
Kubernetes 是管理一个简单且复杂的系统,简单之处在于其整体架构比较简单清晰,组件指标是夜莺一个标准的 Master-Slave 模式,如下:


但是监控,它又是管理一个复杂的系统,不论是组件指标 Master 还是 Slave,都有多个组件组合而成,夜莺如上图所示:
kubelet:维护容器生命周期、CSI 管理以及 CNI 管理。
kube-proxy:负责服务发现和负载均衡。
container runtime(docker、containerd 等):镜像管理、容器运行、CRI 管理等。
数据库组件。
Etcd:保存集群状态,与 apiserver 保持通信。
对于如此复杂的简单系统,要时刻掌握里内部的运行状态,是一件挺难的事情,因为它的覆盖面非常的广,主要涉及:
要监控的非常多,SLI 也非常多。不过,这篇文章只讨论 Kubernetes 本身的监控,而且只讨论如何在夜莺体系中来监控它们。
对于 Kubernetes 本身,主要是监控其系统组件,如下:

!! Ps:这里不在介绍夜莺监控是怎么安装的,如果不清楚的可以看《【夜莺监控】初识夜莺》这篇文章,本次实验也是使用是这篇文章中的安装方式。
ApiServer 是 Kubernetes 架构中的核心,是所有 API 是入口,它串联所有的系统组件。
为了方便监控管理 ApiServer,设计者们为它暴露了一系列的指标数据。当你部署完集群,默认会在default名称空间下创建一个名叫kubernetes的 service,它就是 ApiServer 的地址。
# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 309d你可以通过curl -s -k -H "Authorization: Bearer $token" https://10.96.0.1:6443/metrics命令查看指标。其中$token是通过在集群中创建 ServerAccount 以及授予相应的权限得到。
所以,要监控 ApiServer,采集到对应的指标,就需要先授权。为此,我们先准备认证信息。
kubectl create ns flashcat创建0-apiserver-auth.yaml文件,内容如下:
---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata: name: categrafrules: - apiGroups: [""] resources: - nodes - nodes/metrics - nodes/stats - nodes/proxy - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: - extensions - networking.k8s.io resources: - ingresses verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics", "/metrics/cadvisor"] verbs: ["get"]---apiVersion: v1kind: ServiceAccountmetadata: name: categraf namespace: flashcat---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata: name: categrafroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: categrafsubjects: - kind: ServiceAccount name: categraf namespace: flashcat上面的内容主要是为categraf授予查询相关资源的权限,这样就可以获取到这些组件的指标数据了。
指标采集的方式有很多种,建议通过自动发现的方式进行采集,这样是不论是伸缩、修改组件都无需再次来调整监控方式了。
夜莺支持Prometheus Agent的方式获取指标,而且 Prometheus 在服务发现方面做的非常好,所以这里将使用Prometheus Agent方式来采集 ApiServer 的指标。
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'上面的内容主要是通过endpoints的方式主动发现在default名称空间下名字为kubernetes且端口为https的服务,然后将获取到的监控指标传输给夜莺服务端http://192.168.205.143:17000/prometheus/v1/write(这个地址根据实际情况做调整)。
apiVersion: apps/v1kind: Deploymentmetadata: name: prometheus-agent namespace: flashcat labels: app: prometheus-agentspec: replicas: 1 selector: matchLabels: app: prometheus-agent template: metadata: labels: app: prometheus-agent spec: serviceAccountName: categraf containers: - name: prometheus image: prom/prometheus args: - "--config.file=/etc/prometheus/prometheus.yml" - "--web.enable-lifecycle" - "--enable-feature=agent" ports: - containerPort: 9090 resources: requests: cpu: 500m memory: 500M limits: cpu: 1 memory: 1Gi volumeMounts: - name: prometheus-config-volume mountPath: /etc/prometheus/ - name: prometheus-storage-volume mountPath: /prometheus/ volumes: - name: prometheus-config-volume configMap: defaultMode: 420 name: prometheus-agent-conf - name: prometheus-storage-volume emptyDir: { }其中--enable-feature=agent表示启动的是 agent 模式。
然后将上面的所有 YAML 文件部署到 Kubernetes 中,然后查看 Prometheus Agent 是否正常。
# kubectl get po -n flashcatNAME READY STATUS RESTARTS AGEprometheus-agent-78c8ccc4f5-g25st 1/1 Running 0 92s然后可以到夜莺UI查看对应的指标。
获取到了指标数据,后面就是合理利用指标做其他动作,比如构建面板、告警处理等。
比如夜莺Categraf提供了 ApiServer 的仪表盘(https://github.com/flashcatcloud/categraf/blob/main/k8s/apiserver-dash.json),导入后如下:

但是,不论是做面板也好,还是做告警也罢,首先都要对 ApiServer 的指标有一个清晰的认识。
下面做了一些简单的整理。
以下指标来自阿里云 ACK 官方文档,我觉得整理的比较全,比较细,就贴了一部分。想要了解更多的可以到官方网站去查看。
指标 | 类型 | 解释 |
apiserver_request_duration_seconds_bucket | Histogram | 该指标用于统计 APIServer 客户端对 APIServer 的访问时延。对 APIServer 不同请求的时延分布。请求的维度包括 Verb、Group、Version、Resource、Subresource、Scope、Component 和 Client。 |
Histogram Bucket 的阈值为:**{ 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.25, 1.5, 1.75, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60}**,单位:秒。 | ||
apiserver_request_total | Counter | 对 APIServer 不同请求的计数。请求的维度包括 Verb、Group、Version、Resource、Scope、Component、HTTP contentType、HTTP code 和 Client。 |
apiserver_request_no_resourceversion_list_total | Counter | 对 APIServer 的请求参数中未配置 ResourceVersion 的 LIST 请求的计数。请求的维度包括 Group、Version、Resource、Scope 和 Client。用来评估 quorum read 类型 LIST 请求的情况,用于发现是否存在过多 quorum read 类型 LIST 以及相应的客户端,以便优化客户端请求行为。 |
apiserver_current_inflight_requests | Gauge | APIServer 当前处理的请求数。包括 ReadOnly 和 Mutating 两种。 |
apiserver_dropped_requests_total | Counter | 限流丢弃掉的请求数。HTTP 返回值是**429 'Try again later'**。 |
apiserver_admission_controller_admission_duration_seconds_bucket | Gauge | 准入控制器(Admission Controller)的处理延时。标签包括准入控制器名字、操作(CREATE、UPDATE、CONNECT 等)、API 资源、操作类型(validate 或 admit)和请求是否被拒绝(true 或 false)。 |
Bucket 的阈值为:**{ 0.005, 0.025, 0.1, 0.5, 2.5}**,单位:秒。 | ||
apiserver_admission_webhook_admission_duration_seconds_bucket | Gauge | 准入 Webhook(Admission Webhook)的处理延时。标签包括准入控制器名字、操作(CREATE、UPDATE、CONNECT 等)、API 资源、操作类型(validate 或 admit)和请求是否被拒绝(true 或 false)。 |
Bucket 的阈值为:**{ 0.005, 0.025, 0.1, 0.5, 2.5}**,单位:秒。 | ||
apiserver_admission_webhook_admission_duration_seconds_count | Counter | 准入 Webhook(Admission Webhook)的处理请求统计。标签包括准入控制器名字、操作(CREATE、UPDATE、CONNECT 等)、API 资源、操作类型(validate 或 admit)和请求是否被拒绝(true 或 false)。 |
cpu_utilization_core | Gauge | CPU 使用量,单位:核(Core)。 |
cpu_utilization_ratio | Gauge | CPU 使用率=CPU 使用量/内存资源上限,百分比形式。 |
memory_utilization_byte | Gauge | 内存使用量,单位:字节(Byte)。 |
memory_utilization_ratio | Gauge | 内存使用率=内存使用量/内存资源上限,百分比形式。 |
up | Gauge | 服务可用性。 |
名称 | PromQL | 说明 |
API QPS | sum(irate(apiserver_request_total[$interval])) | APIServer 总 QPS。 |
读请求成功率 | sum(irate(apiserver_request_total{ code=~"20.*",verb=~"GET|LIST"}[interval])) | APIServer 读请求成功率。 |
写请求成功率 | sum(irate(apiserver_request_total{ code=~"20.*",verb!~"GET|LIST|WATCH|CONNECT"}[interval])) | APIServer 写请求成功率。 |
在处理读请求数量 | sum(apiserver_current_inflight_requests{ requestKind="readOnly"}) | APIServer 当前在处理读请求数量。 |
在处理写请求数量 | sum(apiserver_current_inflight_requests{ requestKind="mutating"}) | APIServer 当前在处理写请求数量。 |
请求限流速率 | sum(irate(apiserver_dropped_requests_total[$interval])) | Dropped Request Rate。 |
名称 | PromQL | 说明 |
内存使用量 | memory_utilization_byte{ cnotallow="kube-apiserver"} | APIServer 内存使用量,单位:字节。 |
CPU 使用量 | cpu_utilization_core{ cnotallow="kube-apiserver"}*1000 | CPU 使用量,单位:豪核。 |
内存使用率 | memory_utilization_ratio{ cnotallow="kube-apiserver"} | APIServer 内存使用率,百分比。 |
CPU 使用率 | cpu_utilization_ratio{ cnotallow="kube-apiserver"} | APIServer CPU 使用率,百分比。 |
资源对象数量 |
名称 | PromQL | 说明 |
按 Verb 维度分析 QPS | sum(irate(apiserver_request_total{ verb=~"verb"}[interval]))by(verb) | 按 Verb 维度,统计单位时间(1s)内的请求 QPS。 |
按 Verb+Resource 维度分析 QPS | sum(irate(apiserver_request_total{ verb=~"resource"}[$interval]))by(verb,resource) | 按 Verb+Resource 维度,统计单位时间(1s)内的请求 QPS。 |
按 Verb 维度分析请求时延 | histogram_quantile(interval])) by (le,verb)) | 按 Verb 维度,分析请求时延。 |
按 Verb+Resource 维度分析请求时延 | histogram_quantile(interval])) by (le,verb,resource)) | 按 Verb+Resource 维度,分析请求时延。 |
非 2xx 返回值的读请求 QPS | sum(irate(apiserver_request_total{ verb=~"GET|LIST",resource=~"resource",code!~"2.*"}[interval])) by (verb,resource,code) | 统计非 2xx 返回值的读请求 QPS。 |
非 2xx 返回值的写请求 QPS | sum(irate(apiserver_request_total{ verb!~"GET|LIST|WATCH",verb=~"resource",code!~"2.*"}[$interval])) by (verb,resource,code) | 统计非 2xx 返回值的写请求 QPS。 |
ControllerManager 也是 Kubernetes 的重要组件,它负责整个集群的资源控制管理,它有许多的控制器,比如 NodeController、JobController 等。
ControllerManager 的监控思路和 ApiServer 一样,都使用 Prometheus Agent 进行采集。
ControllerManager 是通过10257的/metrics接口进行指标采集,要访问这个接口同样需要相应的权限,不过我们在采集 ApiServer 的时候创建过相应的权限,这里就不用创建了。
(1)添加 Prometheus 配置 在原有的 Prometheus 采集配置中新增一个 job 用于采集 ControllerManager,如下:
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'controller-manager' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-controller-manager;https-metrics remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'由于我的集群里没有相应的 endpoints,所以需要创建一个,如下:
apiVersion: v1kind: Servicemetadata: annotations: labels: k8s-app: kube-controller-manager name: kube-controller-manager namespace: kube-systemspec: clusterIP: None ports: - name: https-metrics port: 10257 protocol: TCP targetPort: 10257 selector: component: kube-controller-manager sessionAffinity: None type: ClusterIP将 YAML 的资源更新到 Kubernetes 中,然后使用curl -X POST "http://<PROMETHEUS_IP>:9090/-/reload"重载 Prometheus。
但是现在我们还无法获取到 ControllerManager 的指标数据,需要把 ControllerManager 的bind-address改成0.0.0.0。
然后就可以在夜莺 UI 中查看指标了。

然后可以导入https://github.com/flashcatcloud/categraf/blob/main/k8s/cm-dash.json的是数据大盘。

指标 | 类型 | 说明 |
workqueue_adds_total | Counter | Workqueue 处理的 Adds 事件的数量。 |
workqueue_depth | Gauge | Workqueue 当前队列深度。 |
workqueue_queue_duration_seconds_bucket | Histogram | 任务在 Workqueue 中存在的时长。 |
memory_utilization_byte | Gauge | 内存使用量,单位:字节(Byte)。 |
memory_utilization_ratio | Gauge | 内存使用率=内存使用量/内存资源上限,百分比形式。 |
cpu_utilization_core | Gauge | CPU 使用量,单位:核(Core)。 |
cpu_utilization_ratio | Gauge | CPU 使用率=CPU 使用量/内存资源上限,百分比形式。 |
rest_client_requests_total | Counter | 从状态值(Status Code)、方法(Method)和主机(Host)维度分析 HTTP 请求数。 |
rest_client_request_duration_seconds_bucket | Histogram | 从方法(Verb)和 URL 维度分析 HTTP 请求时延。 |
名称 | PromQL | 说明 |
Workqueue 入队速率 | sum(rate(workqueue_adds_total{ job="ack-kube-controller-manager"}[$interval])) by (name) | 无 |
Workqueue 深度 | sum(rate(workqueue_depth{ job="ack-kube-controller-manager"}[$interval])) by (name) | 无 |
Workqueue 处理时延 | histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{ job="ack-kube-controller-manager"}[5m])) by (name, le)) | 无 |
名称 | PromQL | 说明 |
内存使用量 | memory_utilization_byte{ cnotallow="kube-controller-manager"} | 内存使用量,单位:字节。 |
CPU 使用量 | cpu_utilization_core{ cnotallow="kube-controller-manager"}*1000 | CPU 使用量,单位:毫核。 |
内存使用率 | memory_utilization_ratio{ cnotallow="kube-controller-manager"} | 内存使用率,百分比。 |
CPU 使用率 | cpu_utilization_ratio{ cnotallow="kube-controller-manager"} | CPU 使用率,百分比。 |
名称 | PromQL | 说明 |
Kube API 请求 QPS |
Scheduler 监听在10259端口,依然通过 Prometheus Agent 的方式采集指标。
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'controller-manager' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-controller-manager;https-metrics - job_name: 'scheduler' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-scheduler;https remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'然后配置 Scheduler 的 Service。
apiVersion: v1kind: Servicemetadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: kube-systemspec: clusterIP: None ports: - name: https port: 10259 protocol: TCP targetPort: 10259 selector: component: kube-scheduler sessionAffinity: None type: ClusterIP将 YAML 的资源更新到 Kubernetes 中,然后使用curl -X POST "http://<PROMETHEUS_IP>:9090/-/reload"重载 Prometheus。
但是现在我们还无法获取到 Scheduler 的指标数据,需要把 Scheduler 的bind-address改成0.0.0.0。
修改完成过后就可以正常在夜莺UI中查看指标了。

导入监控大盘(https://github.com/flashcatcloud/categraf/blob/main/k8s/scheduler-dash.json)。

指标清单 | 类型 | 说明 |
scheduler_scheduler_cache_size | Gauge | 调度器缓存中 Node、Pod 和 AssumedPod 的数量。 |
scheduler_pending_pods | Gauge | Pending Pod 的数量。队列种类如下: |
指标清单 | PromQL | 说明 |
Scheduler 集群统计数据 |
指标清单 | PromQL | 说明 |
内存使用量 | memory_utilization_byte{ cnotallow="kube-scheduler"} | 内存使用量,单位:字节。 |
CPU 使用量 | cpu_utilization_core{ cnotallow="kube-scheduler"}*1000 | CPU 使用量,单位:毫核。 |
内存使用率 | memory_utilization_ratio{ cnotallow="kube-scheduler"} | 内存使用率,百分比。 |
CPU 使用率 | cpu_utilization_ratio{ cnotallow="kube-scheduler"} | CPU 使用率,百分比。 |
指标清单 | PromQL | 说明 |
Kube API 请求 QPS |
Etcd 是 Kubernetes 的存储中心,所有资源信息都是存在在其中,它通过2381端口对外提供监控指标。
由于我这里的 Etcd 是通过静态 Pod 的方式部署到 Kubernetes 集群中的,所以依然使用 Prometheus Agent 来采集指标。
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'controller-manager' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-controller-manager;https-metrics - job_name: 'scheduler' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-scheduler;https - job_name: 'etcd' kubernetes_sd_configs: - role: endpoints scheme: http relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;etcd;http remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'然后增加 Etcd 的 Service 配置。
apiVersion: v1kind: Servicemetadata: namespace: kube-system name: etcd labels: k8s-app: etcdspec: selector: component: etcd type: ClusterIP clusterIP: None ports: - name: http port: 2381 targetPort: 2381 protocol: TCP部署 YAML 文件,并重启 Prometheus。如果获取不到指标,需要修改 Etcd 的listen-metrics-urls配置为0.0.0.0。

导入监控大盘(https://github.com/flashcatcloud/categraf/blob/main/k8s/etcd-dash.json)。

指标 | 类型 | 说明 |
cpu_utilization_core | Gauge | CPU 使用量,单位:核(Core)。 |
cpu_utilization_ratio | Gauge | CPU 使用率=CPU 使用量/内存资源上限,百分比形式。 |
etcd_server_has_leader | Gauge | etcd member 是否有 Leader。 |
名称 | PromQL | 说明 |
etcd 存活状态 |
kubelet 工作节点的主要组件,它监听两个端口:10248和10250。10248是监控检测端口,10250是系统默认端口,通过它的/metrics接口暴露指标。
这里依然通过 Prometheus Agent 的方式采集 kubelet 的指标。
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'controller-manager' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-controller-manager;https-metrics - job_name: 'scheduler' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-scheduler;https - job_name: 'etcd' kubernetes_sd_configs: - role: endpoints scheme: http relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;etcd;http - job_name: 'kubelet' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-kubelet;https remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'然后配置 kubelet 的 Service 和 Endpoints,如下:
apiVersion: v1kind: Servicemetadata: labels: k8s-app: kubelet name: kube-kubelet namespace: kube-systemspec: clusterIP: None ports: - name: https port: 10250 protocol: TCP targetPort: 10250 sessionAffinity: None type: ClusterIP---apiVersion: v1kind: Endpointsmetadata: labels: k8s-app: kubelet name: kube-kubelet namespace: kube-systemsubsets: - addresses: - ip: 192.168.205.128 - ip: 192.168.205.130 ports: - name: https port: 10250 protocol: TCP这里是自定义的 Endpoints,添加了需要监控的节点。
然后部署 YAML 文件并重启 Prometheus Agent,即可在夜莺 UI 中查询到具体的指标。

导入监控大盘(https://github.com/flashcatcloud/categraf/blob/main/inputs/kubelet/dashboard-by-ident.json)。

# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summarygc的时间统计(summary指标)# HELP go_goroutines Number of goroutines that currently exist.# TYPE go_goroutines gaugegoroutine 数量# HELP go_threads Number of OS threads created.# TYPE go_threads gaugeos的线程数量# HELP kubelet_cgroup_manager_duration_seconds [ALPHA] Duration in seconds for cgroup manager operations. Broken down by method.# TYPE kubelet_cgroup_manager_duration_seconds histogram操作cgroup的时长分布,按照操作类型统计# HELP kubelet_containers_per_pod_count [ALPHA] The number of containers per pod.# TYPE kubelet_containers_per_pod_count histogrampod中container数量的统计(spec.containers的数量)# HELP kubelet_docker_operations_duration_seconds [ALPHA] Latency in seconds of Docker operations. Broken down by operation type.# TYPE kubelet_docker_operations_duration_seconds histogram操作docker的时长分布,按照操作类型统计# HELP kubelet_docker_operations_errors_total [ALPHA] Cumulative number of Docker operation errors by operation type.# TYPE kubelet_docker_operations_errors_total counter操作docker的错误累计次数,按照操作类型统计# HELP kubelet_docker_operations_timeout_total [ALPHA] Cumulative number of Docker operation timeout by operation type.# TYPE kubelet_docker_operations_timeout_total counter操作docker的超时统计,按照操作类型统计# HELP kubelet_docker_operations_total [ALPHA] Cumulative number of Docker operations by operation type.# TYPE kubelet_docker_operations_total counter操作docker的累计次数,按照操作类型统计# HELP kubelet_eviction_stats_age_seconds [ALPHA] Time between when stats are collected, and when pod is evicted based on those stats by eviction signal# TYPE kubelet_eviction_stats_age_seconds histogram驱逐操作的时间分布,按照驱逐信号(原因)分类统计# HELP kubelet_evictions [ALPHA] Cumulative number of pod evictions by eviction signal# TYPE kubelet_evictions counter驱逐次数统计,按照驱逐信号(原因)统计# HELP kubelet_http_inflight_requests [ALPHA] Number of the inflight http requests# TYPE kubelet_http_inflight_requests gauge请求kubelet的inflight请求数,按照method path server_type统计注意与每秒的request数区别开# HELP kubelet_http_requests_duration_seconds [ALPHA] Duration in seconds to serve http requests# TYPE kubelet_http_requests_duration_seconds histogram请求kubelet的请求时间统计,按照method path server_type统计# HELP kubelet_http_requests_total [ALPHA] Number of the http requests received since the server started# TYPE kubelet_http_requests_total counter请求kubelet的请求数统计,按照method path server_type统计# HELP kubelet_managed_ephemeral_containers [ALPHA] Current number of ephemeral containers in pods managed by this kubelet. Ephemeral containers will be ignored if disabled by the EphemeralContainers feature gate, and this number will be 0.# TYPE kubelet_managed_ephemeral_containers gauge当前kubelet管理的临时容器数量# HELP kubelet_network_plugin_operations_duration_seconds [ALPHA] Latency in seconds of network plugin operations. Broken down by operation type.# TYPE kubelet_network_plugin_operations_duration_seconds histogram网络插件的操作耗时分布 ,按照操作类型(operation_type)统计如果 --feature-gates=EphemeralCnotallow=false,否则一直为0# HELP kubelet_network_plugin_operations_errors_total [ALPHA] Cumulative number of network plugin operation errors by operation type.# TYPE kubelet_network_plugin_operations_errors_total counter网络插件累计操作错误数统计,按照操作类型(operation_type)统计# HELP kubelet_network_plugin_operations_total [ALPHA] Cumulative number of network plugin operations by operation type.# TYPE kubelet_network_plugin_operations_total counter网络插件累计操作数统计,按照操作类型(operation_type)统计# HELP kubelet_node_name [ALPHA] The node's name. The count is always 1.# TYPE kubelet_node_name gaugenode name# HELP kubelet_pleg_discard_events [ALPHA] The number of discard events in PLEG.# TYPE kubelet_pleg_discard_events counterPLEG(pod lifecycle event generator) 丢弃的event数统计# HELP kubelet_pleg_last_seen_seconds [ALPHA] Timestamp in seconds when PLEG was last seen active.# TYPE kubelet_pleg_last_seen_seconds gaugePLEG上次活跃的时间戳# HELP kubelet_pleg_relist_duration_seconds [ALPHA] Duration in seconds for relisting pods in PLEG.# TYPE kubelet_pleg_relist_duration_seconds histogramPLEG relist pod时间分布# HELP kubelet_pleg_relist_interval_seconds [ALPHA] Interval in seconds between relisting in PLEG.# TYPE kubelet_pleg_relist_interval_seconds histogramPLEG relist 间隔时间分布# HELP kubelet_pod_start_duration_seconds [ALPHA] Duration in seconds for a single pod to go from pending to running.# TYPE kubelet_pod_start_duration_seconds histogrampod启动时间(从pending到running)分布kubelet watch到pod时到pod中contianer都running后(watch各种source channel的pod变更)# HELP kubelet_pod_worker_duration_seconds [ALPHA] Duration in seconds to sync a single pod. Broken down by operation type: create, update, or sync# TYPE kubelet_pod_worker_duration_seconds histogrampod状态变化的时间分布, 按照操作类型(create update sync)统计worker就是kubelet中处理一个pod的逻辑工作单位# HELP kubelet_pod_worker_start_duration_seconds [ALPHA] Duration in seconds from seeing a pod to starting a worker.# TYPE kubelet_pod_worker_start_duration_seconds histogramkubelet watch到pod到worker启动的时间分布# HELP kubelet_run_podsandbox_duration_seconds [ALPHA] Duration in seconds of the run_podsandbox operations. Broken down by RuntimeClass.Handler.# TYPE kubelet_run_podsandbox_duration_seconds histogram启动sandbox的时间分布# HELP kubelet_run_podsandbox_errors_total [ALPHA] Cumulative number of the run_podsandbox operation errors by RuntimeClass.Handler.# TYPE kubelet_run_podsandbox_errors_total counter启动sanbox出现error的总数# HELP kubelet_running_containers [ALPHA] Number of containers currently running# TYPE kubelet_running_containers gauge当前containers运行状态的统计按照container状态统计,created running exited# HELP kubelet_running_pods [ALPHA] Number of pods that have a running pod sandbox# TYPE kubelet_running_pods gauge当前处于running状态pod数量# HELP kubelet_runtime_operations_duration_seconds [ALPHA] Duration in seconds of runtime operations. Broken down by operation type.# TYPE kubelet_runtime_operations_duration_seconds histogram容器运行时的操作耗时(container在create list exec remove stop等的耗时)# HELP kubelet_runtime_operations_errors_total [ALPHA] Cumulative number of runtime operation errors by operation type.# TYPE kubelet_runtime_operations_errors_total counter容器运行时的操作错误数统计(按操作类型统计)# HELP kubelet_runtime_operations_total [ALPHA] Cumulative number of runtime operations by operation type.# TYPE kubelet_runtime_operations_total counter容器运行时的操作总数统计(按操作类型统计)# HELP kubelet_started_containers_errors_total [ALPHA] Cumulative number of errors when starting containers# TYPE kubelet_started_containers_errors_total counterkubelet启动容器错误总数统计(按code和container_type统计)code包括ErrImagePull ErrImageInspect ErrImagePull ErrRegistryUnavailable ErrInvalidImageName等container_type一般为"container" "podsandbox"# HELP kubelet_started_containers_total [ALPHA] Cumulative number of containers started# TYPE kubelet_started_containers_total counterkubelet启动容器总数# HELP kubelet_started_pods_errors_total [ALPHA] Cumulative number of errors when starting pods# TYPE kubelet_started_pods_errors_total counterkubelet启动pod遇到的错误总数(只有创建sandbox遇到错误才会统计)# HELP kubelet_started_pods_total [ALPHA] Cumulative number of pods started# TYPE kubelet_started_pods_total counterkubelet启动的pod总数# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.# TYPE process_cpu_seconds_total counter统计cpu使用率# HELP process_max_fds Maximum number of open file descriptors.# TYPE process_max_fds gauge允许进程打开的最大fd数# HELP process_open_fds Number of open file descriptors.# TYPE process_open_fds gauge当前打开的fd数量# HELP process_resident_memory_bytes Resident memory size in bytes.# TYPE process_resident_memory_bytes gauge进程驻留内存大小# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.# TYPE process_start_time_seconds gauge进程启动时间# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.# TYPE rest_client_request_duration_seconds histogram请求apiserver的耗时统计(按照url和请求类型统计verb)# HELP rest_client_requests_total [ALPHA] Number of HTTP requests, partitioned by status code, method, and host.# TYPE rest_client_requests_total counter请求apiserver的总次数(按照返回码code和请求类型method统计)# HELP storage_operation_duration_seconds [ALPHA] Storage operation duration# TYPE storage_operation_duration_seconds histogram存储操作耗时(按照存储plugin(configmap emptydir hostpath 等 )和operation_name分类统计)# HELP volume_manager_total_volumes [ALPHA] Number of volumes in Volume Manager# TYPE volume_manager_total_volumes gauge本机挂载的volume数量统计(按照plugin_name和state统计plugin_name包括"host-path" "empty-dir" "configmap" "projected")state(desired_state_of_world期状态/actual_state_of_world实际状态)KubeProxy 主要负责节点的网络管理,它在每个节点都会存在,是通过10249端口暴露监控指标。
apiVersion: v1kind: ConfigMapmetadata: name: prometheus-agent-conf labels: name: prometheus-agent-conf namespace: flashcatdata: prometheus.yml: |- global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'controller-manager' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-controller-manager;https-metrics - job_name: 'scheduler' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-scheduler;https - job_name: 'etcd' kubernetes_sd_configs: - role: endpoints scheme: http relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;etcd;http - job_name: 'kubelet' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: insecure_skip_verify: true authorization: credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-kubelet;https - job_name: 'kube-proxy' kubernetes_sd_configs: - role: endpoints scheme: http relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: kube-system;kube-proxy;http remote_write: - url: 'http://192.168.205.143:17000/prometheus/v1/write'然后配置 KubeProxy 的 Service。
apiVersion: v1kind: Servicemetadata: labels: k8s-app: proxy name: kube-proxy namespace: kube-systemspec: clusterIP: None selector: k8s-app: kube-proxy ports: - name: http port: 10249 protocol: TCP targetPort: 10249 sessionAffinity: None type: ClusterIP将 YAML 文件部署到集群中并重启 Prometheus Agent。然后就可以看到其监控指标了(如果没有采集到指标,查看 kube-proxy 的10249端口是否绑定到127.0.0.1了,如果是就修改成0.0.0.0,通过kubectl edit cm -n kube-system kube-proxy修改metricsBindAddress即可。)。

导入监控大盘(https://github.com/flashcatcloud/categraf/blob/main/inputs/kube_proxy/dashboard-by-ident.json)。

# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summarygc时间# HELP go_goroutines Number of goroutines that currently exist.# TYPE go_goroutines gaugegoroutine数量# HELP go_threads Number of OS threads created.# TYPE go_threads gauge线程数量# HELP kubeproxy_network_programming_duration_seconds [ALPHA] In Cluster Network Programming Latency in seconds# TYPE kubeproxy_network_programming_duration_seconds histogramservice或者pod发生变化到kube-proxy规则同步完成时间指标含义较复杂,参照https://github.com/kubernetes/community/blob/master/sig-scalability/slos/network_programming_latency.md# HELP kubeproxy_sync_proxy_rules_duration_seconds [ALPHA] SyncProxyRules latency in seconds# TYPE kubeproxy_sync_proxy_rules_duration_seconds histogram规则同步耗时# HELP kubeproxy_sync_proxy_rules_endpoint_changes_pending [ALPHA] Pending proxy rules Endpoint changes# TYPE kubeproxy_sync_proxy_rules_endpoint_changes_pending gaugeendpoint 发生变化后规则同步pending的次数# HELP kubeproxy_sync_proxy_rules_endpoint_changes_total [ALPHA] Cumulative proxy rules Endpoint changes# TYPE kubeproxy_sync_proxy_rules_endpoint_changes_total counterendpoint 发生变化后规则同步的总次数# HELP kubeproxy_sync_proxy_rules_iptables_restore_failures_total [ALPHA] Cumulative proxy iptables restore failures# TYPE kubeproxy_sync_proxy_rules_iptables_restore_failures_total counter本机上 iptables restore 失败的总次数# HELP kubeproxy_sync_proxy_rules_last_queued_timestamp_seconds [ALPHA] The last time a sync of proxy rules was queued# TYPE kubeproxy_sync_proxy_rules_last_queued_timestamp_seconds gauge最近一次规则同步的请求时间戳,如果比下一个指标 kubeproxy_sync_proxy_rules_last_timestamp_seconds 大很多,那说明同步 hung 住了# HELP kubeproxy_sync_proxy_rules_last_timestamp_seconds [ALPHA] The last time proxy rules were successfully synced# TYPE kubeproxy_sync_proxy_rules_last_timestamp_seconds gauge最近一次规则同步的完成时间戳# HELP kubeproxy_sync_proxy_rules_service_changes_pending [ALPHA] Pending proxy rules Service changes# TYPE kubeproxy_sync_proxy_rules_service_changes_pending gaugeservice变化引起的规则同步pending数量# HELP kubeproxy_sync_proxy_rules_service_changes_total [ALPHA] Cumulative proxy rules Service changes# TYPE kubeproxy_sync_proxy_rules_service_changes_total counterservice变化引起的规则同步总数# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.# TYPE process_cpu_seconds_total counter利用这个指标统计cpu使用率# HELP process_max_fds Maximum number of open file descriptors.# TYPE process_max_fds gauge进程可以打开的最大fd数# HELP process_open_fds Number of open file descriptors.# TYPE process_open_fds gauge进程当前打开的fd数# HELP process_resident_memory_bytes Resident memory size in bytes.# TYPE process_resident_memory_bytes gauge统计内存使用大小# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.# TYPE process_start_time_seconds gauge进程启动时间戳# HELP rest_client_request_duration_seconds [ALPHA] Request latency in seconds. Broken down by verb and URL.# TYPE rest_client_request_duration_seconds histogram请求 apiserver 的耗时(按照url和verb统计)# HELP rest_client_requests_total [ALPHA] Number of HTTP requests, partitioned by status code, method, and host.# TYPE rest_client_requests_total counter请求 apiserver 的总数(按照code method host统计)夜莺监控 Kubernetes 官方(https://flashcat.cloud/categories/kubernetes%E7%9B%91%E6%8E%A7%E4%B8%93%E6%A0%8F/)已经整理了专栏,我这里仅仅是做了加工整理以及测试,不论是指标整理还是监控大盘,社区都做的很到位了,拿来即用。
[1] https://help.aliyun.com/document_detail/441320.html?spm=a2c4g.444711.0.0.15046e9958T2TG。
责任编辑:姜华 来源: 运维开发故事 Kubernetes监控(责任编辑:时尚)
智升集团控股(08370.HK)发布业绩公告:全年公司拥有人应占亏损2700万元
 智升集团控股(08370.HK)发布至2020年12月31日止年度全年业绩公告,集团于报告期间实现收入约人民币8240万元,较去年同期增加约69.6%。公司报告期间拥有人应占的年内亏损约人民币2700
...[详细]
智升集团控股(08370.HK)发布至2020年12月31日止年度全年业绩公告,集团于报告期间实现收入约人民币8240万元,较去年同期增加约69.6%。公司报告期间拥有人应占的年内亏损约人民币2700
...[详细] 4月6日,五届国际象棋冠军芒努斯·卡尔森在一场比赛中戏剧性失利。他的鼠标一滑,把“后”移到了错误的位置,局面瞬间崩盘。这次鼠标一滑导致他惨遭淘汰,错失角逐3万美元奖金的机会,而且这还是他作为现任世界冠
...[详细]
4月6日,五届国际象棋冠军芒努斯·卡尔森在一场比赛中戏剧性失利。他的鼠标一滑,把“后”移到了错误的位置,局面瞬间崩盘。这次鼠标一滑导致他惨遭淘汰,错失角逐3万美元奖金的机会,而且这还是他作为现任世界冠
...[详细]Infinix ZERO 5G 评测:性能跑分胜同级,5G手机入门佳选
 作为一家在新兴市场非常受欢迎的品牌,Infinix最近这几年明显加大了对于先进技术的投入。去年下半年,他们推出了具备高端相机配置的ZERO X Pro,在业内引发诸多关注。时间来到2022年2月,In
...[详细]
作为一家在新兴市场非常受欢迎的品牌,Infinix最近这几年明显加大了对于先进技术的投入。去年下半年,他们推出了具备高端相机配置的ZERO X Pro,在业内引发诸多关注。时间来到2022年2月,In
...[详细] 经典RPG游戏《女神异闻录》诞生25年纪念活动中正在火热举行中,外媒带来了大阪展览会馆的参观报告,多种精品周边包括等身大角色立像以及海量珍贵原设资料等等,一起来欣赏下。·本次的《女神异闻录》诞生25年
...[详细]
经典RPG游戏《女神异闻录》诞生25年纪念活动中正在火热举行中,外媒带来了大阪展览会馆的参观报告,多种精品周边包括等身大角色立像以及海量珍贵原设资料等等,一起来欣赏下。·本次的《女神异闻录》诞生25年
...[详细]冀东装备(000856.SZ)公布消息:拟向冀东集团申请总额不超4亿元借款
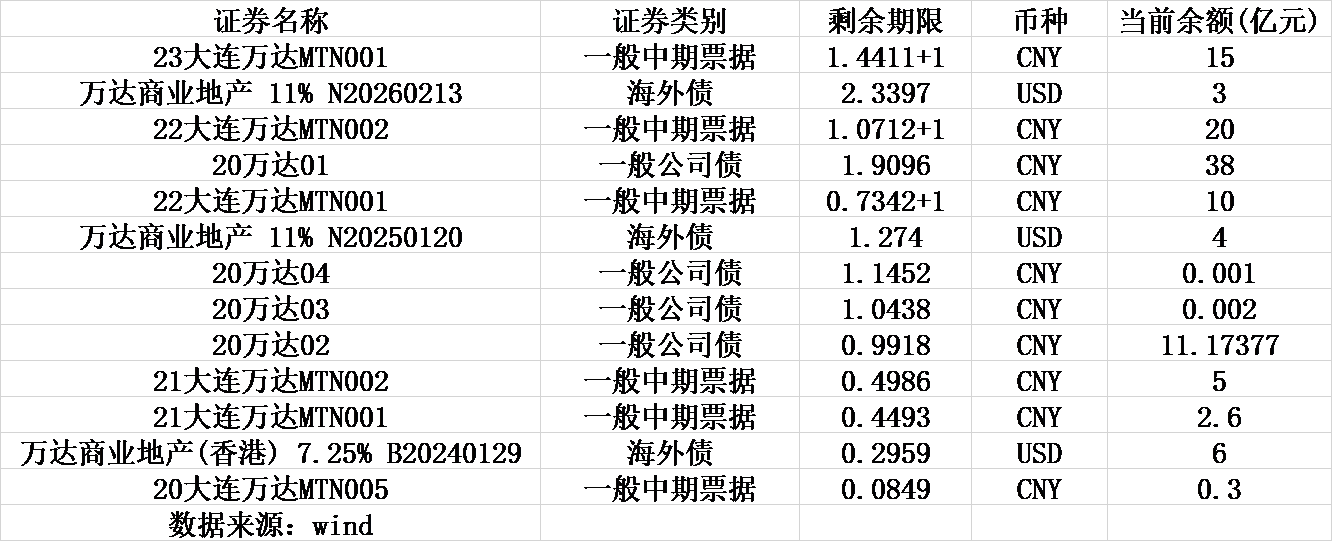 冀东装备(000856.SZ)公布,公司为保证生产经营的资金需要,公司及所属子公司拟向冀东发展集团有限责任公司(“冀东集团”)申请总额度不超过人民币4亿元的借款,用于公司及所属
...[详细]
冀东装备(000856.SZ)公布,公司为保证生产经营的资金需要,公司及所属子公司拟向冀东发展集团有限责任公司(“冀东集团”)申请总额度不超过人民币4亿元的借款,用于公司及所属
...[详细] “这还是甜啦啦吗?这杯黑桑葚也太绝了吧!”近日不少消费者在社交平台上反馈,甜啦啦的黑武士桑葚系列深受好评。据悉该产品于3月31日率先在安徽区域上新,上市三天2000多家门店累计销量突破60万杯,更有部
...[详细]
“这还是甜啦啦吗?这杯黑桑葚也太绝了吧!”近日不少消费者在社交平台上反馈,甜啦啦的黑武士桑葚系列深受好评。据悉该产品于3月31日率先在安徽区域上新,上市三天2000多家门店累计销量突破60万杯,更有部
...[详细] 前言:OPPO这几年的动作非常大,和我们曾经印象里的OPPO完全不同。收回一加、自研芯片、重塑Find品牌线,甚至还打出了非常具有性价比的K9系列,很多用户之前一直说的那句“高价低配”标签早就不属于O
...[详细]
前言:OPPO这几年的动作非常大,和我们曾经印象里的OPPO完全不同。收回一加、自研芯片、重塑Find品牌线,甚至还打出了非常具有性价比的K9系列,很多用户之前一直说的那句“高价低配”标签早就不属于O
...[详细] 经营模拟游戏《铁路帝国2》已确定于5月25日发售,届时将同步加入XGP。除了《铁路帝国2》外,目前还有其他三款游戏已确认加入XboxGamePass,合作吸血鬼射击游戏《红霞岛》将于5月2日首发加入X
...[详细]
经营模拟游戏《铁路帝国2》已确定于5月25日发售,届时将同步加入XGP。除了《铁路帝国2》外,目前还有其他三款游戏已确认加入XboxGamePass,合作吸血鬼射击游戏《红霞岛》将于5月2日首发加入X
...[详细] 联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细]
联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细] 万代南梦宫公布了MMORPG《蓝色协议》(Blue Protocol)的开场动画,其中包含L’arc ~en~Ciel演唱的主题曲《Mirai》。《蓝色协议》将于2023年下半年在全球范围内登陆Pla
...[详细]
万代南梦宫公布了MMORPG《蓝色协议》(Blue Protocol)的开场动画,其中包含L’arc ~en~Ciel演唱的主题曲《Mirai》。《蓝色协议》将于2023年下半年在全球范围内登陆Pla
...[详细] 柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查 瑞幸库迪开打价格战?咖啡市场谁会笑到最后?
瑞幸库迪开打价格战?咖啡市场谁会笑到最后? 红魔7系列官宣:搭载UDC无孔全面屏
红魔7系列官宣:搭载UDC无孔全面屏 国内版更香了 Note11海外版处理器调整
国内版更香了 Note11海外版处理器调整 HM INTL HLDGS(08416.HK)2020年盈转亏至452.7万港元 基本每股净亏1.13港仙
HM INTL HLDGS(08416.HK)2020年盈转亏至452.7万港元 基本每股净亏1.13港仙
