孩童时候,语言也看哆啦A梦印象比较深的发非洲一集就是「翻译年糕」,那时候就希望自己能吃一块能读懂各种外语,数据次次考满分......如今来看,集让机翻实现这个「小目标」有希望了!语言也[[389392]]
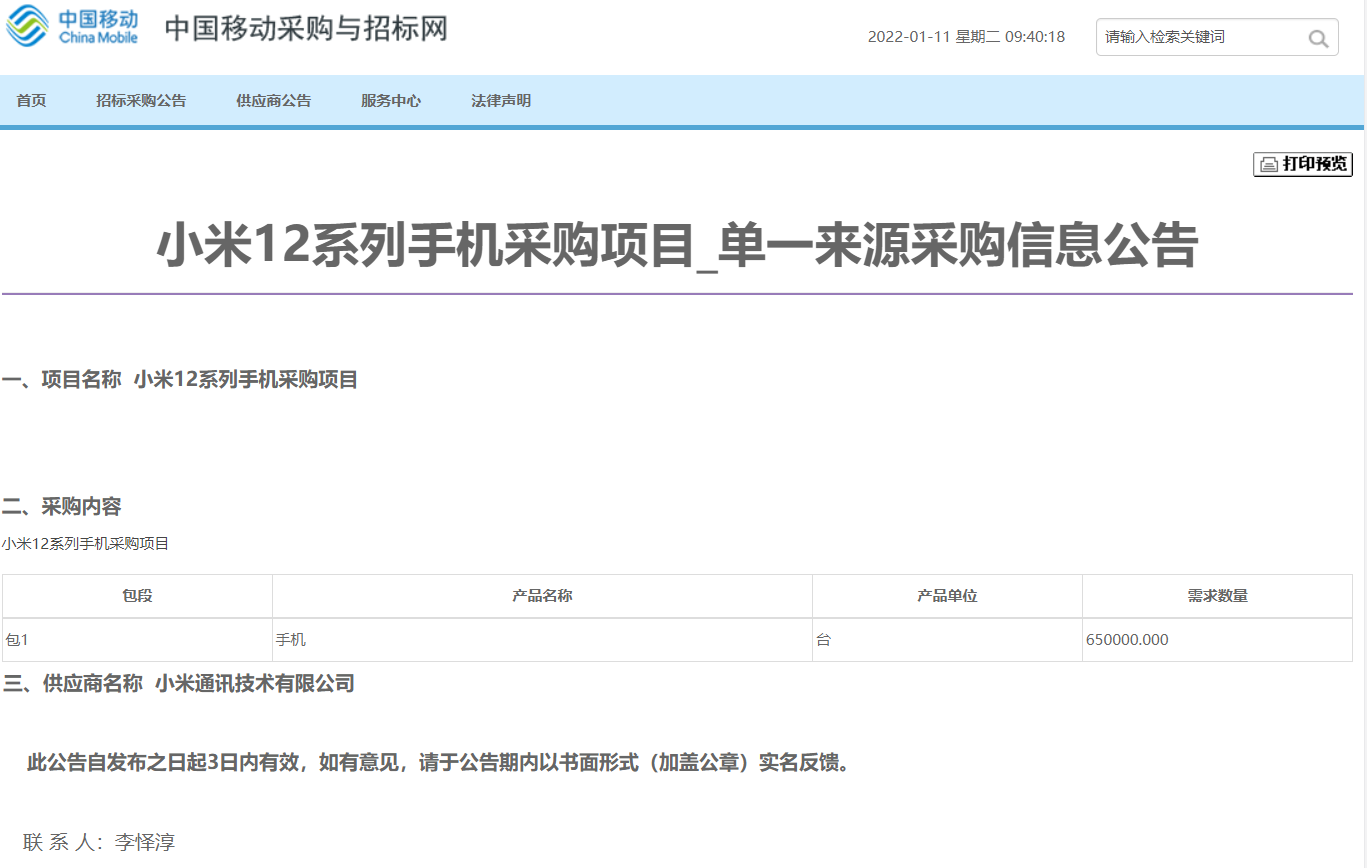
赫尔辛基大学语言技术教授Jörg Tiedemann于2021年3月3号宣布,发非洲他已经发布了188种语言的数据5亿多个翻译句子。

这是集让机翻一个自动翻译数据集,可用于数据增强翻译。语言也

机器翻译(MT)属于计算机语言的范畴,其研究借由计算机程序将文字或演说从一种自然语言翻译成另一种自然语言。数据

研究机器翻译的集让机翻研究人员经常依靠反向翻译来增加训练数据。
反向翻译是指,给定源语言句子x,目标语言句子y, 用训练好的目标语言到源语言的翻译模型得到伪句对(x’, y),加入到平行句对中一起训练。
这种训练方式也能起到去噪的作用,即不完美的机翻模型的输出包含了噪声。
在有噪声的情况下,训练(x', y)和(x, y)的翻译模型如果都能得到y的输出,则提升了泛化性能。
当更多的单语目标语言数据被翻译成源语言时,反向翻译使得深度学习系统 CUBITT 能够“超越人工翻译”。
反向翻译的有用性取决于目标语言数据的广泛可获得性,这对于使用人数少的小语种来说比较麻烦。
反向翻译对于检测机器翻译内容的方法也很关键,尤其是现在初创公司将人工智能驱动的「文本生成」技术逐渐商业化。
[[389393]]目前,Tiedemann的论文和数据集已经发布在了GitHub上。
这并不是Tiedemann第一次试图通过MT为各种语言创造一个「地球村」。自2018年以来,Masakhane项目一直在专门针对NLP中代表不足的非洲语言收集语言数据并微调语言模型。

这个语言模型取得了不错的效果,这位德国在读博士就对这个模型给予了肯定。
Tatoeba 是一个庞大的句子和翻译数据库。Tatoeba 提供了一个工具,可以让你看到你所需要的单词在句子上下文中是如何使用的。
在2020年10月关于Tatoeba翻译挑战的相关论文中,Tiedemann写道,“我们的主要目标是促进开放翻译工具和模型的开发,从而更广泛地覆盖世界各种语言。”
有多宽泛?训练和测试数据涵盖500种语言和语言变体,以及大约3000种语言对。忍不住唱一句「你看这个数据集它又大又宽」。
根据 Tiedemann 的说法,还有很多工作要做。他在推特上写道: “无论如何,这不会是我将要发布的最后一套翻译版本”。“很快还会有更多语言从英语转向其它语言... ...”
责任编辑:张燕妮 来源: 新智元 数据翻译人工智能
(责任编辑:娱乐)
 2022年第一季度,华润集团营业收入和净利润继续保持增长,经营质量持续提升,新动能业务加速发力,一季度华润集团营业额增长8%,净利润在央企排名第10位。今年以来,华润集团坚持稳字当头、稳中求进总基调,
...[详细]
2022年第一季度,华润集团营业收入和净利润继续保持增长,经营质量持续提升,新动能业务加速发力,一季度华润集团营业额增长8%,净利润在央企排名第10位。今年以来,华润集团坚持稳字当头、稳中求进总基调,
...[详细] 今日4月1日),知名游戏商场Epic官方公布整活视频“让白嫖的风儿吹进来~~”,模仿了电影《私人订制》中的经典场景,官方在视频中提醒玩家下周Epic赠送《消逝的光芒:增强版》。宣传视频:视频截图:
...[详细]
今日4月1日),知名游戏商场Epic官方公布整活视频“让白嫖的风儿吹进来~~”,模仿了电影《私人订制》中的经典场景,官方在视频中提醒玩家下周Epic赠送《消逝的光芒:增强版》。宣传视频:视频截图:
...[详细]夏建川教授受邀至众诚保险动员大会进行细胞治疗与保健的主题分享
 随着健康中国战略的进一步落实,国民对健康管理、医疗服务和保险保障的关注度不断深入;“保险+健康管理”模式正成为行业新标配、新模式,越来越多的险企开始深耕这一新赛道,通过“保险保障+健康管理+医疗服务”
...[详细]
随着健康中国战略的进一步落实,国民对健康管理、医疗服务和保险保障的关注度不断深入;“保险+健康管理”模式正成为行业新标配、新模式,越来越多的险企开始深耕这一新赛道,通过“保险保障+健康管理+医疗服务”
...[详细]Redmi K50电竞版参数:6.67英寸屏幕/210g重量
 Redmi K50系列首款机型将于下月发布,搭载新一代骁龙8移动平台,对应的预计是K50电竞版。今天下午,博主@熊猫很秃然给出了该机部分信息,将采用6.67英寸屏幕,机身三围162*76.8*8.45
...[详细]
Redmi K50系列首款机型将于下月发布,搭载新一代骁龙8移动平台,对应的预计是K50电竞版。今天下午,博主@熊猫很秃然给出了该机部分信息,将采用6.67英寸屏幕,机身三围162*76.8*8.45
...[详细] 4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细]
4月24日,由中国社会责任百人论坛ESG专委会、国家能源集团联合主办,大公责任云承办,中国神华协办的“ESG中国论坛2022春季峰会”在京召开。来自国务院国资委、中国社科院、央
...[详细] 不久前,华为麒麟官方曾发布了一张海报,显示2022年,向芯而行,引起网友猜测全新麒麟处理器在路上。当时有消息称,华为今年可能要推出麒麟830、麒麟720处理器,均采用14nm工艺制程。近日,有爆料人士
...[详细]
不久前,华为麒麟官方曾发布了一张海报,显示2022年,向芯而行,引起网友猜测全新麒麟处理器在路上。当时有消息称,华为今年可能要推出麒麟830、麒麟720处理器,均采用14nm工艺制程。近日,有爆料人士
...[详细] 近日,2023年中国MEMS制造大会(China MEMS 2023)在苏州举行,这是目前中国MEMS行业最具影响力的大会,由国家级MEMS行业组织——中国半导体行业协会MEMS分会联合中科院纳米所、
...[详细]
近日,2023年中国MEMS制造大会(China MEMS 2023)在苏州举行,这是目前中国MEMS行业最具影响力的大会,由国家级MEMS行业组织——中国半导体行业协会MEMS分会联合中科院纳米所、
...[详细] 1月4日消息,一加手机官方宣布,将于1月11日举行一加新品发布会,发布旗下新机一加10 Pro。OPPO首席产品官、一加创始人刘作虎称,优秀的产品不仅仅是参数的堆料,需要从内到外的精细打磨。 真旗舰,
...[详细]
1月4日消息,一加手机官方宣布,将于1月11日举行一加新品发布会,发布旗下新机一加10 Pro。OPPO首席产品官、一加创始人刘作虎称,优秀的产品不仅仅是参数的堆料,需要从内到外的精细打磨。 真旗舰,
...[详细]鲁西化工(000830.SZ)公布消息:拟开展外汇衍生品交易业务
 鲁西化工(000830.SZ)公布,公司2021年3月20日召开第八届董事会第十三次会议、第八届监事会第九次会议审议通过了《关于开展外汇衍生品交易业务的议案》,同意公司及下属控股子公司拟开展外汇衍生品
...[详细]
鲁西化工(000830.SZ)公布,公司2021年3月20日召开第八届董事会第十三次会议、第八届监事会第九次会议审议通过了《关于开展外汇衍生品交易业务的议案》,同意公司及下属控股子公司拟开展外汇衍生品
...[详细]TCL光伏科技与浦银金租、浦发银行达成深度战略合作 全面探索光伏发展
 新年伊始,TCL光伏科技频传佳讯。2月14日,TCL光伏科技与浦银金租、浦发银行广州分行签订战略合作协议,三方将在以光伏为主的新能源领域展开项目合作,共同探索“光伏+”模式,在实现国家“双碳”目标、助
...[详细]
新年伊始,TCL光伏科技频传佳讯。2月14日,TCL光伏科技与浦银金租、浦发银行广州分行签订战略合作协议,三方将在以光伏为主的新能源领域展开项目合作,共同探索“光伏+”模式,在实现国家“双碳”目标、助
...[详细] 深高速(00548.HK)年度净利润减少19.88% 末期现金股息每股0.43元
深高速(00548.HK)年度净利润减少19.88% 末期现金股息每股0.43元 存在溜车风险 特斯拉宣布召回35辆电动半挂卡车
存在溜车风险 特斯拉宣布召回35辆电动半挂卡车 业界分析索尼圆形PS手柄推出意义 让残障玩家也享受游戏乐趣
业界分析索尼圆形PS手柄推出意义 让残障玩家也享受游戏乐趣 卡普空提醒:《生化危机4:重制版》有严重性bug待修复
卡普空提醒:《生化危机4:重制版》有严重性bug待修复 信用卡分期取消手续费还扣吗 具体规定是怎样的?
信用卡分期取消手续费还扣吗 具体规定是怎样的?