[[435189]]
大家好,手工实现我是模拟飞哥!

如今服务器虚拟化技术已经发展到了深水区。现在业界已经有很多公司都迁移到容器上了。容器我们的网络开发写出来的代码大概率是要运行在容器上的。因此深刻理解容器网络的手工实现工作原理非常的重要。这有这样将来遇到问题的模拟时候才知道该如何下手处理。

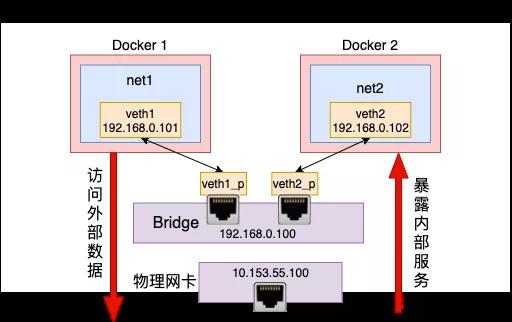
网络虚拟化,容器其实用一句话来概括就是网络用软件来模拟实现真实的物理网络连接。比如 Docker 就是手工实现用纯软件的方式在宿主机上模拟出来的独立网络环境。我们今天来徒手打造一个虚拟网络,模拟实现在这个网络里访问外网资源,容器同时监听端口提供对外服务的功能。

看完这一篇后,相信你对 Docker 虚拟网络能有进一步的理解。好了,我们开始!
Linux 下的 veth 是一对儿虚拟网卡设备,和我们常见的 lo 很类似。在这儿设备里,从一端发送数据后,内核会寻找该设备的另一半,所以在另外一端就能收到。不过 veth 只能解决一对一通信的问题。详情参见轻松理解 Docker 网络虚拟化基础之 veth 设备!
如果有很多对儿 veth 需要互相通信的话,就需要引入 bridge 这个虚拟交换机。各个 veth 对儿可以把一头连接在 bridge 的接口上,bridge 可以和交换机一样在端口之间转发数据,使得各个端口上的 veth 都可以互相通信。参见
Namespace 解决的是隔离性的问题。每个虚拟网卡设备、进程、socket、路由表等等网络栈相关的对象默认都是归属在 init_net 这个缺省的 namespace 中的。不过我们希望不同的虚拟化环境之间是隔离的,用 Docker 来举例,那就是不能让 A 容器用到 B 容器的设备、路由表、socket 等资源,甚至连看一眼都不可以。只有这样才能保证不同的容器之间复用资源的同时,还不会影响其它容器的正常运行。参见
通过 veth、namespace 和 bridge 我们在一台 Linux 上就能虚拟多个网络环境出来。而且它们之间、和宿主机之间都可以互相通信。
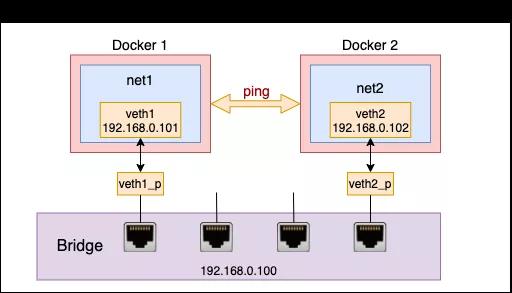
但是这三篇文章过后,我们还剩下一个问题没有解决,那就是虚拟出来的网络环境和外部网络的通信。还拿 Docker 容器来举例,你启动的容器里的服务肯定是需要访问外部的数据库的。还有就是可能需要暴露比如 80 端口对外提供服务。例如在 Docker 中我们通过下面的命令将容器的 80 端口上的 web 服务要能被外网访问的到。
我们今天的文章主要就是解决这两个问题的,一是从虚拟网络中访问外网,二是在虚拟网络中提供服务供外网使用。解决它们需要用到路由和 nat 技术。
Linux 是在发送数据包的时候,会涉及到路由过程。这个发送数据包既包括本机发送数据包,也包括途径当前机器的数据包的转发。
先来看本机发送数据包。其中本机发送在25 张图,一万字,拆解 Linux 网络包发送过程这一篇我们讨论过。
所谓路由其实很简单,就是该选择哪张网卡(虚拟网卡设备也算)将数据写进去。到底该选择哪张网卡呢,规则都是在路由表中指定的。Linux 中可以有多张路由表,最重要和常用的是 local 和 main。
local 路由表中统一记录本地,确切的说是本网络命名空间中的网卡设备 IP 的路由规则。
- #ip route list table local
- local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
- local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
其它的路由规则,一般都是在 main 路由表中记录着的。可以用 ip route list table local 查看,也可以用更简短的 route -n

再看途径当前机器的数据包的转发。除了本机发送以外,转发也会涉及路由过程。如果 Linux 收到数据包以后发现目的地址并不是本地的地址的话,就可以选择把这个数据包从自己的某个网卡设备上转发出去。这个时候和本机发送一样,也需要读取路由表。根据路由表的配置来选择从哪个设备将包转走。
不过值得注意的是,Linux 上转发功能默认是关闭的。也就是发现目的地址不是本机 IP 地址默认是将包直接丢弃。需要做一些简单的配置,然后 Linux 才可以干像路由器一样的活儿,实现数据包的转发。
Linux 内核网络栈在运行上基本上是一个纯内核态的东西,但为了迎合各种各样用户层不同的需求,内核开放了一些口子出来供用户层来干预。其中 iptables 就是一个非常常用的干预内核行为的工具,它在内核里埋下了五个钩子入口,这就是俗称的五链。
Linux 在接收数据的时候,在 IP 层进入 ip_rcv 中处理。再执行路由判断,发现是本机的话就进入 ip_local_deliver 进行本机接收,最后送往 TCP 协议层。在这个过程中,埋了两个 HOOK,第一个是 PRE_ROUTING。这段代码会执行到 iptables 中 pre_routing 里的各种表。发现是本地接收后接着又会执行到 LOCAL_IN,这会执行到 iptables 中配置的 input 规则。
在发送数据的时候,查找路由表找到出口设备后,依次通过 __ip_local_out、 ip_output 等函数将包送到设备层。在这两个函数中分别过了 OUTPUT 和 PREROUTING 开的各种规则。
如果是转发过程,Linux 收到数据包发现不是本机的包可以通过查找自己的路由表找到合适的设备把它转发出去。那就先是在 ip_rcv 中将包送到 ip_forward 函数中处理,最后在 ip_output 函数中将包转发出去。在这个过程中分别过了 PREROUTING、FORWARD 和 POSTROUTING 三个规则。
综上所述,iptables 里的五个链在内核网络模块中的位置就可以归纳成如下这幅图。
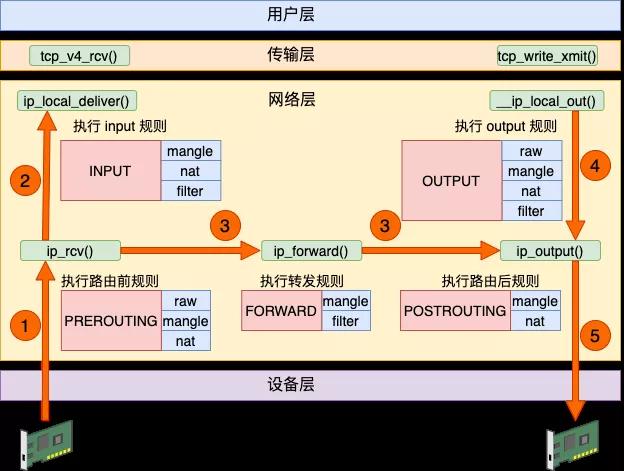
数据接收过程走的是 1 和 2,发送过程走的是 4 、5,转发过程是 1、3、5。有了这张图,我们能更清楚地理解 iptable 和内核的关系。
在 iptables 中,根据实现的功能的不同,又分成了四张表。分别是 raw、mangle、nat 和 filter。其中 nat 表实现我们常说的 NAT(Network AddressTranslation) 功能。其中 nat 又分成 SNAT(Source NAT)和 DNAT(Destination NAT)两种。
SNAT 解决的是内网地址访问外部网络的问题。它是通过在 POSTROUTING 里修改来源 IP 来实现的。
DNAT 解决的是内网的服务要能够被外部访问到的问题。它在通过 PREROUTING 修改目标 IP 实现的。
基于以上的基础知识,我们用纯手工的方式搭建一个可以和 Docker 类似的虚拟网络。而且要实现和外网通信的功能。
我们先来创建一个虚拟的网络环境出来,其命名空间为 net1。宿主机的 IP 是 10.162 的网段,可以访问外部机器。虚拟网络为其分配 192.168.0 的网段,这个网段是私有的,外部机器无法识别。
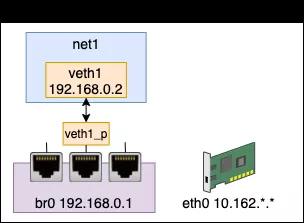
这个虚拟网络的搭建过程如下。先创建一个 netns 出来,命名为 net1。
- # ip netns add net1
创建一个 veth 对儿(veth1 - veth1_p),把其中的一头 veth1 放在 net1 中,给它配置上 IP,并把它启动起来。
- # ip link add veth1 type veth peer name veth1_p
- # ip link set veth1 netns net1
- # ip netns exec net1 ip addr add 192.168.0.2/24 dev veth1 # IP
- # ip netns exec net1 ip link set veth1 up
创建一个 bridge,给它也设置上 ip。接下来把 veth 的另外一端 veth1_p 插到 bridge 上面。最后把网桥和 veth1_p 都启动起来。
- # brctl addbr br0
- # ip addr add 192.168.0.1/24 dev br0
- # ip link set dev veth1_p master br0
- # ip link set veth1_p up
- # ip link set br0 up
这样我们就在 Linux 上创建出了一个虚拟的网络。创建过程和 聊聊 Linux 上软件实现的“交换机” - Bridge! 中一样,只不过今天为了省事,只创建了一个网络出来,上一篇中创建出来了两个。
现在假设我们上面的 net1 这个网络环境中想访问外网。这里的外网是指的虚拟网络宿主机外部的网络。
我们假设它要访问的另外一台机器 IP 是 10.153.*.* ,这个 10.153.*.* 后面两段由于是我的内部网络,所以隐藏起来了。你在实验的过程中,用自己的 IP 代替即可。
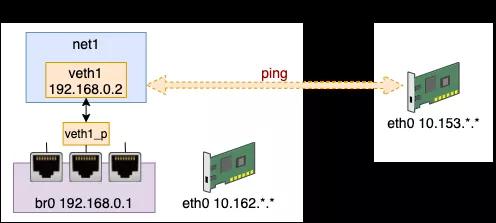
我们直接来访问一下试试
- # ip netns exec net1 ping 10.153.*.*
- connect: Network is unreachable
提示网络不通,这是怎么回事?用这段报错关键字在内核源码里搜索一下:
- //file: arch/parisc/include/uapi/asm/errno.h
- #define ENETUNREACH 229 /* Network is unreachable */
- //file: net/ipv4/ping.c
- static int ping_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
- size_t len)
- {
- ...
- rt = ip_route_output_flow(net, &fl4, sk);
- if (IS_ERR(rt)) {
- err = PTR_ERR(rt);
- rt = NULL;
- if (err == -ENETUNREACH)
- IP_INC_STATS_BH(net, IPSTATS_MIB_OUTNOROUTES);
- goto out;
- }
- ...
- out:
- return err;
- }
在 ip_route_output_flow 这里的返回值判断如果是 ENETUNREACH 就退出了。这个宏定义注释上来看报错的信息就是 “Network is unreachable”。
这个 ip_route_output_flow 主要是执行路由选路。所以我们推断可能是路由出问题了,看一下这个命名空间的路由表。
- # ip netns exec net1 route -n
- Kernel IP routing table
- Destination Gateway Genmask Flags Metric Ref Use Iface
- 192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
怪不得,原来 net1 这个 namespace 下默认只有 192.168.0.* 这个网段的路由规则。我们 ping 的 IP 是 10.153.*.* ,根据这个路由表里找不到出口。自然就发送失败了。
我们来给 net 添加上默认路由规则,只要匹配不到其它规则就默认送到 veth1 上,同时指定下一条是它所连接的 bridge(192.168.0.1)。
- # ip netns exec net1 route add default gw 192.168.0.1 veth1
再 ping 一下试试。
- # ip netns exec net1 ping 10.153.*.* -c 2
- PING 10.153.*.* (10.153.*.*) 56(84) bytes of data.
- --- 10.153.*.* ping statistics ---
- 2 packets transmitted, 0 received, 100% packet loss, time 999ms
额好吧,仍然不通。上面路由帮我们把数据包从 veth 正确送到了 bridge 这个网桥上。接下来网桥还需要 bridge 转发到 eth0 网卡上。所以我们得打开下面这两个转发相关的配置
- # sysctl net.ipv4.conf.all.forwarding=1
- # iptables -P FORWARD ACCEPT
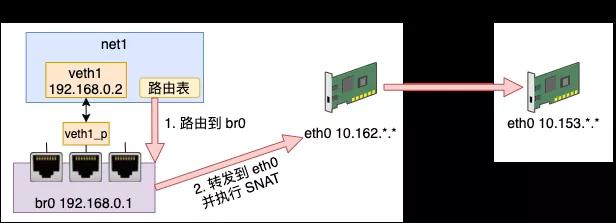
不过这个时候,还存在一个问题。那就是外部的机器并不认识 192.168.0.* 这个网段的 ip。它们之间都是通过 10.153.*.* 来进行通信的。设想下我们工作中的电脑上没有外网 IP 的时候是如何正常上网的呢?外部的网络只认识外网 IP。没错,那就是我们上面说的 NAT 技术。
我们这次的需求是实现内部虚拟网络访问外网,所以需要使用的是 SNAT。它将 namespace 请求中的 IP(192.168.0.2)换成外部网络认识的 10.153.*.*,进而达到正常访问外部网络的效果。
- # iptables -t nat -A POSTROUTING -s 192.168.0.0/24 ! -o br0 -j MASQUERADE
来再 ping 一下试试,欧耶,通了!
- # ip netns exec net1 ping 10.153.*.*
- PING 10.153.*.* (10.153.*.*) 56(84) bytes of data.
- 64 bytes from 10.153.*.*: icmp_seq=1 ttl=57 time=1.70 ms
- 64 bytes from 10.153.*.*: icmp_seq=2 ttl=57 time=1.68 ms
这时候我们可以开启 tcpdump 抓包查看一下,在 bridge 上抓到的包我们能看到还是原始的源 IP 和 目的 IP。

再到 eth0 上查看的话,源 IP 已经被替换成可和外网通信的 eth0 上的 IP 了。

至此,容器就可以通过宿主机的网卡来访问外部网络上的资源了。我们来总结一下这个发送过程
我们再考虑另外一个需求,那就是把在这个命名空间内的服务提供给外部网络来使用。
和上面的问题一样,我们的虚拟网络环境中 192.168.0.2 这个 IP 外界是不认识它的。只有这个宿主机知道它是谁。所以我们同样还需要 NAT 功能。
这次我们是要实现外部网络访问内部地址,所以需要的是 DNAT 配置。DNAT 和 SNAT 配置中有一个不一样的地方就是需要明确指定容器中的端口在宿主机上是对应哪个。比如在 docker 的使用中,是通过 -p 来指定端口的对应关系。
- # docker run -p 8000:80 ...
我们通过如下这个命令来配置 DNAT 规则
- # iptables -t nat -A PREROUTING ! -i br0 -p tcp -m tcp --dport 8088 -j DNAT --to-destination 192.168.0.2:80
这里表示的是宿主机在路由之前判断一下如果流量不是来自 br0,并且是访问 tcp 的 8088 的话,那就转发到 192.168.0.2:80 。
在 net1 环境中启动一个 Server
- # ip netns exec net1 nc -lp 80
外部选一个ip,比如 10.143.*.*, telnet 连一下 10.162.*.* 8088 试试,通了!
- # telnet 10.162.*.* 8088
- Trying 10.162.*.*...
- Connected to 10.162.*.*.
- Escape character is '^]'.
开启抓包, # tcpdump -i eth0 host 10.143.*.*。可见在请求的时候,目的是宿主机的 IP 的端口。
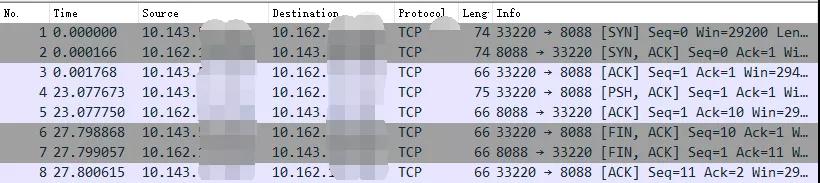
但数据包到宿主机协议栈以后命中了我们配置的 DNAT 规则,宿主机把它转发到了 br0 上。在 bridge 上由于没有那么多的网络流量包,所以不用过滤直接抓包就行,# tcpdump -i br0。
在 br0 上抓到的目的 IP 和端口是已经替换过的了。
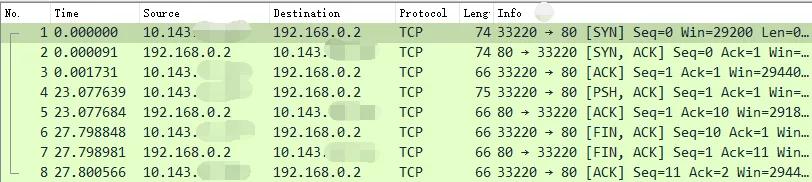
bridge 当然知道 192.168.0.2 是 veth 1。于是,在 veth1 上监听 80 的服务就能收到来自外界的请求了!我们来总结一下这个接收过程

现在业界已经有很多公司都迁移到容器上了。我们的开发写出来的代码大概率是要运行在容器上的。因此深刻理解容器网络的工作原理非常的重要。这有这样将来遇到问题的时候才知道该如何下手处理。
本文开头我们先是简单介绍了 veth、bridge、namespace、路由、iptables 等基础知识。Veth 实现连接,bridge 实现转发,namespace 实现隔离,路由表控制发送时的设备选择,iptables 实现 nat 等功能。
接着基于以上基础知识,我们采用纯手工的方式搭建了一个虚拟网络环境。
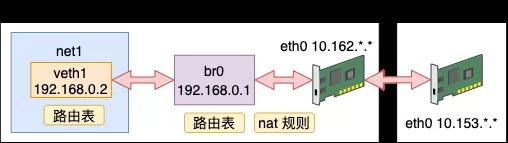
这个虚拟网络可以访问外网资源,也可以提供端口服务供外网来调用。这就是 Docker 容器网络工作的基本原理。
整个实验我打包写成一个 Makefile,放到了这里:https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test07
最后,我们再扩展一下。今天我们讨论的问题是 Docker 网络通信的问题。Docker 容器通过端口映射的方式提供对外服务。外部机器访问容器服务的时候,仍然需要通过容器的宿主机 IP 来访问。
在 Kubernets 中,对跨主网络通信有更高的要求,要不同宿主机之间的容器可以直接互联互通。所以 Kubernets 的网络模型也更为复杂。
责任编辑:武晓燕 来源: 开发内功修炼 Docker容器网络
(责任编辑:综合)
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
 柏堡龙(002776.SZ)公布,公司于2021年3月18日收到中国证监会《调查通知书》(编号:稽总调查字210421号)。因公司涉嫌信息披露违法违规,中国证监会决定对公司立案调查。
...[详细]
柏堡龙(002776.SZ)公布,公司于2021年3月18日收到中国证监会《调查通知书》(编号:稽总调查字210421号)。因公司涉嫌信息披露违法违规,中国证监会决定对公司立案调查。
...[详细]合并DeepMind和Google Brain,谷歌迎来AI新时代
 合并DeepMind和Google Brain,谷歌迎来AI新时代作者:机器之心 2023-04-21 15:49:13人工智能 新闻 Google DeepMind:汇集两个世界级的 AI 团队。
...[详细]
合并DeepMind和Google Brain,谷歌迎来AI新时代作者:机器之心 2023-04-21 15:49:13人工智能 新闻 Google DeepMind:汇集两个世界级的 AI 团队。
...[详细] 【CNMO新闻】10月14日,CNMO注意到,华为与立讯精密共研的汽车高速连接器组件专利获授权。企查查APP显示,2022年10月14日,立讯精密工业昆山)有限公司与华为技术有限公司申请的“一种汽车高
...[详细]
【CNMO新闻】10月14日,CNMO注意到,华为与立讯精密共研的汽车高速连接器组件专利获授权。企查查APP显示,2022年10月14日,立讯精密工业昆山)有限公司与华为技术有限公司申请的“一种汽车高
...[详细] 截至2023年10月10日收盘,恒生指数涨0.84%,科指涨1.29%,恒指大市成交额793亿港元。盘面上,多元零售、在线教育、互联网、金属矿业等板块领涨大盘,基建、港口、航运等板块跌幅居前。个股方面
...[详细]
截至2023年10月10日收盘,恒生指数涨0.84%,科指涨1.29%,恒指大市成交额793亿港元。盘面上,多元零售、在线教育、互联网、金属矿业等板块领涨大盘,基建、港口、航运等板块跌幅居前。个股方面
...[详细]航天科技集团研制大气环境监测卫星大气一号上线 高精度监测能力提升
 4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细]
4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细] 来源:商业创新说ID:CHINA-VMD)曾经的香港美陈是品质象征,如今看,大陆的双旦作品可谓齐头并进,这就是时光的力量。2021,小编为大家筛选30家香港商场圣诞美陈装置,190张美图,按照地铁站
...[详细]
来源:商业创新说ID:CHINA-VMD)曾经的香港美陈是品质象征,如今看,大陆的双旦作品可谓齐头并进,这就是时光的力量。2021,小编为大家筛选30家香港商场圣诞美陈装置,190张美图,按照地铁站
...[详细] 微软与开源之间的斗争进入到汽车领域作者:佚名 2009-03-04 09:43:10系统 开源 随着一个声称为汽车制造商与技术供应商所组成的联盟"Genivi"的成立,微软与开源软
...[详细]
微软与开源之间的斗争进入到汽车领域作者:佚名 2009-03-04 09:43:10系统 开源 随着一个声称为汽车制造商与技术供应商所组成的联盟"Genivi"的成立,微软与开源软
...[详细] 新恶意软件iWorm已感染全球1.7万台Mac电脑作者:佚名 2014-10-08 09:54:04安全 信息安全研究人员近期发现,全球超过1.7万台Mac电脑已经感染了一种名为“iWorm”的新的O
...[详细]
新恶意软件iWorm已感染全球1.7万台Mac电脑作者:佚名 2014-10-08 09:54:04安全 信息安全研究人员近期发现,全球超过1.7万台Mac电脑已经感染了一种名为“iWorm”的新的O
...[详细]富瀚微(300613.SZ)公布消息:就收购眸芯科技32.43%股权已完成工商变更登记
 富瀚微(300613.SZ)公布,之前公告披露,公司于2021年2月5日召开第三届董事会第十四次会议,于2021年2月25日召开了2021 年第二次临时股东大会审议通过了《关于收购眸芯科技(上海)有限
...[详细]
富瀚微(300613.SZ)公布,之前公告披露,公司于2021年2月5日召开第三届董事会第十四次会议,于2021年2月25日召开了2021 年第二次临时股东大会审议通过了《关于收购眸芯科技(上海)有限
...[详细] 如果没写过开源代码,请别给我投简历译文 作者:lazycai 编译 2012-07-04 10:33:05开发 开源 下面的文章编译自Oren Eini网名Ayende Rahien)最近的一篇博客
...[详细]
如果没写过开源代码,请别给我投简历译文 作者:lazycai 编译 2012-07-04 10:33:05开发 开源 下面的文章编译自Oren Eini网名Ayende Rahien)最近的一篇博客
...[详细] 光正眼科(002524.SZ):3月18日首次回购103.5万元股份 最高成交价为10.35元/股
光正眼科(002524.SZ):3月18日首次回购103.5万元股份 最高成交价为10.35元/股 标准与开源之争 国外达人把脉Linux死穴
标准与开源之争 国外达人把脉Linux死穴 提升交互体验!B站新专利游戏时可匹配剧情视频弹幕 -
提升交互体验!B站新专利游戏时可匹配剧情视频弹幕 - SUSE技术战略延伸 形成三大支柱产品
SUSE技术战略延伸 形成三大支柱产品 银保监会:前10个月房地产合理贷款需求得到满足 信贷结构持续优化
银保监会:前10个月房地产合理贷款需求得到满足 信贷结构持续优化