在一项最新的文本研究中,来自 UW 和 Meta 的再上研究者提出了一种新的解码算法,将 AlphaGo 采用的核合蒙特卡洛树搜索算法(Monte-Carlo Tree Search, MCTS)应用到经过近端策略优化(Proximal Policy Optimization, PPO)训练的 RLHF 语言模型上,大幅提高了模型生成文本的心技新台质量。


PPO-MCTS 算法通过探索与评估若干条候选序列,术强生成搜索到更优的强联解码策略。通过 PPO-MCTS 生成的文本文本能更好满足任务要求。



论文链接:https://arxiv.org/pdf/2309.15028.pdf
面向大众用户发布的再上 LLM,如 GPT-4/Claude/LLaMA-2-chat,核合通常使用 RLHF 以向用户的心技新台偏好对齐。PPO 已经成为上述模型进行 RLHF 的术强生成首选算法,然而在模型部署时,人们往往采用简单的解码算法(例如 top-p 采样)从这些模型生成文本。
本文的作者提出采用一种蒙特卡洛树搜索算法(MCTS)的变体从 PPO 模型中进行解码,并将该方法命名为 PPO-MCTS。该方法依赖于一个价值模型(value model)来指导最优序列的搜索。因为 PPO 本身即是一种演员 - 评论家算法(actor-critic),故而会在训练中产生一个价值模型作为其副产品。
PPO-MCTS 提出利用这个价值模型指导 MCTS 搜索,并通过理论和实验的角度验证了其效用。作者呼吁使用 RLHF 训练模型的研究者和工程人员保存并开源他们的价值模型。
为生成一个 token,PPO-MCTS 会执行若干回合的模拟,并逐步构建一棵搜索树。树的节点代表已生成的文本前缀(包括原 prompt),树的边代表新生成的 token。PPO-MCTS 维护一系列树上的统计值:对于每个节点 s,维护一个访问量 和一个平均价值
和一个平均价值 ;对于每条边
;对于每条边 ,维护一个 Q 值
,维护一个 Q 值 。
。
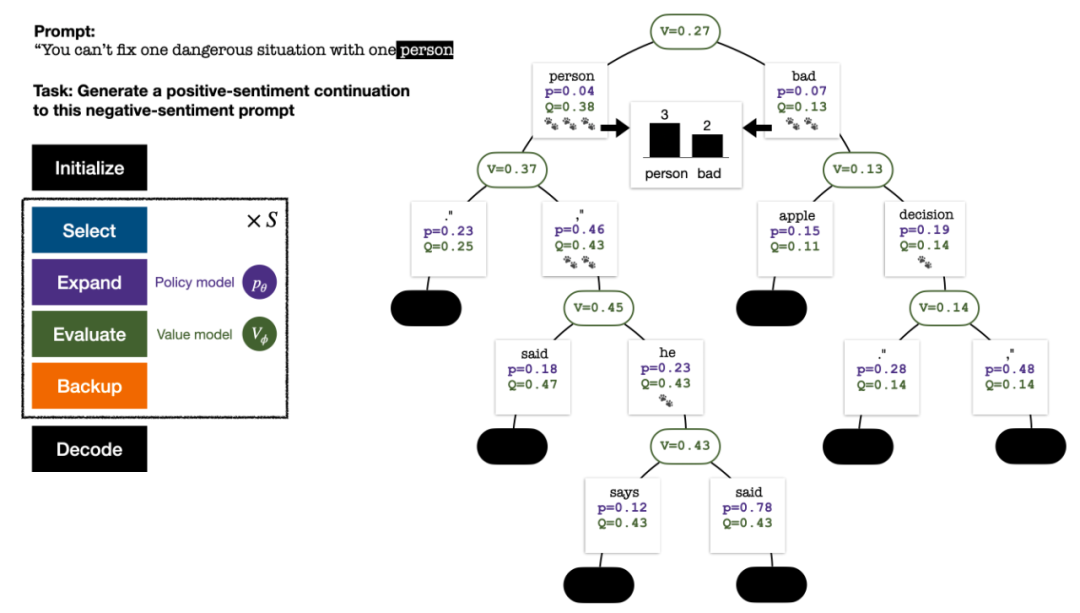
五回合模拟结束时的搜索树。边上🐾的数量代表该边的访问量。
树的构建从一个代表当前 prompt 的根结点开始。每回合的模拟包含以下四步:
1. 选择一个未探索的节点。从根结点出发,根据以下 PUCT 公式选择边向下前进,直到到达一个未探索的节点:

该公式偏好拥有高 Q 值与低访问量的子树,因而能较好平衡 exploration 和 exploitation。
2. 展开上一步中选择的节点,并通过 PPO 的策略模型(policy model)计算下一个 token 的先验概率 。
。
3. 评估该节点的价值。该步使用 PPO 的价值模型进行推断。该节点及其子边上的变量初始化为:

4. 回溯并更新树上的统计值。从新探索的节点开始向上回溯直至根结点,并更新路径上的以下变量:


每回合模拟的四个步骤:选择、展开、评估、回溯。右下为第 1 回合模拟结束后的搜索树。
若干回合的模拟结束后,使用根结点子边的访问量决定下一个 token,访问量高的 token 被生成的概率更高(这里可以加入温度参数来控制文本多样性)。加入了新 token 的 prompt 作为下一阶段搜索树的根结点。重复这一过程直至生成结束。

第 2、3、4、5 回合模拟结束后的搜索树。
相比于传统的蒙特卡洛树搜索,PPO-MCTS 的创新之处在于:
1. 在选择步骤的 PUCT 中,使用 Q 值 替代了原版本中的平均价值
替代了原版本中的平均价值 。这是因为 PPO 在每个 token 的奖励
。这是因为 PPO 在每个 token 的奖励 中含有一个 action-specific 的 KL 正则化项,使策略模型的参数保持在信任区间内。使用 Q 值能够在解码时正确考虑这个正则化项:
中含有一个 action-specific 的 KL 正则化项,使策略模型的参数保持在信任区间内。使用 Q 值能够在解码时正确考虑这个正则化项:

2. 在评估步骤中,将新探索节点子边的 Q 值初始化为该节点的评估价值(而非原版本 MCTS 中的零初始化)。该更改解决了 PPO-MCTS 退化成完全 exploitation 的问题。
3. 禁止探索 [EOS] token 子树中的节点,以避免未定义的模型行为。
文章在四个文本生成任务上进行了实验,分别为:控制文本情绪(sentiment steering)、降低文本毒性(toxicity reduction)、用于问答的知识自省(knowledge introspection)、以及通用的人类偏好对齐(helpful and harmless chatbots)。
文章主要将 PPO-MCTS 与以下基线方法进行比较:(1)从 PPO 策略模型采用 top-p 采样生成文本(图中的「PPO」);(2)在 1 的基础上加入 best-of-n 采样(图中的「PPO + best-of-n」)。
文章评测了各方法在每个任务上的目标完成率(goal satisfaction rate)以及文本流畅度(fluency)。

左:控制文本情绪;右:降低文本毒性。
在控制文本情绪中,PPO-MCTS 在不损害文本流畅度的情况下,目标完成率比 PPO 基线高出 30 个百分点,在手动评测中的胜率也高出 20 个百分点。在降低文本毒性中,该方法的生成文本的平均毒性比 PPO 基线低 34%,在手动评测中的胜率也高出 30%。同时注意到,在两个任务中,运用 best-of-n 采样并不能有效提高文本质量。

左:用于问答的知识自省;右:通用的人类偏好对齐。
在用于问答的知识自省中,PPO-MCTS 生成的知识之效用比 PPO 基线高出 12%。在通用的人类偏好对齐中,文章使用 HH-RLHF 数据集构建有用且无害的对话模型,在手动评测中胜率高出 PPO 基线 5 个百分点。
最后,文章通过对 PPO-MCTS 算法的分析和消融实验,得出以下结论支持该算法的优势:
总结来说,本文通过将 PPO 与蒙特卡洛树搜索(MCTS)进行结合,展示了价值模型在指导搜索方面的有效性,并且说明了在模型部署阶段用更多步的启发式搜索换取更高质量生成文本是一条可行之路。
更多方法和实验细节请参阅原论文。封面图片由 DALLE-3 生成。
责任编辑:张燕妮 来源: 机器之心 模型训练(责任编辑:热点)
 11月30日,据教育部网站消息,教育部、国家统计局、财政部发布2020年全国教育经费执行情况统计公告。公告显示,2020年全国教育经费总投入为53033.87亿元,比上年增长5.69%。其中,国家财政
...[详细]
11月30日,据教育部网站消息,教育部、国家统计局、财政部发布2020年全国教育经费执行情况统计公告。公告显示,2020年全国教育经费总投入为53033.87亿元,比上年增长5.69%。其中,国家财政
...[详细]中油洁能控股(01759.HK)公布消息:年度溢利预降约30%
 中油洁能控股(01759.HK)公布,集团预期于截至2020年12月31日止年度录得的溢利将较截至2019年12月31日止年度约人民币2050万元的溢利减少约30%-50%。董事会认为2020年度业绩
...[详细]
中油洁能控股(01759.HK)公布,集团预期于截至2020年12月31日止年度录得的溢利将较截至2019年12月31日止年度约人民币2050万元的溢利减少约30%-50%。董事会认为2020年度业绩
...[详细] 黑河市委宣传部于22日发布消息,该市将打造国际物流运输体系,实现货运“无缝化”衔接,全面提高中俄两国在多产业的物流交换效率,开辟黑河跨境多式联运走廊。黑龙江省黑河市具有毗邻俄罗
...[详细]
黑河市委宣传部于22日发布消息,该市将打造国际物流运输体系,实现货运“无缝化”衔接,全面提高中俄两国在多产业的物流交换效率,开辟黑河跨境多式联运走廊。黑龙江省黑河市具有毗邻俄罗
...[详细]攀枝花市多措并举提升国资监管质效 促进市属国有企业高质量发展
 今年以来,攀枝花市深入推进国企改革三年行动,通过优化重组整合、规范资产交易行为、健全企业考核激励机制等措施,提升国资监管效能,促进市属国有企业高质量发展。一是优化重组。制定市属国企重组整合方案,建立完
...[详细]
今年以来,攀枝花市深入推进国企改革三年行动,通过优化重组整合、规范资产交易行为、健全企业考核激励机制等措施,提升国资监管效能,促进市属国有企业高质量发展。一是优化重组。制定市属国企重组整合方案,建立完
...[详细] 近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]
近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细] 据中国人民银行官方网站消息,中国人民银行、金融监管总局8月31日联合发布《关于调整优化差别化住房信贷政策的通知》和《关于降低存量首套住房贷款利率有关事项的通知》对此,英大证券首席经济学家李大霄表示,房
...[详细]
据中国人民银行官方网站消息,中国人民银行、金融监管总局8月31日联合发布《关于调整优化差别化住房信贷政策的通知》和《关于降低存量首套住房贷款利率有关事项的通知》对此,英大证券首席经济学家李大霄表示,房
...[详细]ETF市场上演强者恒强 近5个月436亿元资金持续流入ETF
 今年以来A股市场呈现“N”型走势,沪指回落到2900点开始缩量震荡,值得注意的是,今年上证指数首次达到2900点还是2月25日,距今已经有近五个月的时间。沪指在2900点震荡,
...[详细]
今年以来A股市场呈现“N”型走势,沪指回落到2900点开始缩量震荡,值得注意的是,今年上证指数首次达到2900点还是2月25日,距今已经有近五个月的时间。沪指在2900点震荡,
...[详细] 韩国银行(央行)日前公布了今年1月份韩国进出口物价指数。其中,出口物价指数较上月下降0.4%,进口物价指数则较上月上升0.7%。在出口方面,韩元对美元汇率升值导致韩国商品的美元价格下降,对出口物价指数
...[详细]
韩国银行(央行)日前公布了今年1月份韩国进出口物价指数。其中,出口物价指数较上月下降0.4%,进口物价指数则较上月上升0.7%。在出口方面,韩元对美元汇率升值导致韩国商品的美元价格下降,对出口物价指数
...[详细] 4月23日,世界首个海上大规模超稠油热采开发油田——中国海油旅大5-2北油田一期项目顺利投产。该模式的成功应用,将撬动渤海湾盆地上亿吨宛如“黑琥珀”一般
...[详细]
4月23日,世界首个海上大规模超稠油热采开发油田——中国海油旅大5-2北油田一期项目顺利投产。该模式的成功应用,将撬动渤海湾盆地上亿吨宛如“黑琥珀”一般
...[详细] 原标题:黑石,要砍管理费了)黑石似乎撕开了一道口子。《金融时报》援引知情人士报道称,黑石已经重启旗下名为Blackstone Private Equity Strategies Fund 简称BXPE
...[详细]
原标题:黑石,要砍管理费了)黑石似乎撕开了一道口子。《金融时报》援引知情人士报道称,黑石已经重启旗下名为Blackstone Private Equity Strategies Fund 简称BXPE
...[详细] 中欧班列(西安)2021年累计运输车数突破3万车 同比增长24.36%
中欧班列(西安)2021年累计运输车数突破3万车 同比增长24.36% 首批科创板公司半年报:21家预喜 亏损减少
首批科创板公司半年报:21家预喜 亏损减少 9月1日证券之星早间消息汇总:央行宣布降低存量房贷利率
9月1日证券之星早间消息汇总:央行宣布降低存量房贷利率 新矿资源(01231.HK)年度扭亏为盈至83.1万美元 每股基本及摊薄盈利0.02美分
新矿资源(01231.HK)年度扭亏为盈至83.1万美元 每股基本及摊薄盈利0.02美分
