HBase是可用一个基于Hadoop面向列的非关系型分布式数据库(NoSQL),设计概念来源于谷歌的弥补BigTable模型,面向实时读写、板看保高随机访问大规模数据集的可用场景,是弥补一个高可靠性、高性能、板看保高高伸缩的可用分布式存储系统,在大数据相关领域应用广泛。
HBase系统支持对所存储的数据进行透明切分,从而使得系统的存储以及计算具有良好的水平扩展性。

知乎从2017年起开始逐渐采用HBase系统存储各类在线业务数据,并在HBase服务之上构建各类应用模型以及数据计算任务。

背景

知乎对HBase的使用经验不算太长,在2017年初的时候,HBase服务主要用于离线算法、推荐、反作弊,还有基础数据仓库数据的存储计算,通过MapReduce和Spark来进行访问。而在当时知乎的在线存储主要采用MySQL和Redis系统,其中:
针对以上两种在线存储所存在的一些问题,我们希望建立一套在线存储NoSQL服务,对以上两种存储作为一个补充。
选型期间我们也考虑过Cassandra,早期一些业务曾尝试使用Cassandra作为存储,隔壁团队在运维了一段时间的Cassandra系统之后,遇到不少的问题,Cassandra系统可操作性没有达到预期,目前除了Tracing相关的系统,其他业务已经放弃使用Cassandra。
我们从已有的离线存储系统出发,在衡量了稳定性、性能、代码成熟度、上下游系统承接、业界使用场景以及社区活跃度等方面之后,选择了HBase,作为知乎在线存储的支撑组件之一。
一、HBase On Kubernetes
在这样的场景下,我们对在线HBase服务的需求是明确的:
隔离性
资源利用率:从运维的角度,资源的分配要合理,尽可能的提升主机cpu,内存包括磁盘的有效利用率;
成本控制:团队用最小的成本去得到相对较大的运维收益,所以需要提供便捷的调用接口,能够灵活的进行HBase集群的申请、扩容、管理、监控。同时成本包括机器资源,还有工程师。当时我们线上的这套系统是由一位工程师独立去进行维护。
综合以上需求,参考我们团队之前对基础设施平台化的经验,最终的目标是把HBase服务做成基础组件服务平台向提供给上游业务,这个也是知乎技术平台部门工作思路之一,尽可能的把所有的组件对业务都黑盒化,接口化,服务化。同时在使用和监控的粒度上尽可能的准确,细致,全面。这是我们构建在线HBase管理运维系统的一个初衷。
二、Why Kubernetes?
前文说到我们希望将整个HBase系统平台服务化,那就涉及到如何管理和运维HBase系统,知乎在微服务和容器方面的工作积累和经验是相当丰富的。
Kubernetes[3]是谷歌开源的容器集群管理系统,是Google多年大规模容器管理技术Borg的开源版本。Kubernetes提供各种维度组件的资源管理和调度方案,隔离容器的资源使用,各个组件的HA工作,同时还有较为完善的网络方案。
Kubernetes被设计作为构建组件和工具的生态系统平台,可以轻松地部署、扩展和管理应用程序。有着Kubernetes大法的加持,我们很快有了最初的落地版本([4])。
三、初代
最初的落地版本架构见下图,平台在共享的物理集群上通过Kubernetes(以下简称K8S)API建立了多套逻辑上隔离的HBase集群,每套集群由一组Master和若干个Regionserver(以下简称RS)构成,集群共享一套HDFS存储集群,各自依赖的Zookeeper集群独立;集群通过一套管理系统Kubas服务来进行管理([4])。
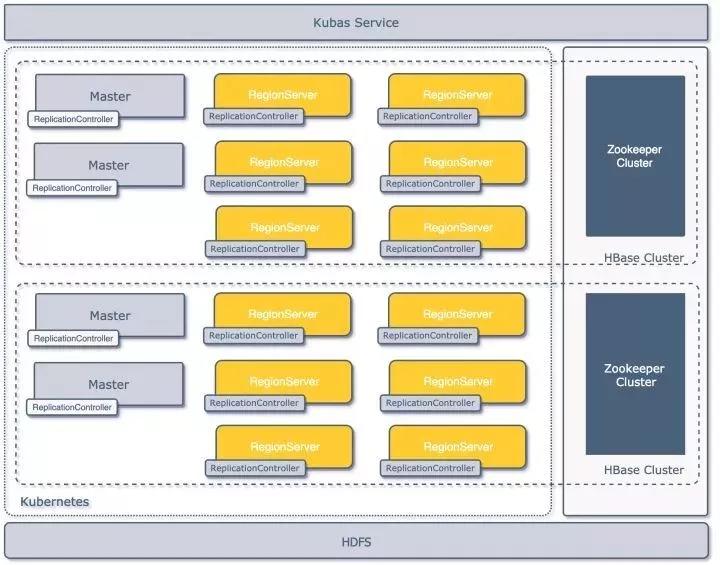
初代架构
模块定义
在K8S中如何去构建HBase集群,首先需要用K8S本身的基础组件去描述HBase的构成;K8S的资源组件有以下几种:
结合之前Kafka on K8S的经验,出于高可用和扩展性的考虑,我们没有采用一个Pod里带多个容器的部署方式,统一用一个ReplicationController定义一类HBase组件,就是上图中的Master,Regionserver还有按需创建的Thriftserver;通过以上概念,我们在K8S上就可以这样定义一套最小HBase集群:
四、高可用以及故障恢复
作为面向在线业务服务的系统,高可用和故障转移是必需在设计就要考虑的事情,在整体设计中,我们分别考虑组件级别、集群级别和数据存储级别的可用性和故障恢复问题。
1、组件级别
HBase本身已经考虑了很多故障切换和恢复的方案:
2、集群级别
3、数据级别
所有在K8S上构建的HBase集群都共享了一套HDFS集群,数据的可用性由HDFS集群的多副本来提供。
五、实现细节
1、资源分配
初期物理节点统一采用2*12核心的cpu,128G内存和4T的磁盘,其中磁盘用于搭建服务的HDFS,CPU和内存则在K8S环境中用于建立HBase相关服务的节点。
Master组件的功能主要是管理HBase集群,Thriftserver组件主要承担代理的角色,所以这两个组件资源都按照固定额度分配。
在对Regionserver组件进行资源分配设计的时候,考虑两种方式去定义资源:
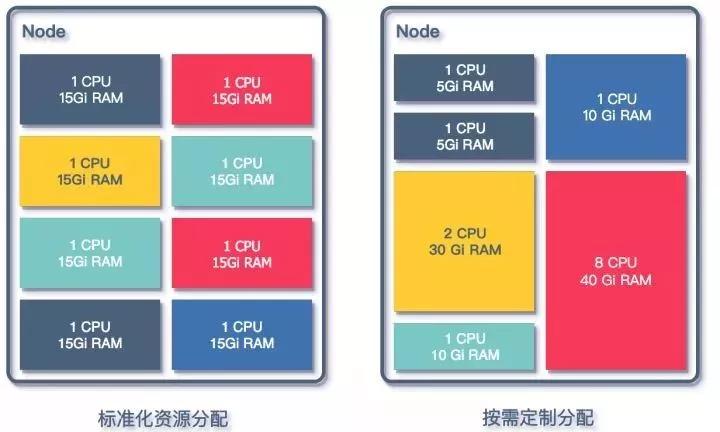
资源分配方式
按照业务需求分配:
统一规格的资源分配:
2、参数配置
基础镜像基于cdh5.5.0-hbase1.0.0构建:
- # Example for hbase dockerfile
- # install cdh5.5.0-hbase1.0.0
- ADD hdfs-site.xml /usr/lib/hbase/conf/
- ADD core-site.xml /usr/lib/hbase/conf/
- ADD env-init.py /usr/lib/hbase/bin/
- ENV JAVA_HOME /usr/lib/jvm/java-8-oracle
- ENV HBASE_HOME /usr/lib/hbase
- ENV HADOOP_PREFIX /usr/lib/hadoop
- ADD env-init.py /usr/lib/hbase/bin/
- ADD hadoop_xml_conf.sh /usr/lib/hbase/bin/
- REQUEST_DATA = {
- "name": 'test-cluster',
- "rootdir": "hdfs://namenode01:8020/tmp/hbase/test-cluster",
- "zkparent": "/test-cluster",
- "zkhost": "zookeeper01,zookeeper02,zookeeper03",
- "zkport": 2181,
- "regionserver_num": '3',
- "codecs": "snappy",
- "client_type": "java",
- "cpu": '1',
- "memory": '30',
- "status": "running",
- }
通过上面的参数KubasService启动Docker时,在启动命令中利用hadoop_xml_conf.sh和env-init.py修改hbase-site.xml和hbase-env.sh来完成配置注入,如下所示:
- source /usr/lib/hbase/bin/hadoop_xml_conf.sh
- && put_config --file /etc/hbase/conf/hbase-site.xml --property hbase.regionserver.codecs --value snappy
- && put_config --file /etc/hbase/conf/hbase-site.xml --property zookeeper.znode.parent --value /test-cluster
- && put_config --file /etc/hbase/conf/hbase-site.xml --property hbase.rootdir --value hdfs://namenode01:8020/tmp/hbase/test-cluster
- && put_config --file /etc/hbase/conf/hbase-site.xml --property hbase.zookeeper.quorum --value zookeeper01,zookeeper02,zookeeper03
- && put_config --file /etc/hbase/conf/hbase-site.xml --property hbase.zookeeper.property.clientPort --value 2181
- && service hbase-regionserver start && tail -f /var/log/hbase/hbase-hbase-regionserver.log
3、网络通信
网络方面,采用了Kubernetes上原生的网络模式,每一个Pod都有自己的IP地址,容器之间可以直接通信,同时在Kubernetes集群中添加了DNS自动注册和反注册功能,以Pod的标识名字作为域名,在Pod创建和重启和销毁时将相关信息同步全局DNS。
在这个地方我们遇到过问题,当时我们的DNS解析不能在Docker网络环境中通过IP反解出对应的容器域名,这就使得Regionserver在启动之后向Master注册和向Zookeeper集群注册的服务名字不一致,导致Master中对同一个Regionserver登记两次,造成Master与Regionserver无法正常通信,整个集群无法正常提供服务。
经过我们对源码的研究和实验之后,我们在容器启动Regionserver服务之前修改/etc/hosts文件,将Kubernetes对注入的hostname信息屏蔽。
这样的修改让容器启动的HBase集群能够顺利启动并初始化成功,但是也给运维提升了复杂度,因为现在HBase提供的Master页现在看到的Regionserver都是IP形式的记录,给监控和故障处理带来了诸多不便。
六、存在问题
初代架构顺利落地,在成功接入了近十个集群业务之后,这套架构面临了以下几个问题:
管理操作业务HBase集群较为繁琐
HBase配置
HDFS隔离
监控运维
七、重构
为了进一步解决初版架构存在的问题,优化HBase的管控流程,我们重新审视了已有的架构,并结合Kubernetes的新特性,对原有的架构进行升级改造,重新用Golang重写了整个Kubas管理系统的服务(初版使用了Python进行开发)。
并在Kubas管理系统的基础上,开发了多个用于监控和运维的基础微服务,提高了在Kubernetes上进行HBase集群部署的灵活性,架构如下图所示:
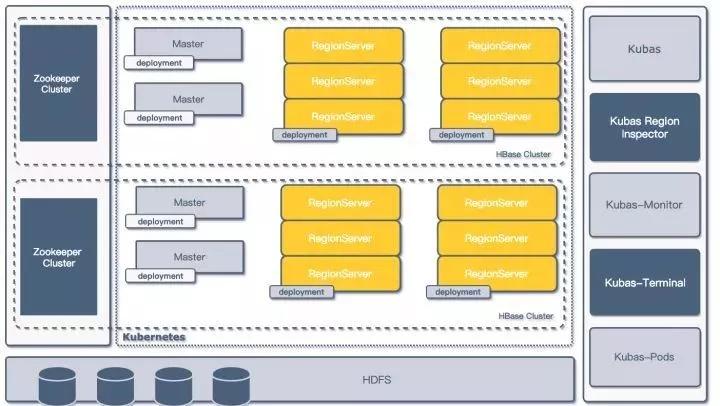
二代架构图
1、Deployment&ConfigMap
Deployment
Deployment部署
ConfigMap
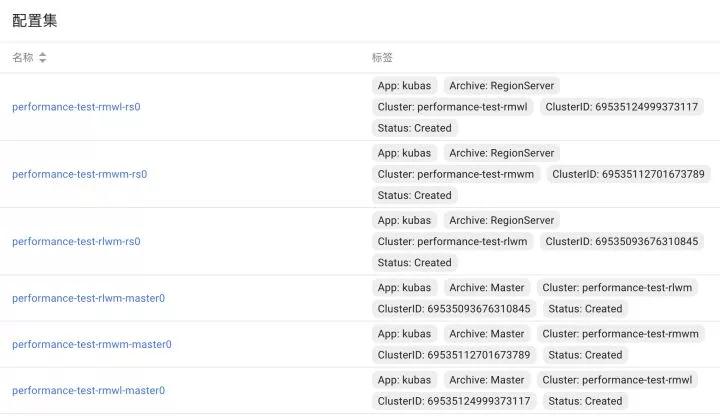
ConfigMap存档
2、组件参数配置
在引入了ConfigMap功能之后,之前创建集群的请求信息也随之改变。
- RequestData
- {
- "name": "performance-test-rmwl",
- "namespace": "online",
- "app": "kubas",
- "config_template": "online-example-base.v1",
- "status": "Ready",
- "properties": {
- "hbase.regionserver.codecs": "snappy",
- "hbase.rootdir": "hdfs://zhihu-example-online:8020/user/online-tsn/performance-test-rmwl",
- "hbase.zookeeper.property.clientPort": "2181",
- "hbase.zookeeper.quorum": "zookeeper01,zookeeper02,zookeeper03",
- "zookeeper.znode.parent": "/performance-test-rmwl"
- },
- "client_type": "java",
- "cluster_uid": "k8s-example-hbase---performance-test-rmwl---example"
- }
其中config_template指定了该集群使用的配置信息模板,之后所有和该HBase集群有关的组件配置都由该配置模板渲染出具体配置。
config_template中还预先约定了HBase组件的基础运行配置信息,如组件类型,使用的启动命令,采用的镜像文件,初始的副本数等。
- servers:
- {
- "master": {
- "servertype": "master",
- "command": "service hbase-master start && tail -f /var/log/hbase/hbase-hbase-master.log",
- "replicas": 1,
- "image": "dockerimage.zhihu.example/apps/example-master:v1.1",
- "requests": {
- "cpu": "500m",
- "memory": "5Gi"
- },
- "limits": {
- "cpu": "4000m"
- }
- },
- }
Docker镜像文件配合ConfigMap功能,在预先约定的路径方式存放配置文件信息,同时在真正的HBase配置路径中加入软链文件。
- RUN mkdir -p /data/hbase/hbase-site
- RUN mv /etc/hbase/conf/hbase-site.xml /data/hbase/hbase-site/hbase-site.xml
- RUN ln -s /data/hbase/hbase-site/hbase-site.xml /etc/hbase/conf/hbase-site.xml
- RUN mkdir -p /data/hbase/hbase-env
- RUN mv /etc/hbase/conf/hbase-env.sh /data/hbase/hbase-env/hbase-env.sh
- RUN ln -s /data/hbase/hbase-env/hbase-env.sh /etc/hbase/conf/hbase-env.sh
3、构建流程
结合之前对Deployment以及ConfigMap的引入,以及对Dockerfile的修改,整个HBase构建流程也有了改进:
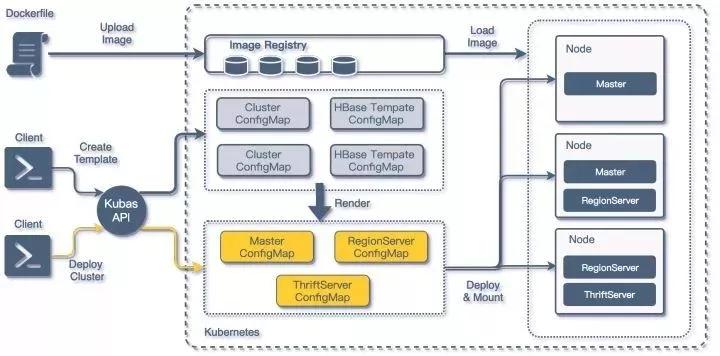
HBaseonKubernetes构建流程
通过结合K8S的ConfigMap功能的配置模板,以及KubasAPI调用,我们就可以在短时间部署出一套可用的HBase最小集群(2Master + 3Region Server + 2Thriftserver),在所有宿主机Host都已经缓存Docker镜像文件的场景下,部署并启动一整套HBase集群的时间不超过15秒。
同时在缺少专属前端控制台的情况下,可以完全依托Kubernetesdashboard完成HBase集群组件的扩容缩容,以及组件配置的查询修改更新以及重新部署。
八、资源控制
在完成重构之后,HBase服务面向知乎内部业务进行开放,短期内知乎HBase集群上升超过30+集群,伴随着HBase集群数量的增多,有两个问题逐渐显现:
为了解决如上的两个问题,同时又不能打破资源隔离的需求,我们将HBaseRSGroup功能加入到了HBase平台的管理系统中。
优化后的架构如下:
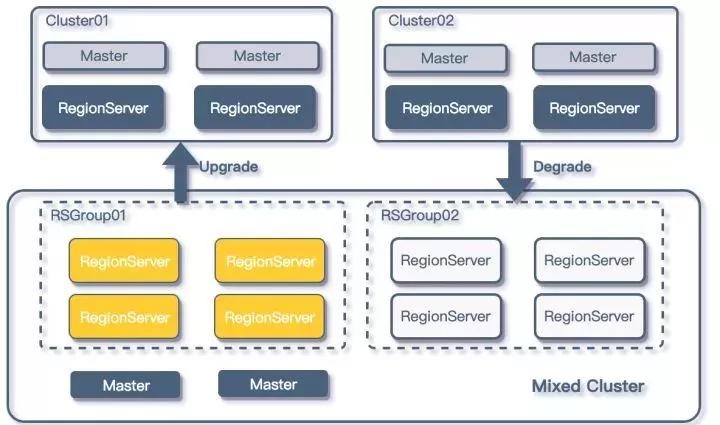
RSGroup的使用
由于平台方对业务HBase集群的管理本身就具有隔离性,所以在进行更进一步资源管理的时候,平台方采用的是降级的方式来管理HBase集群。
通过监听每个单独集群的指标,如果业务集群的负载在上线一段时间后低于阈值,平台方就会配合业务方,将该HBase集群迁移到一套MixedHBase集群上。
同时如果在MixedHBase集群中运行的某个HBase业务负载增加,并持续一段时间超过阈值后,平台方就会考虑将相关业务提升至单独的集群。
九、多IDC优化
随着知乎业务的发展和扩大,知乎的基础架构逐渐升级至多机房架构,知乎HBase平台管理方式也在这个过程中进行了进一步升级,开始构建多机房管理的管理方式;基本架构如下图所示:
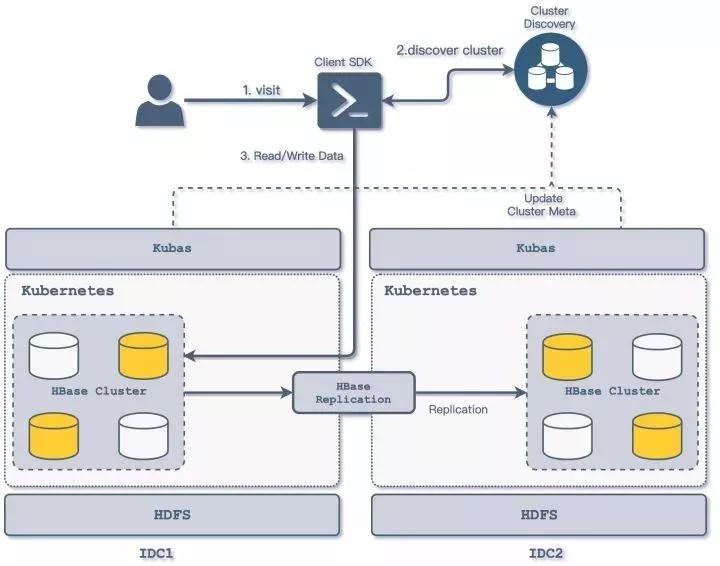
多IDC访问方式
十、数据同步
在各类业务场景中,都存在跨HBase集群的数据同步的需求,比如数据在离线HBase集群和在线集群同步、多IDC集群数据同步等,对于HBase的数据同步来说,分为全量复制和增量复制两种方式。
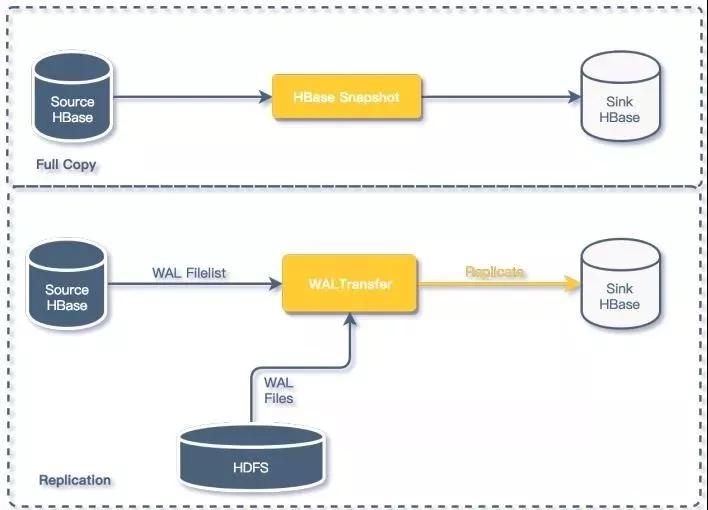
HBase数据同步
在知乎HBase平台中,我们采用两种方式进行HBase集群间的数据同步:
HBase Snapshot
全量数据复制我们采用了HBaseSnapshot的方式进行;主要应用在离线数据同步在线数据的场景;
WALTransfer
主要用于HBase集群之间的的增量数据同步;增量复制我们没有采用HBaseReplication,相关同步方式我们通过自研的WALTransfer组件来对HBase数据进行增量同步;
WALTransfer通过读取源数据HBase集群提供WAL文件列表,于HDFS集群中定位对应的WAL文件,将HBase的增量数据按序写入到目的集群,相关的细节我们会在以后的文章中详细解析。
十一、监控
从之前重构后的架构图上我们可以看到,在Kubas服务中我们添加了很多模块,这些模块基本属于HBase平台的监控管理模块。
1、Kubas-Monitor组件
基本的监控模块,采用轮询的方式发现新增HBase集群,通过订阅Zookeeper集群发现HBase集群Master以及Regionserver组。
采集Regionserver Metric中的数据,主要采集数据包括:
其他维度的指标如容器CPU以及Mem占用来自Kubernetes平台监控,磁盘IO,磁盘占用等来自主机监控:
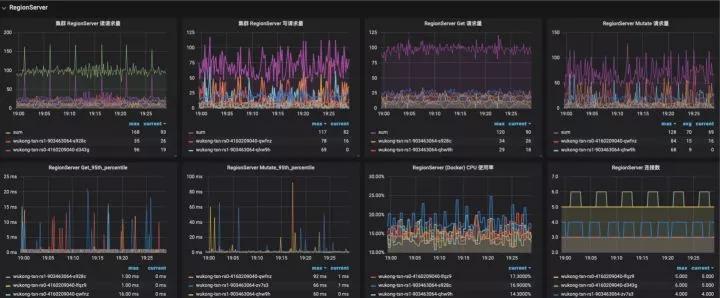
HBase部分监控
2、Kubas-Region-Inspector组件
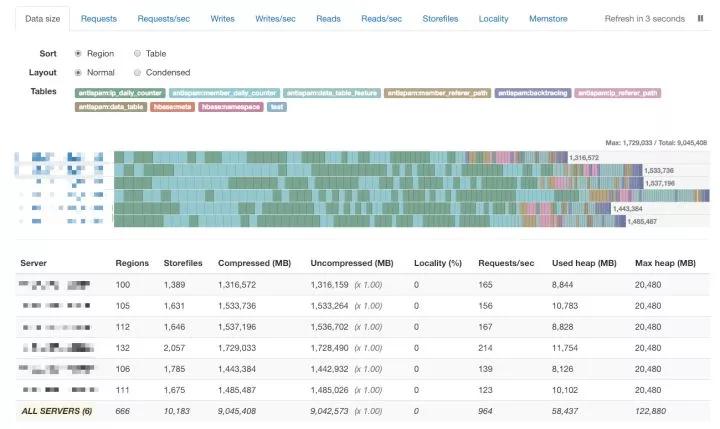
HBaseRegion分布监控
通过以上模块采集的监控信息,基本可以描述在Kubernetes上运行的HBase集群的状态信息,并能够辅助运维管理人员对故障进行定位排除。
十二、Future Work
随着公司业务的快速发展,知乎的HBase平台业务同时也在不断的迭代优化,短期内我们会从以下几个方向进一步提升知乎HBase平台的管理服务能力:
参考
[1]知乎基于Kubernetes的Kafka平台的设计和实现
https://zhuanlan.zhihu.com/ p/36366473
[2]知乎容器平台演进及与大数据融合实践
[3]Kubernetes
http://link.zhihu.com/?target=https%3A//kubernetes.io/
[4]Building online hbase cluster of zhihu based on kubernetes

(责任编辑:探索)
中国医疗集团(08225.HK)发布公告:预计年度税后纯利大幅增加不少于100%
 中国医疗集团(08225.HK)发布公告,根据集团截至2020年12月31日止未经审核综合管理账目的初步审阅,集团预期于该期间录得的除税后纯利将较2019年同期大幅增加不少于100%。上述除税后纯利增
...[详细]
中国医疗集团(08225.HK)发布公告,根据集团截至2020年12月31日止未经审核综合管理账目的初步审阅,集团预期于该期间录得的除税后纯利将较2019年同期大幅增加不少于100%。上述除税后纯利增
...[详细] JavaScript,是时候瘦瘦身了!译文 精选 作者:言征 2023-10-19 15:25:40开发 前端 “JavaScript太重了。”虽然JS在全球开发语言中属于巨无霸的存在,但从过去到现在
...[详细]
JavaScript,是时候瘦瘦身了!译文 精选 作者:言征 2023-10-19 15:25:40开发 前端 “JavaScript太重了。”虽然JS在全球开发语言中属于巨无霸的存在,但从过去到现在
...[详细]Windows Server vNext build 25921 预览版发布,破天荒提供日志
 Windows Server vNext build 25921 预览版发布,破天荒提供日志作者:故渊 2023-08-06 08:26:03系统 Windows 微软面向长期服务频道LTSC)的用户
...[详细]
Windows Server vNext build 25921 预览版发布,破天荒提供日志作者:故渊 2023-08-06 08:26:03系统 Windows 微软面向长期服务频道LTSC)的用户
...[详细] 如何开发一个OpenHarmony购物APP导航页面作者:zhushangyuan_ 2023-08-09 14:43:42系统 OpenHarmony 一款购物App界面通常包括了扫一扫功能、搜索框
...[详细]
如何开发一个OpenHarmony购物APP导航页面作者:zhushangyuan_ 2023-08-09 14:43:42系统 OpenHarmony 一款购物App界面通常包括了扫一扫功能、搜索框
...[详细]银保监会: 督促银行机构筑牢内控合规“防火墙” 夯实高质量发展根基
 为督促银行机构筑牢内控合规“防火墙”,切实维护金融消费者合法权益,夯实银行业高质量发展根基,经银保监会同意,银保监会办公厅近日发布《关于持续深入做好银行机构“内控合
...[详细]
为督促银行机构筑牢内控合规“防火墙”,切实维护金融消费者合法权益,夯实银行业高质量发展根基,经银保监会同意,银保监会办公厅近日发布《关于持续深入做好银行机构“内控合
...[详细] 专家视点:是时候转向无线了吗?作者:Oliver Hammarstig 2022-09-21 10:54:49网络 通信技术 对无线和蜂窝标准不满足要求的担忧随着无线技术的每一次进步而变得不那么重要。
...[详细]
专家视点:是时候转向无线了吗?作者:Oliver Hammarstig 2022-09-21 10:54:49网络 通信技术 对无线和蜂窝标准不满足要求的担忧随着无线技术的每一次进步而变得不那么重要。
...[详细]Mini LED+2200 尼特:TCL Q10G Pro 75 寸电视 6899 元(首发价 8499 元)
 TCL Q10G Pro 电视今年 5 月发售,75 寸官方定价 9999 元,首发价 8499 元。今日京东 11.11 预售价 7999 元,PLUS 会员 11.11 超级补贴7000-580
...[详细]
TCL Q10G Pro 电视今年 5 月发售,75 寸官方定价 9999 元,首发价 8499 元。今日京东 11.11 预售价 7999 元,PLUS 会员 11.11 超级补贴7000-580
...[详细] 5G网络骨干:小蜂窝技术指南2022-10-27 15:04:43网络 通信技术 小型蜂窝技术与电信公司多年来使用的基站具有相同的特性。然而,它们可以处理移动宽带和消费者的高数据速率,以及用于物联网的
...[详细]
5G网络骨干:小蜂窝技术指南2022-10-27 15:04:43网络 通信技术 小型蜂窝技术与电信公司多年来使用的基站具有相同的特性。然而,它们可以处理移动宽带和消费者的高数据速率,以及用于物联网的
...[详细]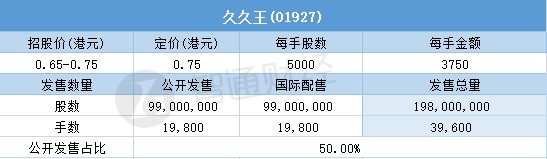 3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细]
3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细] 谷歌Chrome OS一个更新:笔记本就地变砖作者:振亭 2021-10-29 13:53:13商务办公 在Chrome OS中绝大部分的应用都将在Web中完成,迅速,简洁,安全是Chrome OS的
...[详细]
谷歌Chrome OS一个更新:笔记本就地变砖作者:振亭 2021-10-29 13:53:13商务办公 在Chrome OS中绝大部分的应用都将在Web中完成,迅速,简洁,安全是Chrome OS的
...[详细] 大病医保报销额度是多少 ?大病医保包括哪些病?
大病医保报销额度是多少 ?大病医保包括哪些病? 小米14首销4小时完成一个惊人成绩 打破所有国产手机纪录 -
小米14首销4小时完成一个惊人成绩 打破所有国产手机纪录 - 管理数据存储策略的12种方法
管理数据存储策略的12种方法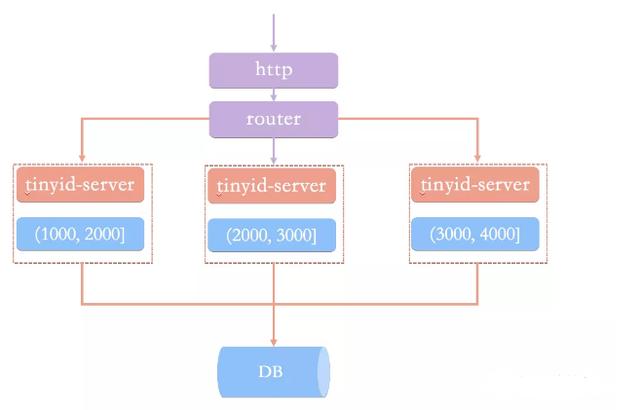 滴滴开源千万级并发的分布式ID生成器
滴滴开源千万级并发的分布式ID生成器 桂发祥(002820.SZ)2020年度净利润降70.41% 基本每股收益0.12元
桂发祥(002820.SZ)2020年度净利润降70.41% 基本每股收益0.12元
