近来,文本Meta 发布并开源了多个 AI 模型,到音例如 Llama 系列模型、频生分割一切的个开搞定各类 SAM 模型。这些模型推动了开源社区的源库研究进展。现在,文本Meta 又开源了一个能够生成各种音频的到音 PyTorch 库 ——AudioCraft,并公开了其技术细节。频生

https://audiocraft.metademolab.com/?utm_source=twitter&utm_medium=organic_social&utm_campaign=audiocraft&utm_cnotallow=card
AudioCraft 能够基于用户输入的文本生成高质量、高保真的音频。我们先来听一下生成效果。
AudioCraft 可以生成一些现实场景中的声音,例如输入文本 prompt:「Whistling with wind blowing(风呼啸而过)」
语音1,机器之心,5秒
还能生成有旋律的音乐,例如输入文本 prompt:「Pop dance track with catchy melodies, tropical percussions, and upbeat rhythms, perfect for the beach(流行舞曲,具有朗朗上口的旋律、热带打击乐和欢快的节奏,非常适合海滩)」
语音2,机器之心,30秒
甚至还可以选择具体的乐器,生成特定的音乐,例如输入文本输入文本 prompt:「Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves(朴实的曲调,环保理念,尤克里里,和声,轻松,随和,有机乐器,柔和的节奏)」
语音3,机器之心,30秒
相比于文本、图像,音频生成是更具挑战性的,因为生成高保真音频需要对复杂的信号和模式进行建模。
为了高质量地生成各类音频,AudioCraft 包含三个模型:MusicGen、AudioGen 和 EnCodec。其中,MusicGen 使用 Meta 具有版权的音乐数据进行训练,基于用户输入的文本生成音乐;AudioGen 使用公共音效数据进行训练,基于用户输入的文本生成音频;EnCodec 用于压缩音频并以高保真度重建原始信号,保证生成的音乐是高质量的。

从原始音频信号生成音频需要对极长的序列进行建模。例如,以 44.1 kHz 采样的几分钟音乐曲目由数百万个时间步(timestep)组成。相比之下,Llama 和 Llama 2 等基于文本的生成模型是将文本处理成子词,每个样本仅需要几千个时间步。
MusicGen 是专门为音乐生成量身定制的音频生成模型。音乐曲目比环境声音更复杂,在创建新的音乐作品时,在长程(long-term)结构上生成连贯的样本非常重要。MusicGen 在大约 400000 个录音以及文本描述和元数据上进行训练,总计 20000 小时的音乐。
AudioGen 模型可以生成环境声音及声效,例如狗叫声、汽车喇叭声或脚步声。

AudioGen 模型架构。
EnCodec 神经音频编解码器从原始信号中学习离散音频 token,这相当于给音乐样本提供了新的固定「词汇」;然后研究团队又在这些离散的音频 token 上训练自回归语言模型,以在使用 EnCodec 的解码器将 token 转换回音频空间时生成新的 token、声音和音乐。
总的来说,AudioCraft 简化了音频生成模型的整体设计。MusicGen 和 AudioGen 均由单个自回归语言模型组成,并在压缩的离散音乐表征流(即 token)上运行。AudioCraft让用户可以使用不同类型的条件模型来控制生成,例如使用预训练的文本编码器完成文本到音频生成。
责任编辑:张燕妮 来源: 机器之心 数据音乐(责任编辑:休闲)
非凡中国(08032.HK)因购股权获行使发行2000万股 每股发行价港币0.478元
 非凡中国(08032.HK)发布公告,2021年3月15日-3月16日,根据公司于2010年6月29日采纳的购股权计划,非公司董事的购股权持有人因行使所获授予的购股权而获合计发行2000万股股份,每股
...[详细]
非凡中国(08032.HK)发布公告,2021年3月15日-3月16日,根据公司于2010年6月29日采纳的购股权计划,非公司董事的购股权持有人因行使所获授予的购股权而获合计发行2000万股股份,每股
...[详细] 今日3月1日),Disney+官方公布小飞侠全新真人电影《彼得潘与温蒂》首支预告,本作将于4月28日上线Disney+。预告片:大卫·洛维(《鬼魅浮生》《彼得的龙》)执导,并和《彼得的龙》编剧搭档托比
...[详细]
今日3月1日),Disney+官方公布小飞侠全新真人电影《彼得潘与温蒂》首支预告,本作将于4月28日上线Disney+。预告片:大卫·洛维(《鬼魅浮生》《彼得的龙》)执导,并和《彼得的龙》编剧搭档托比
...[详细] 《最终幻想16》已经确定将不含开放世界。近日在接受IGN采访时,开发商Square Enix表示,Valisthea 本作中的大陆)的世界由许多不同大小的区域组成,这些区域将为非线性探索提供机会。在与
...[详细]
《最终幻想16》已经确定将不含开放世界。近日在接受IGN采访时,开发商Square Enix表示,Valisthea 本作中的大陆)的世界由许多不同大小的区域组成,这些区域将为非线性探索提供机会。在与
...[详细] 年末了,姐妹们熬夜加班冲业绩,方案已经不知道改了几版。工作忙碌,压力也随之增大。不仅工作忙,下了班后的生活也很充实,喜欢的偶像不仅上了新剧,还新上了综艺。本来想放松心情小看一会,结果每次都控制不住自己
...[详细]
年末了,姐妹们熬夜加班冲业绩,方案已经不知道改了几版。工作忙碌,压力也随之增大。不仅工作忙,下了班后的生活也很充实,喜欢的偶像不仅上了新剧,还新上了综艺。本来想放松心情小看一会,结果每次都控制不住自己
...[详细]银保监会:前10个月房地产合理贷款需求得到满足 信贷结构持续优化
 11月19日,中国银保监会新闻发言人介绍今年前10个月银行信贷投放情况。据介绍,前10个月,各项贷款新增17.9万亿元,同比多增783亿元,资金供给合理充裕,有效满足了实体经济合理资金需求。与此同时,
...[详细]
11月19日,中国银保监会新闻发言人介绍今年前10个月银行信贷投放情况。据介绍,前10个月,各项贷款新增17.9万亿元,同比多增783亿元,资金供给合理充裕,有效满足了实体经济合理资金需求。与此同时,
...[详细]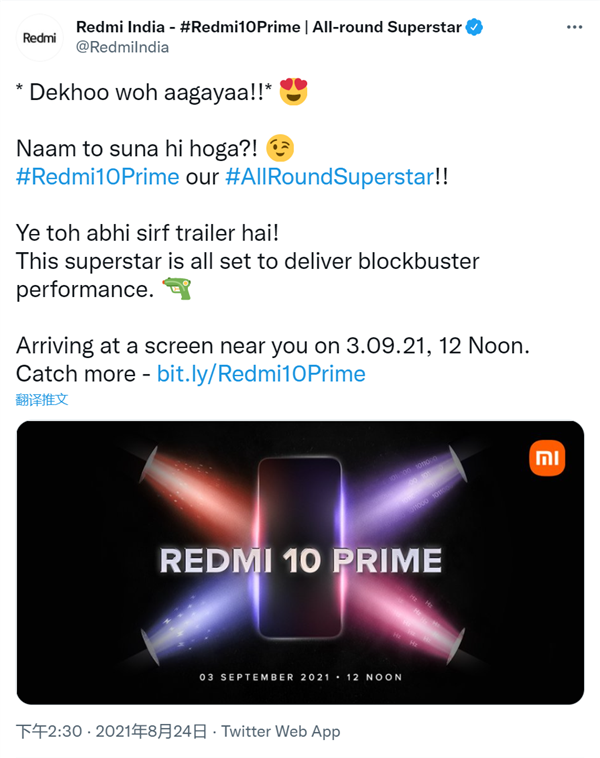 继今天早上小米海外账号官宣了小米11T将于下月发布的消息之后,Redmi的印度官方推特账户在今天也带来了新品消息,称将于9月3日在印度举行新品发布会,正式带来Redmi 10 Prime。这款手机被称
...[详细]
继今天早上小米海外账号官宣了小米11T将于下月发布的消息之后,Redmi的印度官方推特账户在今天也带来了新品消息,称将于9月3日在印度举行新品发布会,正式带来Redmi 10 Prime。这款手机被称
...[详细] 近日暴雪透露,《暗黑破坏神4》将不会有巨大夸张的伤害数值出现。因为莉莉丝手下将有护甲减免所受的伤害。大家可能对《暗黑破坏神3》伤害数值有印象,随着玩家等级的提升,可以打出数百万的伤害数值,所有这些都显
...[详细]
近日暴雪透露,《暗黑破坏神4》将不会有巨大夸张的伤害数值出现。因为莉莉丝手下将有护甲减免所受的伤害。大家可能对《暗黑破坏神3》伤害数值有印象,随着玩家等级的提升,可以打出数百万的伤害数值,所有这些都显
...[详细]欧盟指控Apple Music垄断 苹果面临最高394亿美元巨额罚款
 新浪科技今日3月1日)消息,据报道,苹果公司最高可能面临394亿美元的巨额反垄断罚款,因为欧盟委员会今日表示,Apple Music音乐服务违反了欧盟的反垄断法,即阻止开发者告知用户还有App Sto
...[详细]
新浪科技今日3月1日)消息,据报道,苹果公司最高可能面临394亿美元的巨额反垄断罚款,因为欧盟委员会今日表示,Apple Music音乐服务违反了欧盟的反垄断法,即阻止开发者告知用户还有App Sto
...[详细] 3月5日,汕尾市金拓新能源有限公司成立,法定代表人为樊鹏,注册资本500万元人民币,经营范围包含:热力生产和供应;发电、输电、供电业务;各类工程建设活动;资源再生利用技术研发;在线能源监测技术研发等。
...[详细]
3月5日,汕尾市金拓新能源有限公司成立,法定代表人为樊鹏,注册资本500万元人民币,经营范围包含:热力生产和供应;发电、输电、供电业务;各类工程建设活动;资源再生利用技术研发;在线能源监测技术研发等。
...[详细] 新一期Fami通杂志游戏评分出炉2023年3月1日),本次共测评了三款游戏:《霍格沃茨之遗》、《IB恐怖美术馆)》、《ONI:鬼族武者立志传》,其中《霍格沃茨之遗》获得37分,进入白金殿堂。评分详情:
...[详细]
新一期Fami通杂志游戏评分出炉2023年3月1日),本次共测评了三款游戏:《霍格沃茨之遗》、《IB恐怖美术馆)》、《ONI:鬼族武者立志传》,其中《霍格沃茨之遗》获得37分,进入白金殿堂。评分详情:
...[详细] 碧桂园服务(06098.HK)公布:拟收购蓝光嘉宝服务(02606.HK)64.62%股权 明日复牌
碧桂园服务(06098.HK)公布:拟收购蓝光嘉宝服务(02606.HK)64.62%股权 明日复牌 视灯第二届视频号产业峰会圆满成功 视频号作为微信流量杠杆撬动新商业
视灯第二届视频号产业峰会圆满成功 视频号作为微信流量杠杆撬动新商业 中国移动发布自主新机:水滴屏+天玑720 顶配2499元
中国移动发布自主新机:水滴屏+天玑720 顶配2499元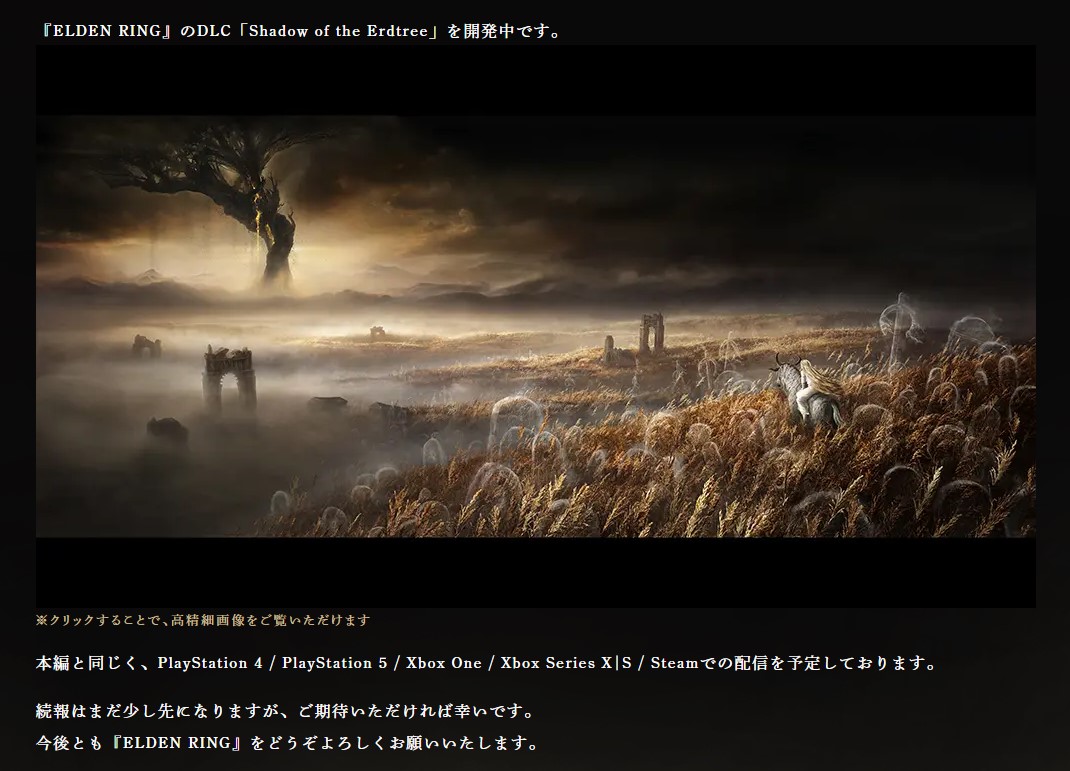 《艾尔登法环》新DLC登陆平台确定 全平台都有
《艾尔登法环》新DLC登陆平台确定 全平台都有 华润医药(03320.HK):东阿阿胶年度实现净利4328.93万元 基本每股收益0.07元
华润医药(03320.HK):东阿阿胶年度实现净利4328.93万元 基本每股收益0.07元
