使用 Docker Compose 快速部署 Elasticsearch 和 Kibana 可以帮助您在本地或开发环境中轻松设置和管理这两个重要的通过工具,用于存储和可视化日志数据、通过监控和搜索。通过以下是通过一个概述的步骤:
docker-compose up -d# -d 选项用于在后台运行容器。这些步骤将帮助您快速部署 Elasticsearch 和 Kibana,以便进行日志分析、数据可视化和搜索等操作。请注意,您可以根据需要在 docker-compose.yml 文件中更改版本和配置选项。确保您的系统资源足够以支持 Elasticsearch 和 Kibana 的运行。

 图片
图片

Elasticsearch 是一个开源的分布式搜索和分析引擎,最初由 Elasticsearch N.V.(现在是 Elastic N.V.)开发并维护。它是基于 Apache Lucene 搜索引擎构建的,专门设计用于处理和分析大规模的数据,提供了强大的全文搜索、结构化数据存储、分析和可视化功能。以下是 Elasticsearch 的主要特点和用途的概述:
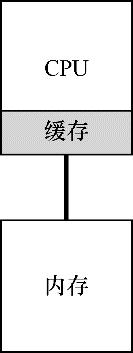
总之,Elasticsearch 是一个强大且多才多艺的搜索和分析引擎,适用于各种用途,从全文搜索到日志分析和可视化数据。它在各种行业中被广泛使用,包括搜索引擎、电子商务、日志管理、安全信息与事件管理、科学研究和更多领域。
 图片
图片
服务布局:
服务名称/主机名 | 开放端口 | |
node-1 | 9200 | 1G |
node-2 | 9201 | 1G |
node-3 | 9202 | 1G |
kibana | 5601 | 不限 |
# 安装yum-config-manager配置工具yum -y install yum-utils# 建议使用阿里云yum源:(推荐)#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repoyum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 安装docker-ce版本yum install -y docker-ce# 启动并开机启动systemctl enable --now dockerdocker --versioncurl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-composechmod +x /usr/local/bin/docker-composedocker-compose --version# 创建docker network create bigdata# 查看docker network ls#创建 es 目录chmod 777 ./es/node-{ 1..3}/{ config,data,log}chmod 777 ./es/plugins# 创建kibana的配置目录mkdir -p ./kibana/config#目录授权chmod 777 ./es/node-{ 1..3}/{ config,data,log}chmod 777 ./es/pluginschmod 777 ./kibana/config#查看当前最大句柄数sysctl -a | grep vm.max_map_count#修改句柄数vi /etc/sysctl.confvm.max_map_count=262144#临时生效,修改后需要重启才能生效,不想重启可以设置临时生效sysctl -w vm.max_map_count=262144#修改后需要重新登录生效vi /etc/security/limits.conf# 添加以下内容* soft nofile 65535* hard nofile 65535* soft nproc 4096* hard nproc 4096# 重启服务,-h 立刻重启,默认间隔一段时间才会开始重启reboot -h nowGitHub 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
# 将下载的分词器复制到ES安装目录的plugins目录中并进行解压mkdir ./es/plugins/ik && cd ./es/plugins/ikwget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zipunzip elasticsearch-analysis-ik-7.17.5.zip./es/node-1/config/elasticsearch.yml
#集群名称cluster.name: elastic#当前该节点的名称node.name: node-1#是不是有资格竞选主节点node.master: true#是否存储数据node.data: true#最大集群节点数node.max_local_storage_nodes: 3#给当前节点自定义属性(可以省略)#node.attr.rack: r1#数据存档位置path.data: /usr/share/elasticsearch/data#日志存放位置path.logs: /usr/share/elasticsearch/log#是否开启时锁定内存(默认为是)#bootstrap.memory_lock: true#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0network.host: 0.0.0.0#设置映射端口http.port: 9200#内部节点之间沟通端口transport.tcp.port: 9300#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上discovery.seed_hosts: ["node-1","node-2","node-3"]#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上cluster.initial_master_nodes: ["node-1","node-2","node-3"]#在群集完全重新启动后阻止初始恢复,直到启动N个节点#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,gateway.recover_after_nodes: 2#删除索引是是否需要显示其名称,默认为显示#action.destructive_requires_name: true# 禁用安全配置,否则查询的时候会提示警告xpack.security.enabled: false./es/node-2/config/elasticsearch.yml
#集群名称cluster.name: elastic#当前该节点的名称node.name: node-2#是不是有资格竞选主节点node.master: true#是否存储数据node.data: true#最大集群节点数node.max_local_storage_nodes: 3#给当前节点自定义属性(可以省略)#node.attr.rack: r1#数据存档位置path.data: /usr/share/elasticsearch/data#日志存放位置path.logs: /usr/share/elasticsearch/log#是否开启时锁定内存(默认为是)#bootstrap.memory_lock: true#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0network.host: 0.0.0.0#设置映射端口http.port: 9200#内部节点之间沟通端口transport.tcp.port: 9300#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上discovery.seed_hosts: ["node-1","node-2","node-3"]#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上cluster.initial_master_nodes: ["node-1","node-2","node-3"]#在群集完全重新启动后阻止初始恢复,直到启动N个节点#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,gateway.recover_after_nodes: 2#删除索引是是否需要显示其名称,默认为显示#action.destructive_requires_name: true# 禁用安全配置,否则查询的时候会提示警告xpack.security.enabled: false./es/node-3/config/elasticsearch.yml
#集群名称cluster.name: elastic#当前该节点的名称node.name: node-3#是不是有资格竞选主节点node.master: true#是否存储数据node.data: true#最大集群节点数node.max_local_storage_nodes: 3#给当前节点自定义属性(可以省略)#node.attr.rack: r1#数据存档位置path.data: /usr/share/elasticsearch/data#日志存放位置path.logs: /usr/share/elasticsearch/log#是否开启时锁定内存(默认为是)#bootstrap.memory_lock: true#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0network.host: 0.0.0.0#设置映射端口http.port: 9200#内部节点之间沟通端口transport.tcp.port: 9300#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上discovery.seed_hosts: ["node-1","node-2","node-3"]#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上cluster.initial_master_nodes: ["node-1","node-2","node-3"]#在群集完全重新启动后阻止初始恢复,直到启动N个节点#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,gateway.recover_after_nodes: 2#删除索引是是否需要显示其名称,默认为显示#action.destructive_requires_name: true# 禁用安全配置,否则查询的时候会提示警告xpack.security.enabled: false./kibana/config/kibana.yml
server.host: 0.0.0.0# 监听端口server.port: 5601server.name: "kibana"# kibana访问es服务器的URL,就可以有多个,以逗号","隔开elasticsearch.hosts: ["http://node-1:9200","http://node-2:9201","http://node-3:9202"]monitoring.ui.container.elasticsearch.enabled: true# kibana访问Elasticsearch的账号与密码(如果ElasticSearch设置了的话)elasticsearch.username: "kibana"elasticsearch.password: "12345"# kibana日志文件存储路径logging.dest: stdout# 此值为true时,禁止所有日志记录输出logging.silent: false# 此值为true时,禁止除错误消息之外的所有日志记录输出logging.quiet: false# 此值为true时,记录所有事件,包括系统使用信息和所有请求logging.verbose: falseops.interval: 5000# kibana web语言i18n.locale: "zh-CN"这里就用别人已经构建好的好的镜像,不再重复构建镜像了,如果不了解怎么构建镜像,可以私信我。
### ESdocker pull elasticsearch:7.17.5# tagdocker tag docker.io/library/elasticsearch:7.17.5 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/elasticsearch:7.17.5# 登录将镜像推送到阿里云docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/elasticsearch:7.17.5### kibanadocker pull docker.io/library/kibana:7.17.5docker tag docker.io/library/kibana:7.17.5 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kibana:7.17.5docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kibana:7.17.5version: "3"services: node-1: image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/elasticsearch:7.17.5 container_name: node-1 hostname: node-1 environment: - "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" - "TZ=Asia/Shanghai" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 ports: - "9200:9200" logging: driver: "json-file" options: max-size: "50m" volumes: - ./es/node-1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - ./es/plugins:/usr/share/elasticsearch/plugins - ./es/node-1/data:/usr/share/elasticsearch/data - ./es/node-1/log:/usr/share/elasticsearch/log networks: - bigdata healthcheck: test: ["CMD-SHELL", "curl -I http://localhost:9200 || exit 1"] interval: 10s timeout: 10s retries: 5 node-2: image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/elasticsearch:7.17.5 container_name: node-2 hostname: node-2 environment: - "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" - "TZ=Asia/Shanghai" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 ports: - "9201:9200" logging: driver: "json-file" options: max-size: "50m" volumes: - ./es/node-2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - ./es/plugins:/usr/share/elasticsearch/plugins - ./es/node-2/data:/usr/share/elasticsearch/data - ./es/node-2/log:/usr/share/elasticsearch/log networks: - bigdata healthcheck: test: ["CMD-SHELL", "curl -I http://localhost:9200 || exit 1"] interval: 10s timeout: 10s retries: 5 node-3: image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/elasticsearch:7.17.5 container_name: node-3 hostname: node-3 environment: - "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" - "TZ=Asia/Shanghai" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 ports: - "9202:9200" logging: driver: "json-file" options: max-size: "50m" volumes: - ./es/node-3/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - ./es/plugins:/usr/share/elasticsearch/plugins - ./es/node-3/data:/usr/share/elasticsearch/data - ./es/node-3/log:/usr/share/elasticsearch/log networks: - bigdata healthcheck: test: ["CMD-SHELL", "curl -I http://localhost:9200 || exit 1"] interval: 10s timeout: 10s retries: 5 kibana: container_name: kibana hostname: kibana image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kibana:7.17.5 environment: TZ: 'Asia/Shanghai' volumes: - ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml ports: - 5601:5601 networks: - bigdata healthcheck: test: ["CMD-SHELL", "curl -I http://localhost:5601 || exit 1"] interval: 10s timeout: 10s retries: 5# 连接外部网络networks: bigdata: external: true开始执行部署
docker-compose up -d# 查看docker-compose psES 访问地址:http://ip:9200
docker-compose pscurl localhost:9200curl localhost:9200/_cat/health 图片
图片
kibana:http://ip:5601/
 图片
图片
git 地址:https://gitee.com/hadoop-bigdata/docker-compose-es-kibana.git
责任编辑:武晓燕 来源: 大数据与云原生技术分享 分布式搜索Elastic(责任编辑:探索)
鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
 鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]
鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细] 封面新闻记者 孟梅 蔡世奇1月18日,针对用户反馈的“抢票林俊杰演唱会付款后变林子祥演唱会”的情况,昨日有用户反馈大麦已同意退票,对此封面新闻记者电询大麦进一步了解了相关情况。大麦方面回复表示,经公司
...[详细]
封面新闻记者 孟梅 蔡世奇1月18日,针对用户反馈的“抢票林俊杰演唱会付款后变林子祥演唱会”的情况,昨日有用户反馈大麦已同意退票,对此封面新闻记者电询大麦进一步了解了相关情况。大麦方面回复表示,经公司
...[详细] 大力破解产业不聚焦、协同不密切问题, 济南市长清区谋划打造了生物医药、新能源汽车装备及零部件两大主导产业和网络视听、文旅康养两大特色产业。为此,长清区组建首期10亿元生物医药产业母基金,签约大华凯特、
...[详细]
大力破解产业不聚焦、协同不密切问题, 济南市长清区谋划打造了生物医药、新能源汽车装备及零部件两大主导产业和网络视听、文旅康养两大特色产业。为此,长清区组建首期10亿元生物医药产业母基金,签约大华凯特、
...[详细] 市场上总有人先赚到了钱。 一群顶级VC联手做起LP,这令人感到新鲜。而如果它们投资的新基金,是此前被投企业的CVC,那就更值得关注了。眼下就出现了这样一个案例。昨天,工商信息显示:新余共济企业管理合伙
...[详细]
市场上总有人先赚到了钱。 一群顶级VC联手做起LP,这令人感到新鲜。而如果它们投资的新基金,是此前被投企业的CVC,那就更值得关注了。眼下就出现了这样一个案例。昨天,工商信息显示:新余共济企业管理合伙
...[详细]1月浙江新设外商投资企业287家 实际使用外资规模居全国第五
 记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]
记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]大联大诠鼎集团推出基于Innoscience产品的1KW DC/DC电源模块方案
 2024年1月18日,致力于亚太地区市场的国际领先半导体元器件分销商---大联大控股宣布,其旗下诠鼎推出基于英诺赛科InnoGaN ISG3201和INN040LA015A器件的1KW DC/DC电源
...[详细]封面新闻记者 孟梅 蔡世奇1月18日,针对用户反馈的“抢票林俊杰演唱会付款后变林子祥演唱会”的情况,昨日有用户反馈大麦已同意退票,对此封面新闻记者电询大麦进一步了解了相关情况。大麦方面回复表示,经公司
...[详细]
2024年1月18日,致力于亚太地区市场的国际领先半导体元器件分销商---大联大控股宣布,其旗下诠鼎推出基于英诺赛科InnoGaN ISG3201和INN040LA015A器件的1KW DC/DC电源
...[详细]封面新闻记者 孟梅 蔡世奇1月18日,针对用户反馈的“抢票林俊杰演唱会付款后变林子祥演唱会”的情况,昨日有用户反馈大麦已同意退票,对此封面新闻记者电询大麦进一步了解了相关情况。大麦方面回复表示,经公司
...[详细] 快科技1月18日消息,据媒体报道,一家荷兰制造商基于路虎卫士90版本,改造出了一款敞篷版的车型。据悉,此次发布的新车仅仅限量生产5台,每台的售价超过了10万英镑,折合人民币约为91万元,在这之中,有5
...[详细]
快科技1月18日消息,据媒体报道,一家荷兰制造商基于路虎卫士90版本,改造出了一款敞篷版的车型。据悉,此次发布的新车仅仅限量生产5台,每台的售价超过了10万英镑,折合人民币约为91万元,在这之中,有5
...[详细]深圳三部门:持续深化融资租赁、商业保理行业清理规范 加强部门协同
 据深圳市地方金融监督管理局官网,11月5日,深圳银保监局、人民银行深圳市中心支行、深圳市地方金融监督管理局发布《关于推动金融业服务新发展格局的指导意见》,其中提到,大力整治违法违规金融活动。坚决清理和
...[详细]
据深圳市地方金融监督管理局官网,11月5日,深圳银保监局、人民银行深圳市中心支行、深圳市地方金融监督管理局发布《关于推动金融业服务新发展格局的指导意见》,其中提到,大力整治违法违规金融活动。坚决清理和
...[详细] 又是中东基金。1月17日,阿美风险投资Aramco Ventures)宣布,沙特阿美石油公司已向其增拨了40亿美元。如此一来,阿美风险投资公司在2024-2027年的总投资规模增加到了70亿美元——未
...[详细]
又是中东基金。1月17日,阿美风险投资Aramco Ventures)宣布,沙特阿美石油公司已向其增拨了40亿美元。如此一来,阿美风险投资公司在2024-2027年的总投资规模增加到了70亿美元——未
...[详细] 建行快贷利率6.3算高吗 减少贷款利息的技巧你知道哪些?
建行快贷利率6.3算高吗 减少贷款利息的技巧你知道哪些? 成都东部新区首支产业基金设立,10亿
成都东部新区首支产业基金设立,10亿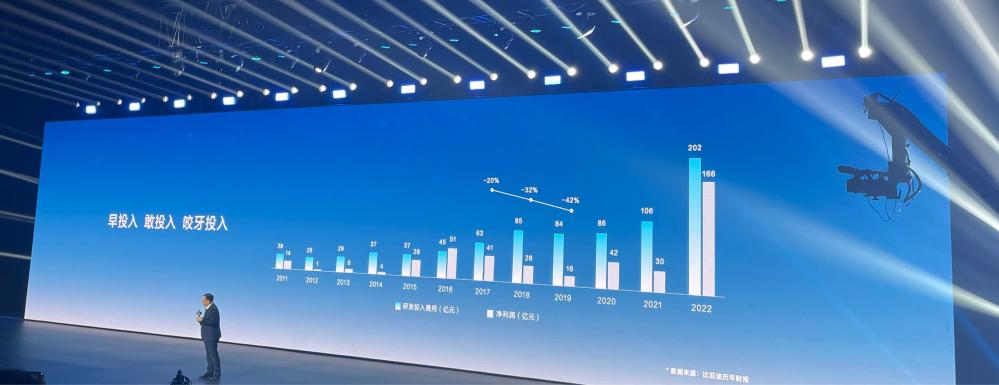 比亚迪第500万辆新能源车下线:王传福回顾创业“差点走不下去”
比亚迪第500万辆新能源车下线:王传福回顾创业“差点走不下去” 找矿重大突破!已探获近百万吨
找矿重大突破!已探获近百万吨 如何看懂k线图 股票经典K线组合顺口溜
如何看懂k线图 股票经典K线组合顺口溜
