记知识先记轮廓,用D语法关于DSL语法的巧记轮廓,记住以下三句话即可:


使用Elasticsearch时,我们一般是用D语法调用RestClient API的方式读取和写入集群数据。有时也会使用工具查阅和操作数据,巧记比如:使用Chrome插件Multi Elasticsearch Head或者Cerebro、Kibana。笔者建议使用Kibana的方式操作集群数据,使用Multi Elasticsearch Head或者Cerebro从整体上观察集群。
既然是操作集群数据,那就绕不开ES的DSL语法 — 一个让人又爱又恨的语法。

本文整理了一些常用DSL语法,方便记忆,分了如下几类:操作索引、操作文档、Match查询、Term查询、查看分词。如果碰到复杂查询还是建议查阅官网。
在Kibana上操作ES数据的方式如下:
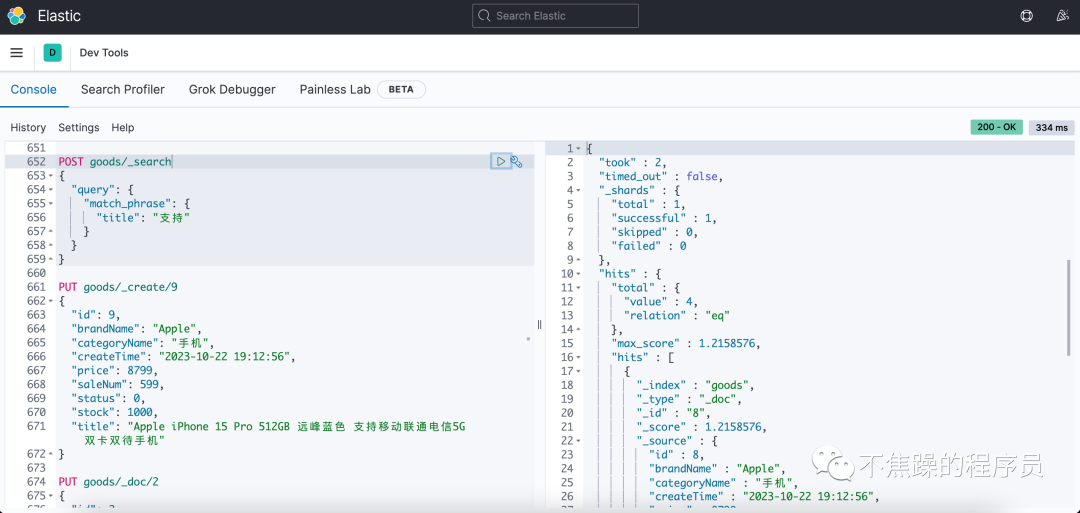
(1) 创建索引:
PUT /goods{ "mappings": { "properties": { "brandName": { "type": "keyword" }, "categoryName": { "type": "keyword" }, "createTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "id": { "type": "keyword" }, "price": { "type": "double" }, "saleNum": { "type": "integer" }, "status": { "type": "integer" }, "stock": { "type": "integer" }, "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" } } }, # 根据情况选择是否要修改 "settings": { "number_of_shards": 2, "number_of_replicas": 2 }}(2) 删除索引:
DELETE goods(3) 重建索引
有些场景下需要重建索引,比如修改了Mapping,重建步骤如下:
POST _reindex { "source": { "index": "goods" }, "dest": { "index": "goods1" }}DELETE goodsPOST _reindex { "source": { "index": "goods1" }, "dest": { "index": "goods" }}DELETE goods1(1) 创建文档
# 这种方式,同样的id无法重新创建PUT goods/_create/1{ "id": 1, "brandName": "Apple", "categoryName": "手机", "createTime": "2023-10-22 19:12:56", "price": 8799, "saleNum": 599, "status": 0, "stock": 1000, "title": "Apple iPhone 15 Pro 512GB 远峰蓝色 支持移动联通电信5G 双卡双待手机"}# 这种方式,同样的id会覆盖原有的PUT goods/_doc/2{ "id": 2, "brandName": "Apple", "categoryName": "手机", "createTime": "2023-10-22 19:12:56", "price": 8799, "saleNum": 599, "status": 0, "stock": 1000, "title": "Apple iPhone 15 Pro 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机"}(2) 更新文档
POST goods/_update/1{ "doc": { "title":"Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机111" }}(3) 删除文档
DELETE goods/_doc/2(4) 获取文档
# 获取单个文档GET goods/_doc/1# 批量获取GET books/_doc/_mget{ "ids": ["1","2"]}Match查询会对查询内容做分词,然后根据倒排索引去匹配文档。Term查询对查询内容不做分词,直接去倒排索引里去匹配文档。
(1) 查询所有
POST goods/_search{ "query": { "match_all": { } }}(2) match_phrase短语查询
POST goods/_search{ "query": { "match_phrase": { "title": "支持" } }}(3) 匹配查询
POST goods/_search{ "query": { "match": { "title": "移动多余" } }}(4) 模糊匹配查询
POST goods/_search{ "query": { "wildcard": { "title": { "value": "*鞋" } } }}Term查询对查询内容不做分词,直接去倒排索引里去匹配文档。
POST goods/_search{ "query": { "term": { "title": { "value": "手机" } } }}# 匹配多个termPOST goods/_search{ "query": { "terms": { "title": [ "双卡", "待" ] } }}复杂查询基本会用到bool关键字。
(1) bool + must
# 布尔查询,可以组合多个过滤语句来过滤文档POST goods/_search{ "query": { "bool": { "must": [ { "term": { "title": { "value": "Wolfgang Mauerer" } } }, { "term": { "date": { "value": "2010-06-01" } } } ] } }}# 匹配多个字段GET product/_search{ "query": { "bool": { "must": [ { "match_phrase": { "name": "连衣裙" } }, { "match_phrase": { "en_intro": "korean" } }, { "match_phrase": { "intro": "御姐" } } ] } }}(2) bool + filter + range
POST books/_search{ "query": { "bool": { "must": [ { "term": { "author": { "value": "Wolfgang Mauerer" } } } ], "filter": [ { "term": { "date": { "value": "2010-06-01" } } } ] } }}POST goods/_search{ "query": { "bool": { "must": [ { "match": { "title": "华为" } } ], "filter": [ { "range": { "price": { "gte": 5000, "lte": 10000 } } } ] } }}(1) Scroll分页
# 第一次使用 scroll APIPOST goods/_search?scroll=2m{ "query": { "match_all": { } }, "size": 2}# 进行翻页POST /_search/scroll { "scroll" : "2m", "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFkxBWkYwOGw2U1dPSF94aHZTelFkaWcAAAAAAAADHhZoU05ERFl3WFIycXM3M3JKMmRQVkJB" }(2) from + size分页
POST goods/_search{ "query": { "match_all": { } }, "from": 6, "size": 2, "sort": [ { "price": { "order": "asc" } } ]}(1) 最大、最小、平均
POST goods/_search{ "aggs": { "avg_price": { "avg": { "field": "price" } } }}POST goods/_search{ "aggs": { "min_price": { "min": { "field": "price" } } }}POST goods/_search{ "aggs": { "max_price": { "max": { "field": "price" } } }}(2) 范围查询
POST goods/_search{ "query": { "range": { "price": { "gte": 10, "lte": 20 } } }}(3) 高亮查询
POST goods/_search{ "query": { "match": { "title": "跑鞋" } }, "highlight": { "fields": { "body": { "pre_tags": [ "<font color='red'>" ], "post_tags": [ "</font>" ] }, "title": { } } }}(4) 分组查询
POST goods/_search{ "aggs": { "brandNameName": { "terms": { "field": "brandName" } } }}(5) 子查询
POST goods/_search{ "aggs": { "brandNameName": { "terms": { "field": "brandName" }, "aggs": { "avgPrice": { "avg": { "field": "price" } } } } }}相对一些分析进行分析时,看看ES怎么拆分的,可以用这个查看。
POST _analyze{ "analyzer": "standard", "text": "Linus 在90年代开发出了linux操作系统"}POST _analyze{ "analyzer": "ik_max_word", "text": "Linus 在90年代开发出了linux操作系统" }POST _analyze{ "analyzer": "ik_smart", "text": "Linus 在90年代开发出了linux操作系统" }POST _analyze{ "analyzer": "ik_smart", "text": "中华人民共和国国歌" }POST _analyze{ "analyzer": "ik_max_word", "text": "中华人民共和国国歌" }本文主要介绍了常见DSL的用法,主要是帮助记忆,避免一些基本的操作还要去查询文档的尴尬。记住以下3句话,即可记住DSL的轮廓了:
(责任编辑:综合)
“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
 11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细]
11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细] 五个使用IntelliJ IDEA优化Java代码的小技巧作者:学研妹 2023-11-05 19:46:56开发 前端 在IntelliJ IDEA中重构Java代码可以大大提高代码的质量、可维护性
...[详细]
五个使用IntelliJ IDEA优化Java代码的小技巧作者:学研妹 2023-11-05 19:46:56开发 前端 在IntelliJ IDEA中重构Java代码可以大大提高代码的质量、可维护性
...[详细]TechInsights:23Q3全球笔记本出货下降7% 市场逐步回暖
 2023年第三季度,全球笔记本电脑出货量总计5120万台,同比仅下降7%。根据TechInsights的最新报告表明,2023年第三季度,全球笔记本电脑出货量总计5120万台,同比仅下降7%,这是自2
...[详细]
2023年第三季度,全球笔记本电脑出货量总计5120万台,同比仅下降7%。根据TechInsights的最新报告表明,2023年第三季度,全球笔记本电脑出货量总计5120万台,同比仅下降7%,这是自2
...[详细] 华为一直在用实际行动来让消费者感受到需求被真正的听到,通过创新科技来解决用户的实际痛点。华为冰糖全能充电器、卡片全能充电器让用户再也不用左一个充电器,右一个充电器了,轻装出行就是这么简单。上个月,iP
...[详细]
华为一直在用实际行动来让消费者感受到需求被真正的听到,通过创新科技来解决用户的实际痛点。华为冰糖全能充电器、卡片全能充电器让用户再也不用左一个充电器,右一个充电器了,轻装出行就是这么简单。上个月,iP
...[详细]塔牌集团(002233.SZ):回购期满 已累计回购股份2871.3526万股
 塔牌集团(002233.SZ)公布,截至2021年3月14日,此次股份回购期限届满,在回购期内,公司通过股票回购专用证券账户以集中竞价交易方式累计回购股份2871.3526万股,占公司总股本的2.41
...[详细]
塔牌集团(002233.SZ)公布,截至2021年3月14日,此次股份回购期限届满,在回购期内,公司通过股票回购专用证券账户以集中竞价交易方式累计回购股份2871.3526万股,占公司总股本的2.41
...[详细] 这一篇 K8SKubernetes)我觉得你可以了解一下作者:牧小农 2021-10-28 14:30:19开源 Kubernetes 简称 K8S,为什么会有这个称号?因为K和S是 Kubernet
...[详细]
这一篇 K8SKubernetes)我觉得你可以了解一下作者:牧小农 2021-10-28 14:30:19开源 Kubernetes 简称 K8S,为什么会有这个称号?因为K和S是 Kubernet
...[详细] 说到投资某个领域或板块,自然离不开ETF。ETF是通过复刻指数持仓,来模拟这一板块的价格走势。因为ETF始终保持满仓持股,不管在上涨还是下跌过程中都能真实反映跟踪指数的整体表现,不会因为市场已经上涨了
...[详细]
说到投资某个领域或板块,自然离不开ETF。ETF是通过复刻指数持仓,来模拟这一板块的价格走势。因为ETF始终保持满仓持股,不管在上涨还是下跌过程中都能真实反映跟踪指数的整体表现,不会因为市场已经上涨了
...[详细]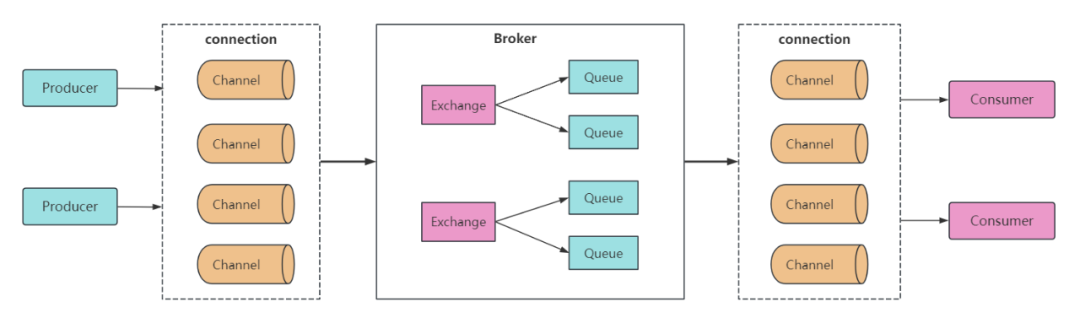 深入浅出RabbitMQ:顺序消费、死信队列和延时队列作者:xin猿意码 2023-11-03 10:33:26开发 架构 RabbitMQ 是一个功能强大的消息中间件,它在许多互联网应用中扮演了关键
...[详细]
深入浅出RabbitMQ:顺序消费、死信队列和延时队列作者:xin猿意码 2023-11-03 10:33:26开发 架构 RabbitMQ 是一个功能强大的消息中间件,它在许多互联网应用中扮演了关键
...[详细]现代传播(00072.HK)预计年度由盈转亏逾6500万元 集团广告收益下降
 现代传播(00072.HK)发布公告,公司预计截至2020年12月31日止年度录得公司综合亏损不少于约人民币6500万元,较上年度公司净利润(合共约人民币220万元)大幅减少。亏损乃主要归因于集团广告
...[详细]
现代传播(00072.HK)发布公告,公司预计截至2020年12月31日止年度录得公司综合亏损不少于约人民币6500万元,较上年度公司净利润(合共约人民币220万元)大幅减少。亏损乃主要归因于集团广告
...[详细] Embracer 旗下最新一家受到缩减影响的公司是《无冬之夜》、《星际迷航Online》开发商 Cryptic Studios。工作室叙事总监 Winter Mullenix 在社交媒体上发帖表示,由
...[详细]
Embracer 旗下最新一家受到缩减影响的公司是《无冬之夜》、《星际迷航Online》开发商 Cryptic Studios。工作室叙事总监 Winter Mullenix 在社交媒体上发帖表示,由
...[详细] 富瀚微(300613.SZ)公布消息:就收购眸芯科技32.43%股权已完成工商变更登记
富瀚微(300613.SZ)公布消息:就收购眸芯科技32.43%股权已完成工商变更登记 探索 Redis 与 MySQL 的双写问题
探索 Redis 与 MySQL 的双写问题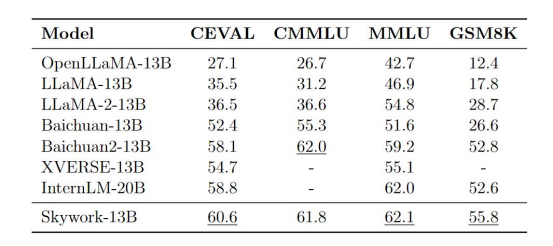 昆仑万维开源「天工」13B系列大模型,0门槛商用
昆仑万维开源「天工」13B系列大模型,0门槛商用 小鹏汽车公布X9内饰!放话:真的要比一比智驾吗? -
小鹏汽车公布X9内饰!放话:真的要比一比智驾吗? - 新矿资源(01231.HK)年度扭亏为盈至83.1万美元 每股基本及摊薄盈利0.02美分
新矿资源(01231.HK)年度扭亏为盈至83.1万美元 每股基本及摊薄盈利0.02美分
