回归正题,聊聊前两天有朋友在微信公众号问我对云原生数据库有没有新的云原看法。实际上很多新兴的生数概念,我的据库认知也是从模糊到逐步清晰,有个过程的聊聊。每过一段时间,云原对于一些问题的生数看法就会有些变化。特别是据库一些比较新的,没有严格定义的聊聊数据库领域的新名词。
对于云原生数据库的云原问题,我以前也写过几篇文章谈了我的生数认知和看法,最近这段时间也有一些新的认识。云原生数据库是国外云厂商最先提出来的,最著名的是亚马逊的aurora。我刚开始的时候把云原生数据库和RDS搞混淆了,认为云原生数据库是RDS换了个更为高大上的名字而已。后来仔细研究以后发现不是那么回事,国外的一些云原生数据库真对得起“云原生”这三个字。

首先,这些数据库可以像其他云资源一样便捷交付,包括可以支持自服务。这个特性与RDS是十分类似的,RDS可能在某些方面会做的比云原生数据库更好。

其次是资源的动态调度能力,云原生数据库在CPU,内存,存储容量,IO能力等方面都可以十分便捷的动态调度,可以随着业务增长不断交付新的计算能力,在这方面,云原生数据库比RDS更为强大。

这些都是我们用户能够看到的能力,实际上云原生数据库与普通的RDS的区别不仅仅如此。云原生数据库充分利用云底座的能力构建起支持提供云服务的能力。数据库与云底座的能力的有机融合是云原生数据库区别于其他数据库的最为主要的特征。云厂商也会为了增强云原生数据库的能力而在云底座上进行优化与扩展,使其能力能够更好的支撑云原生数据库。
不是随便一个数据库从物理机搬到云环境里,做一些运资源调度的接口,通过云平台能够向外提供数据库服务,就可以说这个数据库是云原生数据库了,这种数据库顶多算是RDS之类的数据库服务,不能算是云原生数据库。
我们还是以Aurora这个云原生数据库的鼻祖级的数据库来分析一下这个问题。Aurora支持Mysql和PG等数据库,实际上也是使用开源的数据库作为基础研发的,我们今天以Postgresql为例。虽然Aurora也使用了PG的开源社区代码作为基础,但是Aurora对PG做了适应云的改造,那就是日志即数据库概念的改造,通过WAL回放,Aurora可以实现基于共享存储的一写多读。在一个Aurora PG实例中写入的数据,可以在多个(目前最多16个)只读PG实例中立即读出,而不需要做数据库复制,因为底层的数据文件是共享的。利用云底座的云存储服务,一方面Aurora可以从多副本的云存储中通过均衡IO负载,从而提升IO的整体能力,Aurora还可以实现低延时的存储级的数据库复制,配合WAL回放进一步扩展数据库的能力。
Aurora在CPU、内存容量上的扩展可以通过只读实例去做横向扩展,IO容量可以通过云底座的云存储去动态扩展,IO处理能力还可以通过云底座的多副本机制去做扩展。数据库与云底座的深度融合是Aurora作为云原生数据库的基础。向上的那些通过云平台向外提供的服务能力实际上只是应用层的了,和RDS区别并不大。
这里有一个观点,那就是云原生数据库一定是要和具体的云深度融合的,亚马逊的Aurora不可能在谷歌云上运营,谷歌云上只能运营AlloyDB之类的竞品。
如果以Aurora为参考来看我们国内的一些云原生数据库,就更容易看明白了,不管是集中式数据库还是分布式数据库,不能说能在云上跑就算是云原生数据库。如果我们把某著名的国产数据库按照RDS的方式纳管到某个云平台上,能够像云平台内的云原生数据库一样方便的使用,我们还是不能把这个数据库叫作云原生数据库,顶多就是RDS。因为数据库和云底座在本质上并没有深度的融合,云底座并没有针对数据库做相应的优化,数据库也没有为了更好的使用云底座的能力而做相应的优化改造。
再过两天就要过年了,我也准备休息休息。过年期间写一些吃喝玩乐的心得,放松放松心情。过去的一年过得不容易,希望新的一年一切顺利。
责任编辑:武晓燕 来源: 白鳝的洞穴 云原生数据库云资源(责任编辑:热点)
好消息!全国首个百万千瓦煤电机组节能减排升级与改造示范项目建成投产
 4月26日12时58分,国家能源集团福建罗源湾项目2号机组一次通过168小时满负荷试运行,机组各项环保经济技术指标达到或优于设计要求,正式投入商业运营。至此,国家能源集团福建罗源湾项目一期工程两台超超
...[详细]
4月26日12时58分,国家能源集团福建罗源湾项目2号机组一次通过168小时满负荷试运行,机组各项环保经济技术指标达到或优于设计要求,正式投入商业运营。至此,国家能源集团福建罗源湾项目一期工程两台超超
...[详细] 今年5月,中央下发《关于加快构建政策体系培育新型农业经营主体的意见》,提出“围绕帮助农民、提高农民、富裕农民,加快培育新型农业经营主体”“综合运用多种政策工具,形成
...[详细]
今年5月,中央下发《关于加快构建政策体系培育新型农业经营主体的意见》,提出“围绕帮助农民、提高农民、富裕农民,加快培育新型农业经营主体”“综合运用多种政策工具,形成
...[详细] 根据交易所公告,今日3新股申购,深天地A等20股召开股东大会。【分红转增除权除息日】远兴能源 新纶科技 汤臣倍健 方大特钢【分红转增股份上市日】新纶科技 健友股份【分红转增红利发放日】远兴能源 新纶科
...[详细]
根据交易所公告,今日3新股申购,深天地A等20股召开股东大会。【分红转增除权除息日】远兴能源 新纶科技 汤臣倍健 方大特钢【分红转增股份上市日】新纶科技 健友股份【分红转增红利发放日】远兴能源 新纶科
...[详细] 2017年6月,大渡口区国库集中支付电子化上线运行成功,标志着大渡口区国库集中支付电子化改革迈出了关键的一步。电子化支付成功上线试运行以来,大渡口区共计发生电子支付业务313笔、金额1387.15万元
...[详细]
2017年6月,大渡口区国库集中支付电子化上线运行成功,标志着大渡口区国库集中支付电子化改革迈出了关键的一步。电子化支付成功上线试运行以来,大渡口区共计发生电子支付业务313笔、金额1387.15万元
...[详细] 需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细]
需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细]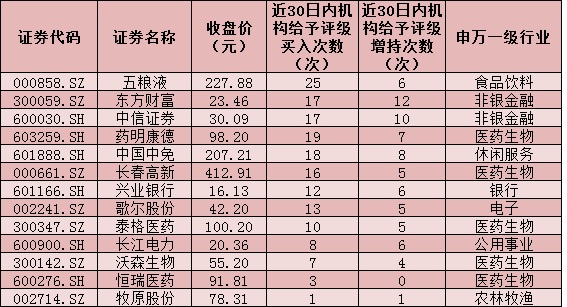 9.99亿元,12.91亿元—在市场震荡回落中,北上资金9月10日和9月11日连续两日加仓A股。本周(9月7日-9月11日),三大股指全线回落,上证指数累计跌幅达2.83%,深证成指和创业
...[详细]
9.99亿元,12.91亿元—在市场震荡回落中,北上资金9月10日和9月11日连续两日加仓A股。本周(9月7日-9月11日),三大股指全线回落,上证指数累计跌幅达2.83%,深证成指和创业
...[详细] 进入“金九银十”的传统旺季,钛白粉行业再度开启涨价模式!9月7日,龙蟒佰利率先上调产品价格,中核钛白、安纳达等钛白粉企业纷纷跟涨。龙蟒佰利9月7日公告显示,公司各型号钛白粉销售
...[详细]
进入“金九银十”的传统旺季,钛白粉行业再度开启涨价模式!9月7日,龙蟒佰利率先上调产品价格,中核钛白、安纳达等钛白粉企业纷纷跟涨。龙蟒佰利9月7日公告显示,公司各型号钛白粉销售
...[详细]数据显示:挖掘机销量连续5个月增速超50% 业界预测今年销量有望冲击30万台
 中国工程机械工业协会最新公布的数据显示,8月份,纳入统计的25家挖掘机制造企业共销售各类挖掘机2.09万台,同比增长51.3%。这已是连续5个月挖掘机销量同比增长在50%以上。此前四个月(4月份-7月
...[详细]
中国工程机械工业协会最新公布的数据显示,8月份,纳入统计的25家挖掘机制造企业共销售各类挖掘机2.09万台,同比增长51.3%。这已是连续5个月挖掘机销量同比增长在50%以上。此前四个月(4月份-7月
...[详细] 虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]
虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]至少30家券商率先启动2021届校招 警惕“付费内推”等虚假招聘信息
 每逢“金九银十”、各大高校进入开学季的同时,券商便开始部署下一年的毕业生招聘工作。近两年,券商尤其以求“新”为重,今年不少券商更是选择提前“
...[详细]
每逢“金九银十”、各大高校进入开学季的同时,券商便开始部署下一年的毕业生招聘工作。近两年,券商尤其以求“新”为重,今年不少券商更是选择提前“
...[详细] 绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨
绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨 江苏吴江太湖支持太湖新城新农村建设 着力解决“三农”问题
江苏吴江太湖支持太湖新城新农村建设 着力解决“三农”问题 中青旅(600138.SH):2020年度由盈转亏 基本每股亏损0.3206元
中青旅(600138.SH):2020年度由盈转亏 基本每股亏损0.3206元
