuggingFace的联合创始人表示,340亿参数的模型在一年半以前的数据中心之外,看起来非常庞大和难以管理。现在是笔记本就可以搞定了。

现在的LLM并不是单点突破,而是需要多个重要组件有效协同工作的系统。投机解码就是一个很好的例子,可以帮助我们从系统的角度进行思考。
(责任编辑:热点)
10月份安徽省居民消费价格同比上涨1.7% 涨幅比上月扩大1.0个百分点
 国家统计局安徽调查总队发布数据显示,10月份,全省居民消费价格同比上涨1.7%,涨幅比上月扩大1.0个百分点;环比上涨0.6%,涨幅比上月扩大0.3个百分点。成品油价上涨催生液化石油气价格上涨,蔬菜价
...[详细]
国家统计局安徽调查总队发布数据显示,10月份,全省居民消费价格同比上涨1.7%,涨幅比上月扩大1.0个百分点;环比上涨0.6%,涨幅比上月扩大0.3个百分点。成品油价上涨催生液化石油气价格上涨,蔬菜价
...[详细] 雷锋网新智造按:信智资本是一支中美跨境基金,关注从种子期到B轮的移动SaaS软件运营服务)、应用平台、软硬件结合的初创项目。目前包括消费升级、人工智能、市场平台三个主要投资领域,此外还涉及企业软件领域
...[详细]
雷锋网新智造按:信智资本是一支中美跨境基金,关注从种子期到B轮的移动SaaS软件运营服务)、应用平台、软硬件结合的初创项目。目前包括消费升级、人工智能、市场平台三个主要投资领域,此外还涉及企业软件领域
...[详细]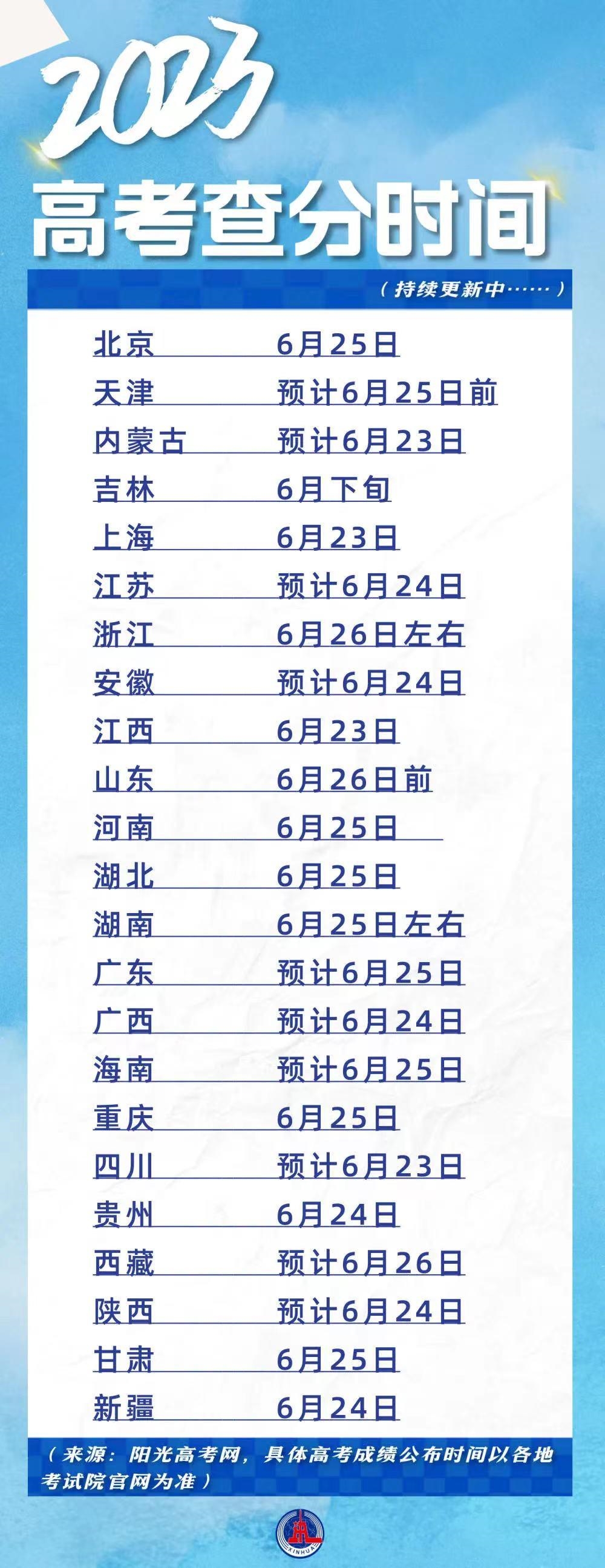 端午假期恰逢高考成绩公布。按照之前各地公布的高考查分时间,各地高考成绩将于今天起陆续公布,大部分查分时间将集中在今天到6月26日之间。其中,四川、内蒙古、江西、上海等预计今天6月23日)公布成绩;安徽
...[详细]
端午假期恰逢高考成绩公布。按照之前各地公布的高考查分时间,各地高考成绩将于今天起陆续公布,大部分查分时间将集中在今天到6月26日之间。其中,四川、内蒙古、江西、上海等预计今天6月23日)公布成绩;安徽
...[详细] 2017年4月26日,小米在俄罗斯召开发布会雷锋网5月9日消息,《环球时报》引用俄罗斯“今日经济网”消息称,俄罗斯海关近日将中国小米手机列入海关知识产权清单中。这意味着,俄罗斯海关将把所有邮往俄罗斯的
...[详细]
2017年4月26日,小米在俄罗斯召开发布会雷锋网5月9日消息,《环球时报》引用俄罗斯“今日经济网”消息称,俄罗斯海关近日将中国小米手机列入海关知识产权清单中。这意味着,俄罗斯海关将把所有邮往俄罗斯的
...[详细]皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
 皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细]
皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细] CA昨晚发布了《全面战争:法老》新的开发日志视频,介绍了本作新加入的一些游戏技术和机制。一起来看看吧~据悉,《全面战争:法老》加入了新的技术,玩家可以对很多对象发动火攻,比如草丛、高草丛、森林、建筑物
...[详细]
CA昨晚发布了《全面战争:法老》新的开发日志视频,介绍了本作新加入的一些游戏技术和机制。一起来看看吧~据悉,《全面战争:法老》加入了新的技术,玩家可以对很多对象发动火攻,比如草丛、高草丛、森林、建筑物
...[详细] 雷锋网5月9日消息,高通于今日正式推出了骁龙660和骁龙630两款全新移动平台,其中骁龙660为骁龙653的后续产品,骁龙630为骁龙625的后续产品。据悉,高通骁龙660移动平台已经开始出货,骁龙6
...[详细]
雷锋网5月9日消息,高通于今日正式推出了骁龙660和骁龙630两款全新移动平台,其中骁龙660为骁龙653的后续产品,骁龙630为骁龙625的后续产品。据悉,高通骁龙660移动平台已经开始出货,骁龙6
...[详细] 6月25日今天,由日本Crazy Raccoon电竞俱乐部主办,目前日本国内最大级别电竞大会《CR杯》的《街头霸王6》首届大赛将于北京时间17点开战,多位街霸圈知名选手参加,敬请期待。·Crazy R
...[详细]
6月25日今天,由日本Crazy Raccoon电竞俱乐部主办,目前日本国内最大级别电竞大会《CR杯》的《街头霸王6》首届大赛将于北京时间17点开战,多位街霸圈知名选手参加,敬请期待。·Crazy R
...[详细]彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效
 彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细]
彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细]Qloud Games新游《Loftia》仅用一天收获双倍众筹资金
 Qloud Games工作室开发的一款新游《Loftia》,因为资金问题受到了阻碍。但团队成员并没有放弃,他们在8月1日开启了资金的众筹。令人惊讶的是众筹项目仅用了一天的时间就达成了双倍支援金额目标。
...[详细]
Qloud Games工作室开发的一款新游《Loftia》,因为资金问题受到了阻碍。但团队成员并没有放弃,他们在8月1日开启了资金的众筹。令人惊讶的是众筹项目仅用了一天的时间就达成了双倍支援金额目标。
...[详细] 国内首座碳纤维索公路斜拉桥通车 采用双向6车道设计
国内首座碳纤维索公路斜拉桥通车 采用双向6车道设计 《信长之野望・新生with威力加强版》PV2 7月20日正式发售
《信长之野望・新生with威力加强版》PV2 7月20日正式发售 《星空》新截图公开!越过城墙还有野兽在等着你
《星空》新截图公开!越过城墙还有野兽在等着你 Meta公布版本55更新 将提升Quest 2和Pro头显性能
Meta公布版本55更新 将提升Quest 2和Pro头显性能 北交所开市首日三大看点 10股盘中均二次临停
北交所开市首日三大看点 10股盘中均二次临停
