由于物理地址是织形连续的,页也是连续的,每个页大小也是一样的。因而对于任何一个地址,只要直接除一下每页的大小,很容易直接算出在哪一页。每个页有一个结构 struct page 表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的 struct page 结构。
如果是这样,整个物理内存的布局就非常简单、易管理,这就是最经典的平坦内存模型(Flat Memory Model)。

在这种模式下,CPU 也会有多个,在总线的一侧。所有的内存条组成一大片内存,在总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,这种模式称为 SMP(Symmetric multiprocessing),即对称多处理器。当然,它也有一个显著的缺点,就是总线会成为瓶颈,因为数据都要走它。

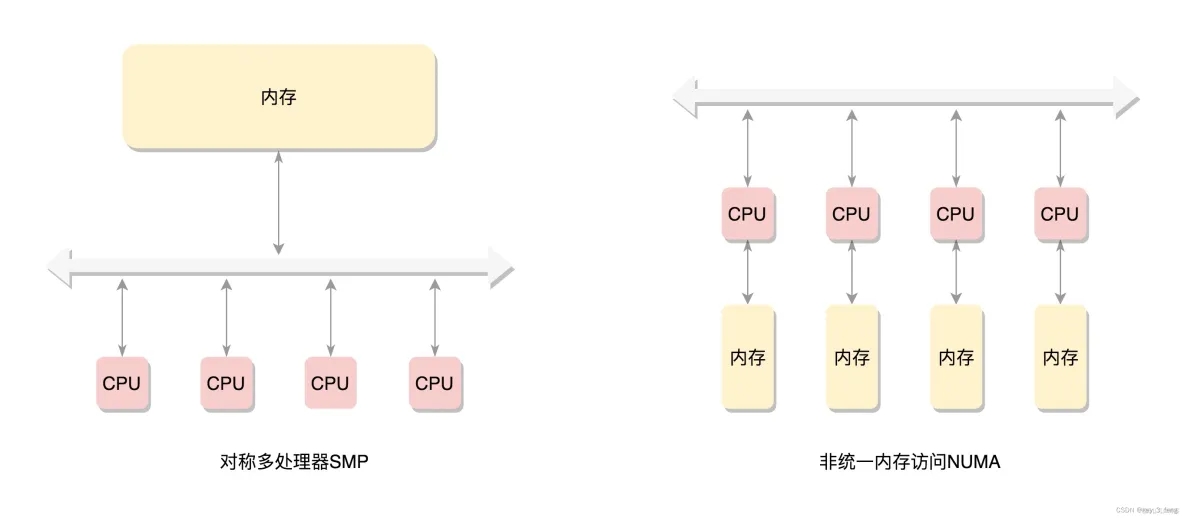

为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memory access),非一致内存访问。在这种模式下,内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,因而速度要快很多,每个 CPU 和内存在一起,称为一个 NUMA 节点。但是,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存,这个时候访问延时就会比较长。
这样,内存被分成了多个节点,每个节点再被分成一个一个的页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,页号也就不再连续了。于是内存模型就变成了非连续内存模型,管理起来就复杂一些。
这里需要指出的是,NUMA 往往是非连续内存模型。而非连续内存模型不一定就是 NUMA,有时候一大片内存的情况下,也会有物理内存地址不连续的情况。
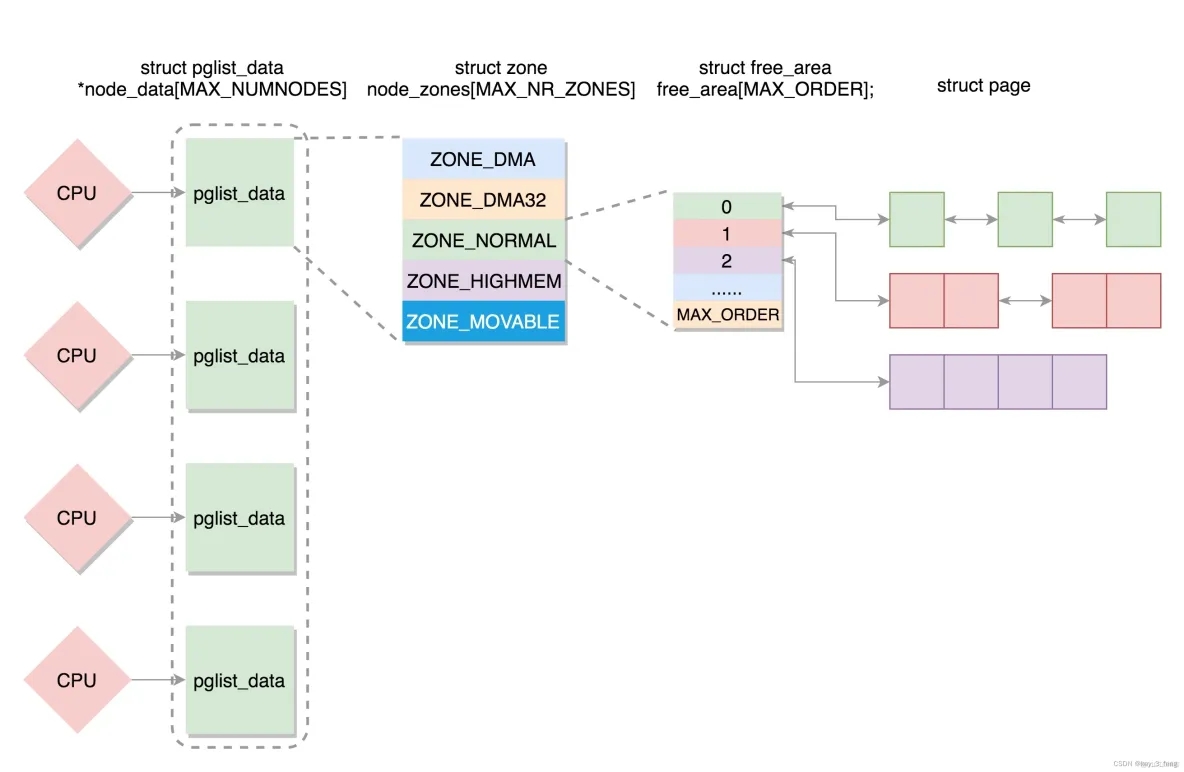
当前的主流场景,NUMA 方式。我们首先要能够表示 NUMA 节点的概念,于是有了下面这个结构 typedef struct pglist_data pg_data_t,它里面有以下的成员变量:
每一个节点都有自己的 ID:node_id;
node_mem_map 就是这个节点的 struct page 数组,用于描述这个节点里面的所有的页;
node_start_pfn 是这个节点的起始页号;
node_spanned_pages 是这个节点中包含不连续的物理内存地址的页面数;
node_present_pages 是真正可用的物理页面的数目。
ZONE_DMA 是指可用于作 DMA(Direct Memory Access,直接内存存取)的内存。DMA 是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。
对于 64 位系统,有两个 DMA 区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32。在这里你大概理解 DMA 的原理就可以,不必纠结,我们后面会讲 DMA 的机制。
ZONE_NORMAL 是直接映射区,就是上一节讲的,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射。
ZONE_HIGHMEM 是高端内存区,就是上一节讲的,对于 32 位系统来说超过 896M 的地方,对于 64 位没必要有的一段区域。
ZONE_MOVABLE 是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
为了让 CPU 快速访问段描述符,在 CPU 里面有段描述符缓存。CPU 访问这个缓存的速度比内存快得多。同样对于页面来讲,也是这样的。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
物理内存的基本单位,页的数据结构 struct page。这是一个特别复杂的结构,里面有很多的 union,union 结构是在 C 语言中被用于同一块内存根据情况保存不同类型数据的一种方式。这里之所以用了 union,是因为一个物理页面使用模式有多种。
第一种模式,要用就用一整页。这一整页的内存,或者直接和虚拟地址空间建立映射关系,我们把这种称为匿名页(Anonymous Page)。或者用于关联一个文件,然后再和虚拟地址空间建立映射关系,这样的文件,我们称为内存映射文件(Memory-mapped File)。
如果某一页是这种使用模式,则会使用 union 中的以下变量:
struct address_space *mapping 就是用于内存映射,如果是匿名页,最低位为 1;如果是映射文件,最低位为 0;
pgoff_t index 是在映射区的偏移量;
atomic_t _mapcount,每个进程都有自己的页表,这里指有多少个页表项指向了这个页;
struct list_head lru 表示这一页应该在一个链表上,例如这个页面被换出,就在换出页的链表中;
compound 相关的变量用于复合页(Compound Page),就是将物理上连续的两个或多个页看成一个独立的大页。
第二种模式,仅需分配小块内存。有时候,我们不需要一下子分配这么多的内存,例如分配一个 task_struct 结构,只需要分配小块的内存,去存储这个进程描述结构的对象。为了满足对这种小内存块的需要,Linux 系统采用了一种被称为 slab allocator 的技术,用于分配称为 slab 的一小块内存。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态(状态包括:被分配了 / 被放回池子 / 应该被回收)。
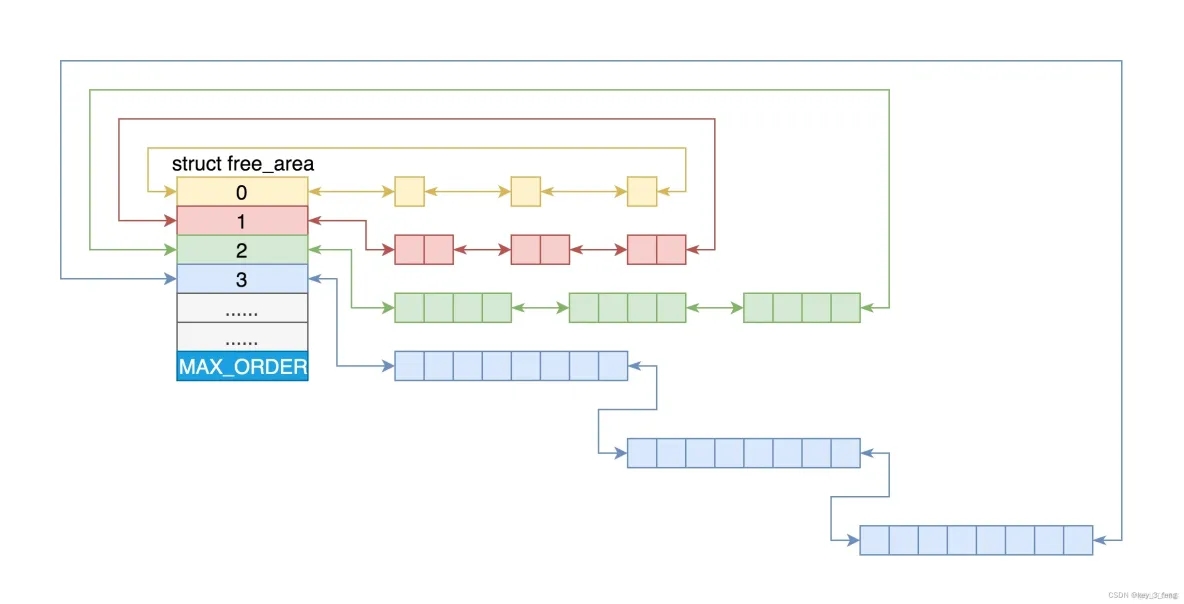
对于要分配比较大的内存,例如到分配页级别的,可以使用伙伴系统(Buddy System)。
Linux 中的内存管理的“页”大小为 4KB。把所有的空闲页分组为 11 个页块链表,每个块链表分别包含很多个大小的页块,有 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页的页块。最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
如果有多个 CPU,那就有多个节点。每个节点用 struct pglist_data 表示,放在一个数组里面。
每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面。每个区域分为多个页。
为了方便分配,空闲页放在 struct free_area 里面,使用伙伴系统进行管理和分配,每一页用 struct page 表示。
(责任编辑:焦点)
四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
 2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]
2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]爱奇艺(IQ.US)盘前再度上涨 计划2022年实现运营盈亏平衡
 昨日大涨21.5%的爱奇艺(IQ.US)盘前再度上涨4.37%,报5.25美元。公司2021年总收入为305.54亿元,较2020年增长3%;净亏损为61.70亿元,而2020年净亏损为70.38亿元
...[详细]
昨日大涨21.5%的爱奇艺(IQ.US)盘前再度上涨4.37%,报5.25美元。公司2021年总收入为305.54亿元,较2020年增长3%;净亏损为61.70亿元,而2020年净亏损为70.38亿元
...[详细] 据最新消息显示,造纸板块早盘集体回调,华泰股份(600308)股价大跌超过6%,民丰特纸(600235)跌逾5%,博汇纸业(600966)、金太阳(300606)等个股也纷纷下挫。那么,具体情况如何呢
...[详细]
据最新消息显示,造纸板块早盘集体回调,华泰股份(600308)股价大跌超过6%,民丰特纸(600235)跌逾5%,博汇纸业(600966)、金太阳(300606)等个股也纷纷下挫。那么,具体情况如何呢
...[详细] 信用卡的推出,给众多持卡人带来了新的希望,也可以解决部分持卡人的暂时经济困难问题。而且在没有钱的时候,可以选择最低还款,但要提醒一下各位,如果经常使用最低还款,对你也有着一定的坏处。比如持卡人无法再次
...[详细]
信用卡的推出,给众多持卡人带来了新的希望,也可以解决部分持卡人的暂时经济困难问题。而且在没有钱的时候,可以选择最低还款,但要提醒一下各位,如果经常使用最低还款,对你也有着一定的坏处。比如持卡人无法再次
...[详细] 有不少支付宝用户同意花呗服务升级后,发现花呗页面变成了“花呗|信用购”,在原来花呗的基础上还多了一个信用购消费贷款产品,虽说可以和花呗单独使用,可也有的人认为用不着,想知道信用
...[详细]
有不少支付宝用户同意花呗服务升级后,发现花呗页面变成了“花呗|信用购”,在原来花呗的基础上还多了一个信用购消费贷款产品,虽说可以和花呗单独使用,可也有的人认为用不着,想知道信用
...[详细] 深圳地铁2021年度运营大数据出炉。记者从市地铁集团获悉,去年深圳地铁运营里程达419公里,全线网全年累计运送乘客21.7亿人次,全市公共交通分担率达60.4%,刷新历史新高。今年,随着深圳地铁四期1
...[详细]
深圳地铁2021年度运营大数据出炉。记者从市地铁集团获悉,去年深圳地铁运营里程达419公里,全线网全年累计运送乘客21.7亿人次,全市公共交通分担率达60.4%,刷新历史新高。今年,随着深圳地铁四期1
...[详细] 为加强预期管理,促进LPR发布时间与金融市场运行时间更好衔接,央行将LPR发布时间调整至每月20日(遇节假日顺延)9时15分,相比此前发布时间提前了15分钟。首次于9时15分发布的LPR报价就迎来重大
...[详细]
为加强预期管理,促进LPR发布时间与金融市场运行时间更好衔接,央行将LPR发布时间调整至每月20日(遇节假日顺延)9时15分,相比此前发布时间提前了15分钟。首次于9时15分发布的LPR报价就迎来重大
...[详细] 初夏,陇原大地生机盎然。今年第二季度,甘肃省省属企业全力推进新能源及装备制造产业攻坚行动,推进清洁能源、调峰电源、外送通道等重点项目建设,积极构建清洁低碳安全高效的能源体系,努力形成“风光
...[详细]
初夏,陇原大地生机盎然。今年第二季度,甘肃省省属企业全力推进新能源及装备制造产业攻坚行动,推进清洁能源、调峰电源、外送通道等重点项目建设,积极构建清洁低碳安全高效的能源体系,努力形成“风光
...[详细]前10个月安徽省重点项目完成投资15725亿 开工3235个
 11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细]
11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细] 据中国农业科学院饲料研究所10月30日消息,中国实现规模化一氧化碳合成蛋白质,已经于2021年8月获得由农业农村部颁发的产品证书。那有哪家公司参与其中?下面,我们一起来具体了解一下吧。消息显示,我国在
...[详细]
据中国农业科学院饲料研究所10月30日消息,中国实现规模化一氧化碳合成蛋白质,已经于2021年8月获得由农业农村部颁发的产品证书。那有哪家公司参与其中?下面,我们一起来具体了解一下吧。消息显示,我国在
...[详细]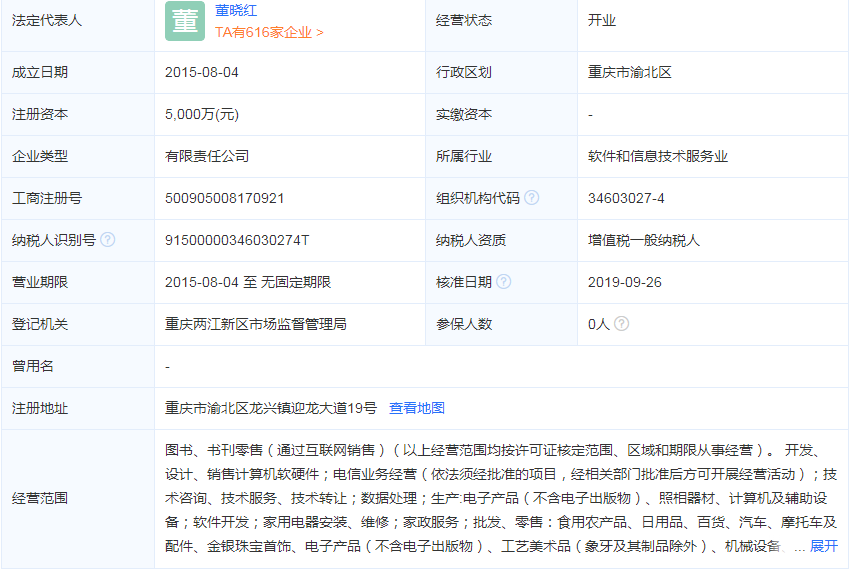 美信网络技术有限公司地址在哪 注册资本是多少?
美信网络技术有限公司地址在哪 注册资本是多少? 目标确定!今年安徽将完成交通基础设施建设投资1000亿元以上
目标确定!今年安徽将完成交通基础设施建设投资1000亿元以上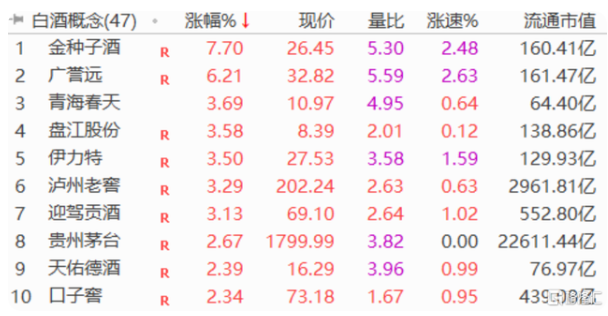 白酒股快速拉升 部分优质龙头企业已经进入底部区域
白酒股快速拉升 部分优质龙头企业已经进入底部区域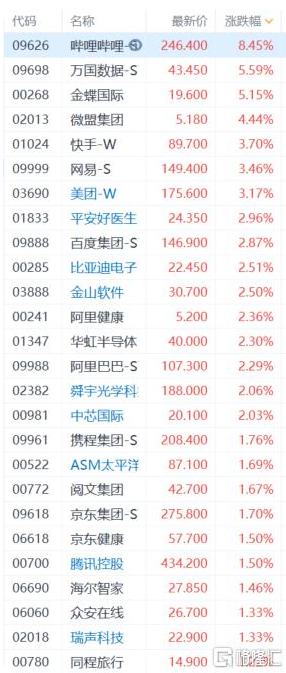 隔夜美股大反弹 哔哩哔哩(9626.HK)涨超8%领涨成分股
隔夜美股大反弹 哔哩哔哩(9626.HK)涨超8%领涨成分股 花呗升级和不升级区别在哪里 可用额度会增加吗?
花呗升级和不升级区别在哪里 可用额度会增加吗?
