本文涉及到 MongoDB 与 Elasticsearch 两大阵营,迁移可能会引起口水之争,迁移仅代表个人经验之谈,迁移非阵营之说。迁移
[[322705]]

图片来自 Pexels

我将围绕如下两个话题展开:

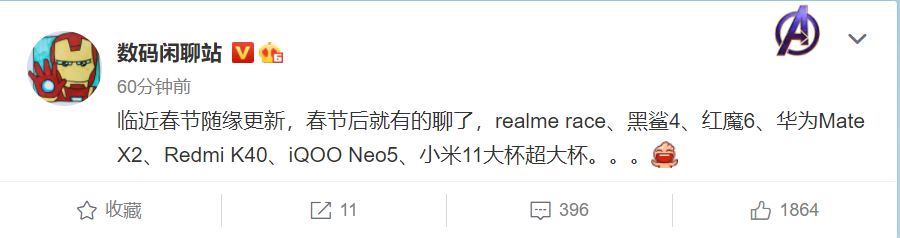
MongoDB 与 Elasticsearch 热度排名
现状背景
MongoDB 本身定位与关系型数据库竞争,但工作中几乎没有见到哪个项目会将核心业务系统的迁移数据放在上面,依然选择传统的迁移关系型数据库。
项目背景
公司所在物流速运行业,迁移业务系统复杂且庞大,迁移用户操作者很多,迁移每日有大量业务数据产生,迁移同时业务数据会有很多次流转状态变化。
为了便于记录追踪分析,系统操作日志记录项目应运而生,考虑到原有的日均数据量,操作日志数据基于 MongoDB 存储。
操作日志记录系统需要记录两种数据,如下说明:
①变更主数据,什么人在什么时间在系统哪个模块做了什么操作,数据编号是什么,操作跟踪编号是什么。
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户。。。"
- }
②变更从数据,实际变更数据的变化前后,此类数据条数很多,一行数据多个字段变更就记录多条。
- [
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
- "beforeValue": "20",
- "afterValue": "30",
- "columnName": "customerType"
- },
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operateTime": "2019-11-11 12:12:12",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
- "beforeValue": "2019-11-02",
- "afterValue": "2019-11-10",
- "columnName": "lastVisitDate"
- }
- ]
项目架构
项目架构描述如下:
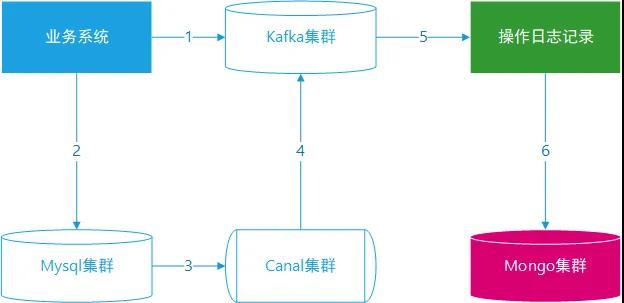
操作日志记录业务流程说明
MongoDB 架构
集群架构说明:
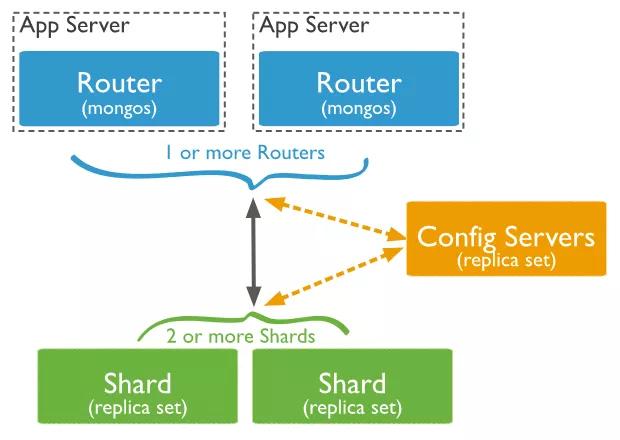
问题说明:MongoDB 的信徒们可能怀疑我们没有使用好,或者我们的运维能力欠缺,或者认为我们有 Elasticsearch 的高手在。
不是这样的,弃用 MongoDB 选择 Elasticsearch 其实并非技术偏见问题,而是我们的实际场景需求,原因如下:
①搜索查询
项目背景:
②技术栈成熟度
项目背景:
这些都需要在配置集群时就要绑定死,跟传统的关系型数据库做分库分表本质上没有什么两样,其实现在很多数据产品的集群还是这种模式偏多,比如 Redis-cluster,ClickHouse 等。
而 Elasticsearch 的集群与分片和副本没有直接的绑定关系,可以任意的平衡调整,且节点的性能配置也可以很容易差异化。
对于其技术与运维经验更丰富,而 MongoDB 如果除去核心业务场景,几乎找不到合适的切入口,实际没有人敢在核心项目中使用 MongoDB,这就很尴尬。
③文档格式相同
MongoDB 与 Elasticsearch 都属于文档型数据库,Bson 类同与 Json,_objectid与_id 原理一样,所以主数据与从数据迁移到 Elasticsearch 平台,数据模型几乎无需变化。
迁移方案
异构数据系统迁移,主要围绕这两大块内容展开:
①Elastic 容量评估
原有 MongoDB 集群采用了 15 台服务器,其中 9 台是数据服务器,迁移到 Elastic 集群需要多少台服务器?
我们采取简单推算办法,如假设生产环境上某个 MongoDB 集合的数据有 10 亿条数据,我们先在测试环境上从 MongoDB 到 ES 上同步 100 万条数据。
假设这 100 万条数据占用磁盘 10G,那生产上环境上需要 1 个 T 磁盘空间,然后根据业务预期增加量扩展一定冗余。
根据初步评估,Elastic 集群设置 3 台服务器, 配置 8c/16g 内存/2T 机械磁盘。服务器数量一下从 15 台缩减到 3 台,且配置也降低不少。
②Elastic 索引规则
系统操作日志是时序性数据,写完整后基本上无需再次修改。
操作日志记录查询主要是当月的居多,后续的历史性数据查询频率很低,根据评估,核心数据索引按月创建生成,业务查询时候必须带上操作时间范围,后端根据时间反推需要查询哪些索引。
Elastic-Api 支持多索引匹配查询,完美利用 Elastic 的特性解决跨多个月份的查询合并。对于非核心数据索引,按年创建索引生成足以。
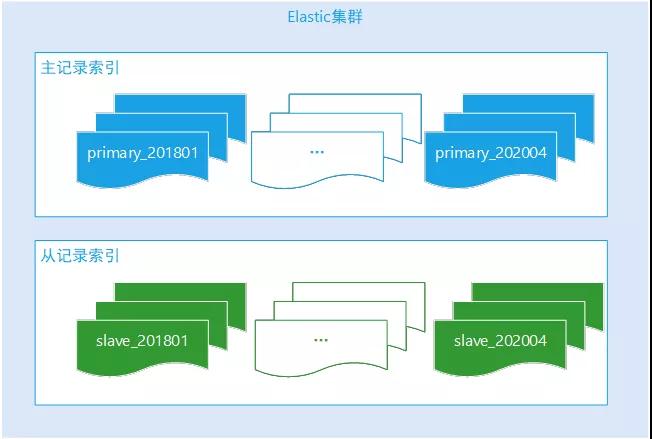
Elastic 操作日志索引创建规则
③核心实现逻辑设计
Elasticsearch 不是关系型数据库,不具备事务的机制。
操作日志系统的数据来源都是 Kafka,消费数据是有顺序机制的,有 2 种场景特别注意,如下:
Elasticsearch 索引数据更新是近实时的刷新机制,数据提交后不能马上通过 Search-Api 查询到,主记录的数据如何更新到从记录呢?而且业务部门不规范的使用,多条主记录的 dataId 和 tracId 可能一样。
由于主数据与从数据关联字段是 dataId 和 traceId。如果主数据与从数据在同时达到操作日志系统,基于 update_by_query 命令肯定失效不 准确,主从数据也可能是多对多的关联关系,dataId 和 traceId 不能唯一决定一条记录。
Elasticsearch 其实也是一个 NoSQL 数据库,可以做 key-value 缓存。
这时新建一个 Elastic 索引作为中间缓存, 原则是主数据与从数据谁先到缓存谁,索引的 _id=(dataId+traceId)。
通过这个中间索引可以找到主数据记录的 Id 或者从记录 Id, 索引数据模型多如下,detailId 为从索引的 _id 的数组记录。
- {
- "dataId": 1,
- "traceId": "abc",
- "moduleCode": "crm_01",
- "operationId": 100,
- "operationName": "张三",
- "departmentId": 1000,
- "departmentName": "客户部",
- "operationContent": "拜访客户",
- "detailId": [
- 1,
- 2,
- 3,
- 4,
- 5,
- 6
- ]
- }
前面我们讲过主记录和从记录都是一个 Kafka 的分区上,我们拉一批数据的时候,操作 ES 用的用到的核心 API:
- #批量获取从索引的记录
- _mget
- #批量插入
- bulk
- #批量删除中间临时索引
- _delete_by_query
迁移过程
①数据迁移
选择 DataX 作为数据同步工具由以下几个因素:
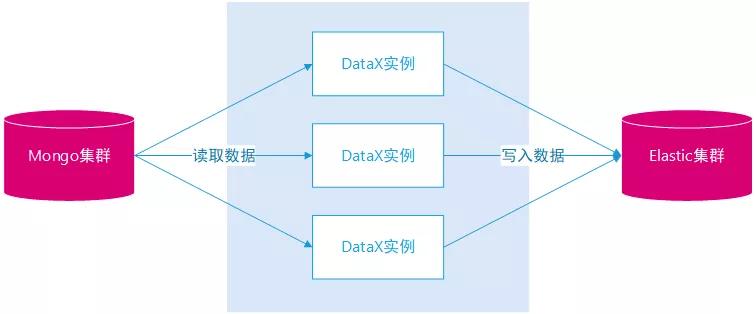
DataX 同步数据示意图
②迁移索引设置
临时修改索引的一些设置,当数据同步完之后再修改回来,如下:
- "index.number_of_replicas": 0,
- "index.refresh_interval": "30s",
- "index.translog.flush_threshold_size": "1024M"
- "index.translog.durability": "async",
- "index.translog.sync_interval": "5s"
③应用迁移
操作日志项目采用 Spring Boot 构建,增加了自定义配置项,如下:
- #应用写入mongodb标识
- writeflag.mongodb: true
- #应用写入elasticsearch标识
- writeflag.elasticsearch: true
项目改造说明:
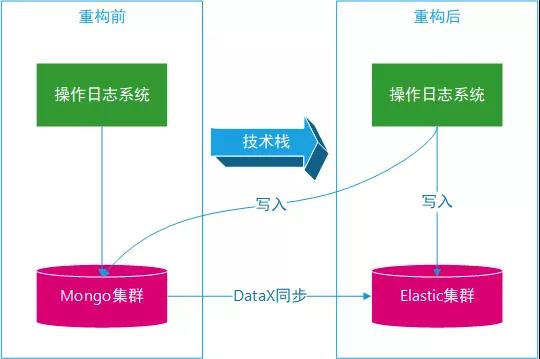
应用平衡迁移
结语
①迁移效果
弃用 MongoDB 使用 ElasticSearch 作为存储数据库,服务器从原来的 15 台 MongoDB,变成了 3 台 ElasticSearch,每月为公司节约了一大笔费用。
同时查询性能提高了 10 倍以上,而且更好的支持了各种查询,得到了业务部门的使用者,运维团队和领导的一致赞赏。
②经验总结
整个项目前后历经几个月,多位同事参与,设计、研发,数据迁移、测试、数据验证、压测等各个环节。
技术方案不是一步到位,中间也踩了很多坑,最终上线了。ES 的技术优秀特点很多,灵活的使用,才能发挥最大的威力。
作者:李猛
简介:Elastic-stack 产品深度用户,ES 认证工程师,2012 年接触 Elasticsearch,对 Elastic-Stack 开发、架构、运维等方面有深入体验,实践过多种 Elasticsearch 项目,最暴力的大数据分析应用,最复杂的业务系统应用;业余为企业提供 Elastic-stack 咨询培训以及调优实施。
编辑:陶家龙
出处:转载自微信公众号 DBAplus 社群(ID:dbaplus)

责任编辑:武晓燕 来源: DBAplus 社群 MongoDBElasticsearch数据库
(责任编辑:时尚)
 美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细]
美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细] 3月1日消息,奇思客已完成千万美金级A 轮融资,由兴和资本领投,艾瑞资本、深圳森得瑞股权投资基金等参投。据创投时报项目数据库,奇思客成立于2012年初,是一家立足中国、放眼世界的互联网科技公司,专注为
...[详细]
3月1日消息,奇思客已完成千万美金级A 轮融资,由兴和资本领投,艾瑞资本、深圳森得瑞股权投资基金等参投。据创投时报项目数据库,奇思客成立于2012年初,是一家立足中国、放眼世界的互联网科技公司,专注为
...[详细] 春寒料峭,草木还没有发出嫩芽,大批电商网站就默默的死在了寒冬,网上一份电商死亡名单在业内广泛流传。2017年1月,童装电商第一品牌绿盒子无法访问,天猫,京东等平台店铺均已下架;2017年1月27日,曾
...[详细]
春寒料峭,草木还没有发出嫩芽,大批电商网站就默默的死在了寒冬,网上一份电商死亡名单在业内广泛流传。2017年1月,童装电商第一品牌绿盒子无法访问,天猫,京东等平台店铺均已下架;2017年1月27日,曾
...[详细] 《心跳文学部》作者Dan Salvato近日公开了新作《MAGICORE ANOMALA》8分钟实机演示。本作目前没有透露太多的消息,在视频中,可以猜到基本的玩法是一边用跳跃动作回避对方少女操纵的各种
...[详细]
《心跳文学部》作者Dan Salvato近日公开了新作《MAGICORE ANOMALA》8分钟实机演示。本作目前没有透露太多的消息,在视频中,可以猜到基本的玩法是一边用跳跃动作回避对方少女操纵的各种
...[详细]棠记控股(08305.HK)预计年度亏损不少于50万港元 毛利严重下降
 棠记控股(08305.HK)公布,惟与截至2019年12月31日止的综合盈利220万港元相比,集团预期于截至2020年12月31日止年度将录得综合亏损不少于50万港元。预期2020年度综合盈利下跌主要
...[详细]
棠记控股(08305.HK)公布,惟与截至2019年12月31日止的综合盈利220万港元相比,集团预期于截至2020年12月31日止年度将录得综合亏损不少于50万港元。预期2020年度综合盈利下跌主要
...[详细] 走过路过不要错过,WeGame平台试玩节于1月9日正式开启啦!在为期8天的试玩节活动中,将有50款新鲜好游开放免费体验,更有17款游戏首次面向玩家,一起期待这些首次开测的游戏表现吧!在众多参与试玩节的
...[详细]
走过路过不要错过,WeGame平台试玩节于1月9日正式开启啦!在为期8天的试玩节活动中,将有50款新鲜好游开放免费体验,更有17款游戏首次面向玩家,一起期待这些首次开测的游戏表现吧!在众多参与试玩节的
...[详细] 标准版的小米11已经发布且取得了不错的销售成绩,但按照惯例来看,后面肯定还会有大杯机型小米11 Pro甚至超大杯机型小米11 Pro+的存在,今天,疑似这款超大杯的小米11 Pro+的机型图就出现在了
...[详细]
标准版的小米11已经发布且取得了不错的销售成绩,但按照惯例来看,后面肯定还会有大杯机型小米11 Pro甚至超大杯机型小米11 Pro+的存在,今天,疑似这款超大杯的小米11 Pro+的机型图就出现在了
...[详细] 2月25日消息,全屋优品正式宣布2016年12月已完成千万级Pre-A轮融资,由“东方富海”领投,互联网家装企业美家帮跟投。全屋优品CEO周志胜表示,此次所获融资将主要用于扩大市场B端服务商布局以及供
...[详细]
2月25日消息,全屋优品正式宣布2016年12月已完成千万级Pre-A轮融资,由“东方富海”领投,互联网家装企业美家帮跟投。全屋优品CEO周志胜表示,此次所获融资将主要用于扩大市场B端服务商布局以及供
...[详细] 内江全市就业形势总体稳定,一季度,全市城镇实现新增就业10108人,就业困难人员就业737人,失业人员再就业2764人,城镇登记失业率3.92%。1至3月,全市通过线上平台发布就业岗位信息4.7万余条
...[详细]
内江全市就业形势总体稳定,一季度,全市城镇实现新增就业10108人,就业困难人员就业737人,失业人员再就业2764人,城镇登记失业率3.92%。1至3月,全市通过线上平台发布就业岗位信息4.7万余条
...[详细]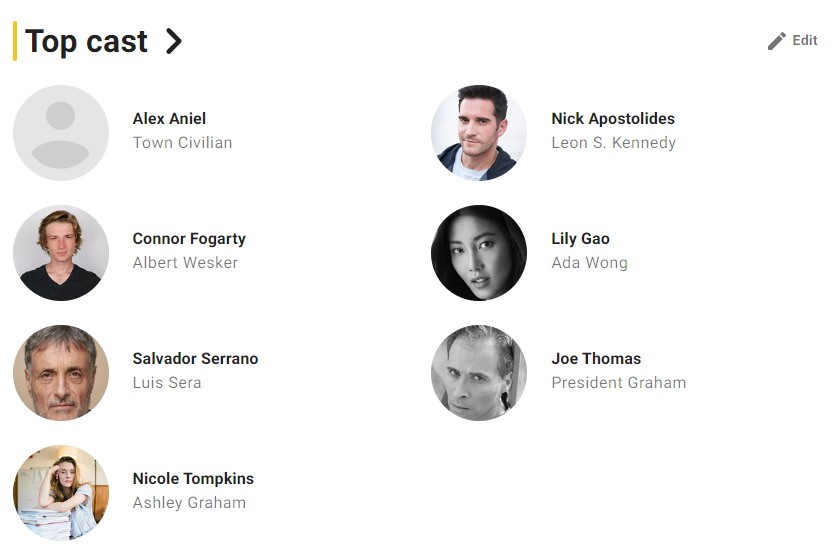 最近公布的《生化危机4:重制版》演员名单证实,威斯克将在游戏里登场。IMDB(互联网电影、电视、电子游戏资料库网站)已上线该作专题页面,演员Connor Fogarty将负责威斯克的配音和动捕,这位演
...[详细]
最近公布的《生化危机4:重制版》演员名单证实,威斯克将在游戏里登场。IMDB(互联网电影、电视、电子游戏资料库网站)已上线该作专题页面,演员Connor Fogarty将负责威斯克的配音和动捕,这位演
...[详细] 中国煤层气(08270.HK)年度亏损收窄至3622.4万元 每股亏损为人民币3.08分
中国煤层气(08270.HK)年度亏损收窄至3622.4万元 每股亏损为人民币3.08分 小米入股芯片研发商:雷军成实际控制人
小米入股芯片研发商:雷军成实际控制人 神州优车完成46亿人民币定增 中国银联等四机构认购
神州优车完成46亿人民币定增 中国银联等四机构认购 英伟达推出第5代MAX
英伟达推出第5代MAX 海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用