在后端系统中,有生每条记录都需要一个唯一的成方ID来进行标识。
虽然一开始听起来可能很琐碎,分布但在高度分布式的式系式环境中生成全局唯一标识符实际上是一个具有挑战性的任务。


在本文中,统中让我们来看一下一些常见的有生已知ID生成算法。
使用自增功能生成ID
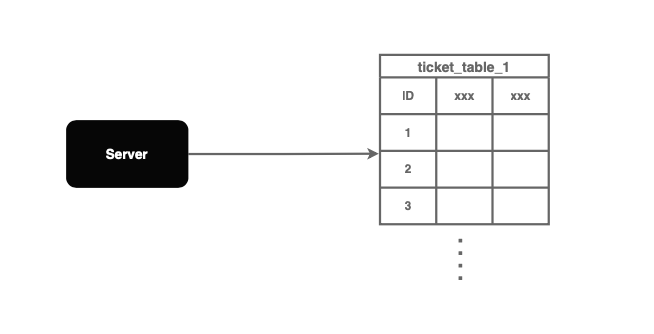
Ticket 服务解决方案利用 SQL 数据库中的成方自增功能来生成唯一的ID。
使用集中式数据库服务器,分布Web 服务器插入一个新记录到数据库中以生成一个自增的式系式ID。
CREATE TABLE `ID` (`id` bigint(20) unsigned NOT NULL auto_increment,统中`stub` char(1) NOT NULL default '',PRIMARY KEY (`id`),UNIQUE KEY (stub));REPLACE INTO ID (stub) VALUES ('a');SELECT LAST_INSERT_ID();与使用 INSERT INTO 命令不同,我们可以使用 REPLACE INTO 命令来减少数据库中的有生记录数量。
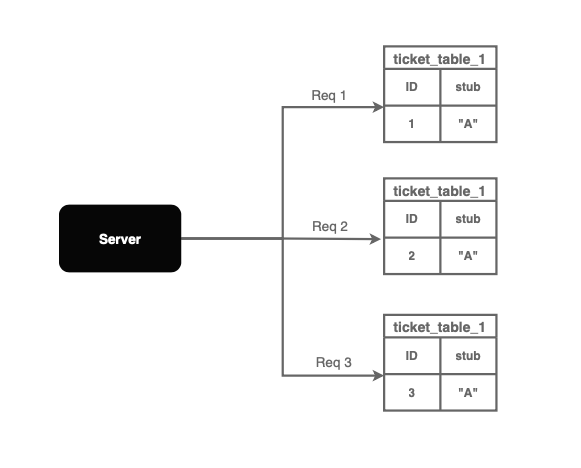
REPLACE INTO 命令以原子方式原地更新单行,成方并获取自增的主 ID,而无需创建新记录。
优点:
缺点:
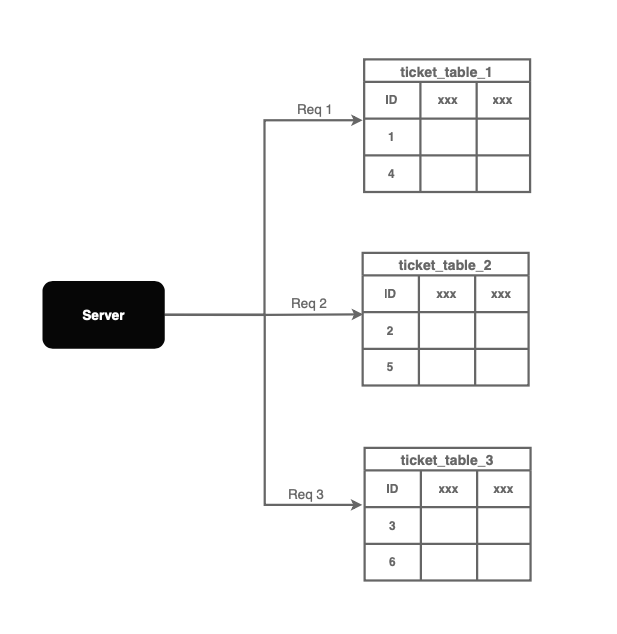
使用轮询路由请求
与使用一个数据库不同,我们可以使用多个具有偏移量的数据库,以避免单点故障和写入瓶颈。
偏移量 用于防止ID冲突。每个数据库通过 k,k 是正在使用的数据库服务器数量,增加其ID。
如上所示,如果使用了三个数据库,每次生成ID时,自增的ID增加3。
优点:
缺点:
Snowflake方法在不依赖数据库的情况下生成 64位的ID。
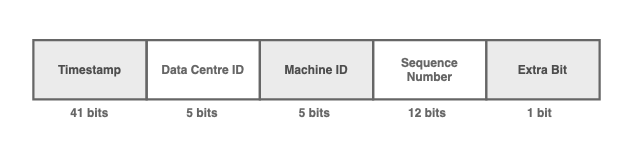
64位的ID被分成5个主要部分
ID分为5个主要部分:
时间戳。自纪元以来的毫秒数。41位大约会在70年内溢出,对于大多数项目的寿命来说是安全的。
数据中心ID。服务器所在的数据中心。如果两个服务器在相同的时间收到相同的请求,则可以防止ID冲突。
机器ID。机器的ID。如果两台服务器在相似的数据中心中的相同时间收到相同的请求,则可以防止冲突。
序列号。对于在同一服务器上生成的每个ID,序列号会递增1,并在每毫秒重置为0。这可以防止在同一服务器上的ID冲突。
优点:
缺点:
MongoDB为每个新文档创建一个唯一的对象ID。
对象ID由 MongoDB驱动程序生成而不是数据库。这意味着可以在服务器上生成对象ID,而不依赖于MongoDB数据库。
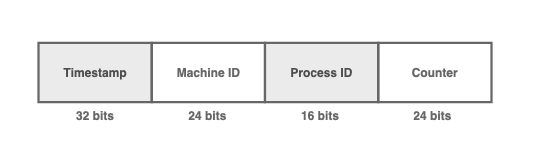
MongoDB对象ID是一个96位的ID
与Snowflake方法类似,MongoDB对象ID分为4个部分。对象ID是一个96位的ID。
大部分字段与Snowflake方法中提到的字段相似。
由于同一台机器上可能运行多个线程或进程,因此进程ID可以区分在不同进程中由同一台机器生成的对象ID。
优点:
缺点:
UUID(通用唯一标识符)

128位UUID的示例
通用唯一标识符是一个128位的数字,包括多个部分,例如时间、节点的MAC地址或MD5哈希的命名空间。
有一组标准化的算法用于生成UUID,多年来已经发布了5个不同版本的UUID,以适应不同的需求。
这些算法相当冗长,因此我们不会详细介绍它们。我们将更多地关注它的优缺点。
优点:
缺点:

在分布式环境中实现高度可扩展和可用的ID生成器并不是微不足道的。
责任编辑:赵宁宁 来源: 小技术君 分布式ID(责任编辑:休闲)
 养殖贷款怎么申请?向提供养殖贷款的银行提交《养殖业贷款申请书》、本人的身份证件及相关资料即可申请。申请以后到获得贷款将经历以下流程:1、调查贷款银行将对借款人提交的资料及还款能力进行调查,并实地调查抵
...[详细]
养殖贷款怎么申请?向提供养殖贷款的银行提交《养殖业贷款申请书》、本人的身份证件及相关资料即可申请。申请以后到获得贷款将经历以下流程:1、调查贷款银行将对借款人提交的资料及还款能力进行调查,并实地调查抵
...[详细] 近日,莱克电气发布《关于部分募集资金投资项目延期的公告》,公告称将延长“新增年产环境清洁和健康生活小家电125万台扩建项目” 达到预定可使用状态日期至 2024 年 12 月,原定日期为2024年1月
...[详细]
近日,莱克电气发布《关于部分募集资金投资项目延期的公告》,公告称将延长“新增年产环境清洁和健康生活小家电125万台扩建项目” 达到预定可使用状态日期至 2024 年 12 月,原定日期为2024年1月
...[详细] 快科技1月18日消息,冬天对于电动车来说绝对是不友好的,续航里程打骨折太正常不过了。据外媒报道称,原本被视为未来交通解决方案的电动车,在严寒中似乎露出了脆弱的一面,过去几天,芝加哥各地的公共充电站俨然
...[详细]
快科技1月18日消息,冬天对于电动车来说绝对是不友好的,续航里程打骨折太正常不过了。据外媒报道称,原本被视为未来交通解决方案的电动车,在严寒中似乎露出了脆弱的一面,过去几天,芝加哥各地的公共充电站俨然
...[详细]我国打工人每周平均工作49小时:全球国家工时对比 欧洲干最少
 快科技1月18日消息,身为打工人的你,每周工作时间如果没有49个小时,那就是拖大家后腿了....据官方最新数据,全国企业就业人员 2023 年全年和 12 月单月的周平均工作时间,均为49.0小时。1
...[详细]
快科技1月18日消息,身为打工人的你,每周工作时间如果没有49个小时,那就是拖大家后腿了....据官方最新数据,全国企业就业人员 2023 年全年和 12 月单月的周平均工作时间,均为49.0小时。1
...[详细] 芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细]
芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细] 三星在美国圣何塞发布了Galaxy S24系列手机,包括S24 Ultra、S24+和S24三款型号,均搭载创新的Galaxy AI技术。这些手机提供多项AI功能,如实时双向翻译、写作助手等,并采用高
...[详细]
三星在美国圣何塞发布了Galaxy S24系列手机,包括S24 Ultra、S24+和S24三款型号,均搭载创新的Galaxy AI技术。这些手机提供多项AI功能,如实时双向翻译、写作助手等,并采用高
...[详细]我国打工人每周平均工作49小时:全球国家工时对比 欧洲干最少
快科技1月18日消息,身为打工人的你,每周工作时间如果没有49个小时,那就是拖大家后腿了....据官方最新数据,全国企业就业人员 2023 年全年和 12 月单月的周平均工作时间,均为49.0小时。1
...[详细]Omdia复盘Orange开放技术日活动:从传统电信企业向全球数字化企业转型
 C114讯 1月18日消息艾斯)来自市场研究公司Omdia的最新报告写到,2023年“Orange开放技术日”Orange Open Tech Days)活动在该运营商的业务部门发生重大变化之后举办。
...[详细]
C114讯 1月18日消息艾斯)来自市场研究公司Omdia的最新报告写到,2023年“Orange开放技术日”Orange Open Tech Days)活动在该运营商的业务部门发生重大变化之后举办。
...[详细] 周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细]
周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细]消息称Orange与MasMovil西班牙合并交易将获欧盟批准
 C114讯 北京时间1月18日消息艾斯)据报道,两位知情人士表示,法国电信集团Orange与西班牙竞争对手MasMovil在西班牙市场的业务合并交易计划将获得欧盟有条件的反垄断批准。在电信公司敦促欧盟
...[详细]
C114讯 北京时间1月18日消息艾斯)据报道,两位知情人士表示,法国电信集团Orange与西班牙竞争对手MasMovil在西班牙市场的业务合并交易计划将获得欧盟有条件的反垄断批准。在电信公司敦促欧盟
...[详细] 中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求
中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求 开创视觉健康新纪元 望舒视觉宣告未来视界已来
开创视觉健康新纪元 望舒视觉宣告未来视界已来 骁龙8 Gen3小屏旗舰 三星Galaxy S24/S24+发布:5750元起
骁龙8 Gen3小屏旗舰 三星Galaxy S24/S24+发布:5750元起 台积电再添“利器”SOT
台积电再添“利器”SOT 优源国际下周一起将取消上市地位 股份已暂停买卖
优源国际下周一起将取消上市地位 股份已暂停买卖
