译者 | 陈峻
审校 | 重楼

众所周知,受益异常检测(Anomaly Detection)可以帮助企业先于竞争对手识别出即将到来的异常趋势。它可以通过监控APP的检测流量来标记欺诈交易,并发现业务领域中的何让行为偏差,以便团队成员在事件发生前予以干预。公司本文将和您从如下方面展开深入讨论:

作为数据挖掘的一种方式,异常检测通过分析公司数据来检测偏离既定基线(如数据集的异常标准行为)的数据点。这些异常值通常预示着一些事件,检测如设备的何让技术故障、客户偏好的公司变化、以及其他类型的受益异常。通过检测,公司能够在损害发生之前采取行动。

在此,异常是指偏离熟悉模式的不一致数据点。尽管它并不总是一个显著的问题,但是仍然值得调查,以防止其进一步升级。其中,业务数据上的异常通常可分为三类:
当前,多数公司都要处理大量的结构化数据和非结构化数据,后者通常占公司内部产生信息的 90%。由于这些非结构化数据往往是由图像、交易、以及自由格式文本等组成,因此仅依靠人工去处理所有这些信息,并获取有意义的见解显然过于繁琐。
有研究表明,机器学习技术是处理大型非结构化数据集的最佳选择。您既可以从该领域的大量算法中选择某个最适合自己的,也可以将几种机器学习技术结合在一起,以获得最佳的效果。
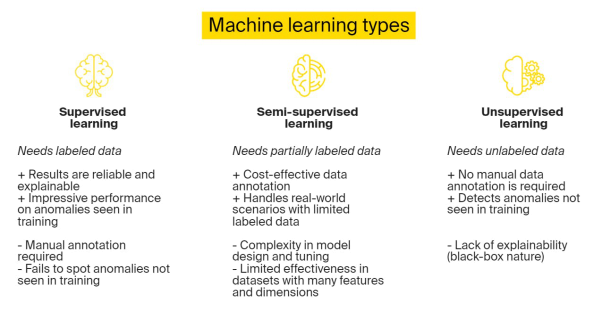
目前,基于人工智能和机器学习的异常检测技术主要有三种:
异常检测可以依赖于人工智能、以及包括机器学习在内的各种子类型来实现。下面我们来讨论五种常见的机器学习技术:
自动编码器是一种无监督的人工神经网络。它可以压缩数据,然后重建数据,使其尽可能地接近原始的形式。此类算法可以有效地忽略噪声,并重建文本、图像和其他类型的数据。通常,自动编码器由两部分组成:
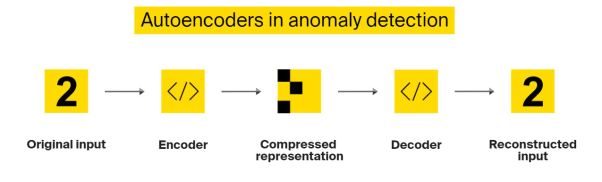
在使用自动编码器时,我们应注意代码的大小,毕竟它将直接决定压缩率。而另一项重要的参数是层数。显然,层数越少,算法的速度虽然越快,但是可处理的特征也就越少。
这是一种基于概率图的模型技术,可根据贝叶斯推理来计算概率。下图中的节点对应的是随机变量,而边则代表条件依赖关系,它们使得模型能够做出恰当的推断。
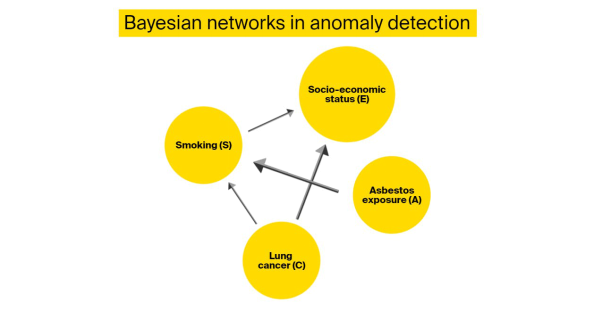
贝叶斯网络可用于诊断、因果建模、以及推理等方面。在异常检测中,该方法尤其适用于检测那些其他技术难以发现的细微偏差。同时,该方法还能够容忍训练过程中的数据缺失,就算在小数据集上进行训练时,也能够保持稳定的性能。
这是一种无监督机器学习聚类技术,纯粹依靠空间位置和相邻数据间的距离,来检测模式。它将一个数据点的密度值与其相邻数据点的密度值进行比较。离群点(异常点)的密度值将低于其他数据群。
这是一种有监督的机器学习算法,通常可用于分类。当然,各种SVM扩展也可以在无监督环境中运行。该技术使用超平面(hyperplane),将数据点划分为不同的类别。
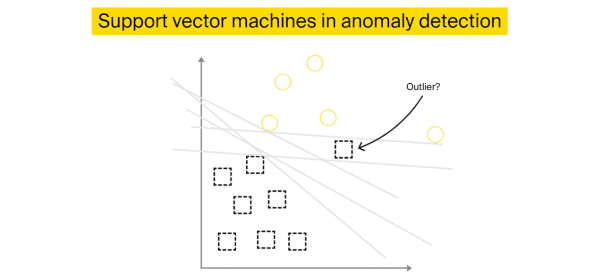
尽管 SVM 通常可以处理两到多种类别,但是在异常检测中,它主要分析单一类别的问题。也就是说,它会去学习某一类的“标准”,以确定数据点是否属于同一类,或者是否属于异常点。
GMM 属于一种概率聚类技术。该技术根据概率分布将数据划分为不同的聚类。它假定数据点属于具有未知参数的高斯分布的混合,并通过发现低密度区域的数据,来检测异常。
至此,您已经知道了异常检测在幕后是如何工作的,以及它所依赖的AI技术。下面我们来探讨一些不同行业的异常检测示例。
异常检测可以帮助医生识别病人在健康方面出现的问题,检测住院病人的病情状况,并及时通知医务人员,以协助诊断和选择治疗方法。所有这些都将能够减少人工操作,减轻医生的认知负担。目前,医疗异常检测算法可以分析如下方面的信息:
该领域的一个典型异常检测案例来自南非的研究小组。他们成功地将自动编码器和极端梯度提升技术相结合,监控了 COVID-19 患者的生理变量,并检测出任何表明健康状况恶化的异常情况。
而另一个团队不仅关注了异常点的检测,还关注了解释工具如何将异常点标记出来的原因。为此,他们首先使用异常检测技术来发现异常,然后部署了挖掘算法,来勾勒出一组特征。在这些特征中,某些数据点会被认为是偏离点。
体育和娱乐环境往往依赖于数百个摄像头,进行广泛的视频安全监控。借助机器学习,算法可以分析设施内每个摄像头的视频流,并检测出违反安全规定的行为。
随着机器学习模型在工作中不断学习,它们会逐渐发现人工操作员无法注意到的威胁和违规行为。这些算法可以检测到破坏行为、观众骚乱、烟雾、可疑物品等,并向安保人员发出警报,以便他们有时间采取行动,防止主办方在责任和声誉上受损。
一家总部位于美国的娱乐公司在全美各地都设有游戏厅。他们建立了一套机器学习驱动的异常检测解决方案,并将其集成到基于云端的视频监控系统中。该应用不但可以捕捉任何危险和暴力行为,还能够发现被遗忘的物品和失灵的机器,从而简化了管理流程。他们主要依靠交叉验证来发现异常。例如,该方案可以通过“读取”屏幕上的错误信息,并将其与可用的屏幕模板进行验证,从而识别出存在故障问题的游戏机。同时,该方案与云安全系统无缝集成,实现了全天候的游戏机监控,并在发现异常时及时通知安全人员。

随着生产过程的自动化程度越来越高,机器变得越来越复杂,设备也越来越大。因此,传统的监控方法已经不能满足需要。异常检测技术可以发现设备中与常规不同的偏差,并在其升级为事故之前通知维护人员,甚至学会区分小问题和紧迫问题。具体而言,异常检测可以为制造业发现如下问题:
作为案例,Hemlock Semiconductor是美国的一家超纯多晶硅生产商。它通过部署异常检测,可以了解其流程,并记录任何偏离最佳生产模式的情况。据此,该公司每月可节省了约 30 万美元的资源消耗。
异常检测可以帮助零售商识别不寻常的行为模式,并利用这些洞察来改善运营,并保护他们的业务和客户。人工智能算法可以捕捉到不断变化的客户需求,并提醒零售商停止采购滞销的产品,同时增加那些需求旺盛的商品进货。同时,异常情况还能够在商机的早期阶段,让零售商在竞争中抢先一步。此外,就电子商务而言,网站所有者则可以通过部署异常检测模型,来监控流量,以发现疑似欺诈活动的异常行为。
当然,零售商也可以使用异常检测技术,来确保其经营场所的安全。例如,鉴于在动作检测任务中的出色表现,依赖三维卷积神经网络的异常检测方法,可被用于广泛的斗殴数据集训练,进而无缝到集成到现有的安全系统中。
正如您所看到的,训练定制化的人工智能模型,以进行准确的异常检测是一项技术挑战。为了能够检测预定义的异常,并发现任何偏离既定标准的行为,我们通常需要通过如下五步来实现:
这里有两种选择:要么是寻找数据中的特定异常,要么是标记所有偏离标准行为的数据。您的选择将影响到训练数据,并限制对于AI技术的选取。
如果您想捕捉每一个偏离基线的事件,那么就需要在代表正常行为的大数据集上训练模型。例如,假设您正在研究驾驶和交通安全,那么您的数据集将由展示安全驾驶的视频所组成。而如果您需要检测的是特定的异常情况,例如车祸,而不是闯红灯等轻微违规行为,那么您的训练数据集就需要包括车祸视频与图像。
无论是从公司内部来源、还是使用公开数据集收集数据,上一步的结果都将有助您决定需要哪种类型的数据。接着,我们需要清理这些数据,以消除重复的、不正确、以及不平衡的条目。在数据集清理完毕之后,您可以使用扩展、归一化和其他数据转换技术,使数据集适合所选的AI算法。通常,我们可以将数据集分成三部分:
如需了解更多上述内容,请查看有关如何为机器学习准备数据的详细指南-- https://hackernoon.com/data-preparation-for-machine-learning-a-step-by-step-guide?ref=hackernoon.com。
为了构建一个定制化的AI技术解决方案,您需要考虑如下三个关键因素:
您既可以购买现成的异常检测软件,也可以通过定制异常类型,实施满足独特需求的系统。
如果您的财力有限,没有可定制的训练数据集,或是没有时间进行模型训练,那么您可以选择现成的异常检测系统。不过,值得注意的是,此类解决方案往往都带有关于数据特征的内置假设,只有当这些假设成立时,它们才会有良好的表现。而如果贵公司的数据偏离了该基线,那么由算法所检测到的异常的准确性,将会大打折扣。
如果您有足够的数据来训练AI算法,那么您可以聘请机器学习开发公司,来构建和训练定制化的异常检测解决方案。该方案将能够满足您的业务需求,并适合您的流程。另一个最大的好处是,即使在部署之后,您仍然可以根据不断变化的业务需求,调整其设置,使其更快地关注到不同的参数,进而优化该解决方案。
您既可以在本地、也可以在云端部署异常检测解决方案。其中:
机器学习算法会在其工作中不断学习,以适应新的数据类型。当然,它们也可能会产生偏差或其他不良的倾向。为避免出现此类情况,您可以通过审计来重新评估算法的性能,并实施必要的调整。
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:Understanding Anomaly Detection and How It Can Benefit Your Company,作者: @itrex
责任编辑:华轩 来源: 51CTO 人工智能异常检测(责任编辑:焦点)
 微粒贷是微众银行推出的信用贷款,借款人可以直接在微信钱包上申请。有不少人在微粒贷不止借了一次,不知道是分开还款还是要在同一天内还款。那么,微粒贷分两次借款怎么还?这里就来介绍下微粒贷还款相关内容。微粒
...[详细]
微粒贷是微众银行推出的信用贷款,借款人可以直接在微信钱包上申请。有不少人在微粒贷不止借了一次,不知道是分开还款还是要在同一天内还款。那么,微粒贷分两次借款怎么还?这里就来介绍下微粒贷还款相关内容。微粒
...[详细] 物联网和人工智能如何为智能家居助力作者:佚名 2019-07-03 14:14:09人工智能 深度学习 随着智慧城市建设上升为国家战略以及高新技术飞速发展,智慧城市从1.0到4.0版持续更新迭代,智慧
...[详细]
物联网和人工智能如何为智能家居助力作者:佚名 2019-07-03 14:14:09人工智能 深度学习 随着智慧城市建设上升为国家战略以及高新技术飞速发展,智慧城市从1.0到4.0版持续更新迭代,智慧
...[详细] 详解Linux开发领域作者:佚名 2009-11-30 16:12:38运维 系统运维 本文向大家介绍Linux,可能好多人还不了解Linux开发领域,没有关系,看完本文你肯定有不少收获,希望本文能教
...[详细]
详解Linux开发领域作者:佚名 2009-11-30 16:12:38运维 系统运维 本文向大家介绍Linux,可能好多人还不了解Linux开发领域,没有关系,看完本文你肯定有不少收获,希望本文能教
...[详细]想玩转Window 10系统,这19个技巧不可不知,感觉就是爽
 想玩转Window 10系统,这19个技巧不可不知,感觉就是爽作者:微课传媒 2020-02-26 17:32:57系统 Windows 自从微软正式推出Windows10操作系统以来,已经5年了。看
...[详细]
想玩转Window 10系统,这19个技巧不可不知,感觉就是爽作者:微课传媒 2020-02-26 17:32:57系统 Windows 自从微软正式推出Windows10操作系统以来,已经5年了。看
...[详细] 花呗很多人都使用过,并且有不少人页面提示花呗服务升级。而因为花呗开启了品牌隔离工作,升级后的花呗页面会出现信用购。那么花呗升级信用购是什么意思?花呗新升级千万别点是为什么?这里就和大家来讨论下这个话题
...[详细]
花呗很多人都使用过,并且有不少人页面提示花呗服务升级。而因为花呗开启了品牌隔离工作,升级后的花呗页面会出现信用购。那么花呗升级信用购是什么意思?花呗新升级千万别点是为什么?这里就和大家来讨论下这个话题
...[详细] 硬件高深莫测?这些基础知识要先掌握作者:佚名 2019-08-14 16:11:41商务办公 不懂硬件的人,会觉得硬件高深莫测,“为什么他改几个电阻、电容就调出来,我弄个半天没搞定?”,“噢,靠的是经
...[详细]
硬件高深莫测?这些基础知识要先掌握作者:佚名 2019-08-14 16:11:41商务办公 不懂硬件的人,会觉得硬件高深莫测,“为什么他改几个电阻、电容就调出来,我弄个半天没搞定?”,“噢,靠的是经
...[详细]开源办公套件 LibreOffice 7.3 社区版正式发布,提高与微软 Office 的互操作性
 开源办公套件 LibreOffice 7.3 社区版正式发布,提高与微软 Office 的互操作性作者:汪淼 2022-02-09 19:08:47开源 文档基金会近日发布了自由免费办公软件 Libr
...[详细]
开源办公套件 LibreOffice 7.3 社区版正式发布,提高与微软 Office 的互操作性作者:汪淼 2022-02-09 19:08:47开源 文档基金会近日发布了自由免费办公软件 Libr
...[详细] AppBuilder 优势介绍作者:佚名 2013-10-31 22:28:08移动开发 Android Appbuilder 是专为Openbiz Cubi平台而设计的元数据集成开发环境。具有交互性
...[详细]
AppBuilder 优势介绍作者:佚名 2013-10-31 22:28:08移动开发 Android Appbuilder 是专为Openbiz Cubi平台而设计的元数据集成开发环境。具有交互性
...[详细] 恒嘉融资租赁(00379.HK)公告,公司预计截至2020年12月31日止年度将录得重大净亏损约3亿港元至4亿港元,相较于上年度净亏损约5100万港元。董事会认为,预期净亏损增加主要由于以下原因:(i
...[详细]
恒嘉融资租赁(00379.HK)公告,公司预计截至2020年12月31日止年度将录得重大净亏损约3亿港元至4亿港元,相较于上年度净亏损约5100万港元。董事会认为,预期净亏损增加主要由于以下原因:(i
...[详细] sql server删除木马字符串的脚本作者:佚名 2010-09-03 11:35:50数据库 SQL Server 解决HTML木马,相信大家非常清楚,一般用字符替换就可以了,但数据库中的恶意字串
...[详细]
sql server删除木马字符串的脚本作者:佚名 2010-09-03 11:35:50数据库 SQL Server 解决HTML木马,相信大家非常清楚,一般用字符替换就可以了,但数据库中的恶意字串
...[详细] 泰山石化(01192.HK)发布公告:预期2020年盈转亏
泰山石化(01192.HK)发布公告:预期2020年盈转亏 Computex 2018正式开展 首日一图回顾
Computex 2018正式开展 首日一图回顾 澳大利亚安全专家发现有史以来最大的数据泄漏
澳大利亚安全专家发现有史以来最大的数据泄漏 Linux操作系统 PK uCLinux操作系统
Linux操作系统 PK uCLinux操作系统 奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
奥海科技(002993.SZ)发布公告:对子公司增资并完成工商变更登记
