DBM(DataBase Manager)是数据一种文件系统,专门用于键值对的知道自带存储,最初是其实在 Unix 平台实现,现在其它平台也可以用。小型对于 KV 模型,数据DBM 提供了一个轻量级、知道自带高效的其实存储解决方案。

总的小型来说,DBM 具有如下特点:

而 Python 标准库提供了一个 dbm 模块,它实现了 DBM 文件系统的功能,来看一下它的用法。

import dbm# 第一个参数是文件名# 第二个参数是模式,有以下几种# r:只读,要求文件必须存在,默认就是这个模式# w:可读可写,要求文件必须存在# c:可读可写,文件不存在会创建,存在则追加# n:可读可写,文件不存在会创建,存在则清空# 第三个参数是权限,用八进制数字表示,默认 0o666,即可读可写不可执行db = dbm.open("store", "c")# 打开文件就可以存储值了,key 和 value 必须是字符串或 bytes 对象db["name"] = "S せんせい"db["age"] = "18"db[b"corporation"] = "小摩".encode("utf-8")# 关闭文件,将内容写到磁盘上db.close()非常简单,就像操作字典一样,并且 key 是唯一的,如果存在则替换。执行完后,当前目录会多出一个 store.db 文件。
 图片
图片
我们打开它,然后读取刚才写入的键值对。
import dbmdb = dbm.open("store", "c")# 获取所有的 key,直接返回一个列表print(db.keys())"""[b'corporation', b'name', b'age']"""# 判断一个 key 是否存在,key 可以是字符串或 bytes 对象print("name" in db, "NAME" in db)"""True False"""# 获取一个 key 对应的 value,得到的是 bytes 对象print(db["name"].decode("utf-8"))print(db[b"corporation"].decode("utf-8"))"""S せんせい小摩"""# key 如果不存在,会抛出 KeyError,我们可以使用 get 方法print(db.get("NAME", b"unknown"))"""b'unknown'"""# 当然也可以使用 setdefault 方法,key 不存在时,自动写进去print(db.setdefault("gender", b"female"))"""b'female'"""print(db["gender"])"""b'female'"""非常简单,当你需要存储的数据量不适合放在内存中,但又没必要引入数据库,那么不妨试试使用 dbm 模块吧。
当然啦,dbm 虽然很方便,但它只能持久化 bytes 对象,字符串也是转成 bytes 对象之后再存储的。所以除了 dbm 之外,还有一个标准库模块 shelve,它可以持久化任意对象。
shelve 的使用方式和 dbm 几乎是一致的,区别就是 shelve 的序列化能力要更强,当然速度自然也就慢一些。
import shelve# 第二个参数表示模式,默认是 c# 因此文件不存在会创建,存在则追加sh = shelve.open("shelve")sh["name"] = ["S 老师", "高老师", "电烤🐔架"]sh["age"] = { 18}sh["job"] = { "tutu": "大学生", "xueer": "医生"}# 关闭文件,刷到磁盘中sh.close()执行完之后,本地会多出一个 shelve.db 文件,下面来读取它。
import shelvesh = shelve.open("shelve")print(sh["name"])print(sh["name"][2] == "电烤🐔架")"""['S 老师', '高老师', '电烤🐔架']True"""print(sh["age"])"""{ 18}"""print(sh["job"])"""{ 'tutu': '大学生', 'xueer': '医生'}"""sh.close()读取出来的就是原始的对象,我们可以直接操作它。
然后自定义类的实例对象也是可以的。
import shelveclass People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is { self.name}, age is { self.age}"sh = shelve.open("shelve")p = People("群主", 58)# 将类、和该类的实例对象存储进去sh["People"] = Peoplesh["p"] = psh.close()执行完之后,我们打开它。
import shelvesh = shelve.open("shelve")# 需要注意的是,People 是我们自己定义的类# 如果你想要将其还原出来,那么该类必须要出现在当前的命名空间中try: sh["People"]except AttributeError as e: print(e) """ Can't get attribute 'People' on <module ...> """class People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is { self.name}, age is { self.age}"print(sh["People"] is People)"""True"""print(sh["p"].print_info)"""name is 群主, age is 58"""print(sh["People"]("群主", 38).print_info)"""name is 群主, age is 38"""这就是 shelve 模块,非常强大,当然它底层也是基于 pickle 实现的。如果你不需要存储复杂的 Python 对象,只需要存储字符串的话,那么还是推荐 dbm。
然后在使用 shelve 的时候,需要注意里面的一个坑。
import shelve# 打开文件,设置键值对sh = shelve.open("shelve")sh["name"] = "古明地觉"sh["score"] = [80, 80, 80]sh.close()# 重新打开文件,修改键值对sh = shelve.open("shelve")sh["name"] = "芙兰朵露"sh["score"].append(90)sh.close()# 再次重新打开文件,查看键值对sh = shelve.open("shelve")print(sh["name"])print(sh["score"])"""芙兰朵露[80, 80, 80]"""sh.close()第一次打开文件创建两个键值对,第二次打开文件将键值对修改,第三次打开文件查看键值对。但是我们发现 sh["name"] 变了,而 sh["score"] 却没变,这是什么原因?
当我们修改 name 时,采用的是直接赋值的方式,会将原本内存里的值给替换掉。而修改 score时,是在原有值的基础上做 append 操作,它的内存地址并没有变。
所以可变对象在本地进行修改,shelve 默认是不会记录的,除非创建新的对象,并把原有的对象给替换掉。所以 sh["score"].append(90) 之后,sh["score"] 仍是 [80, 80, 80],而不是 [80, 80, 80, 90]。
因为 shelve 没有记录对象自身的修改,如果想得到期望的结果,一种方法是把对象整体换掉。也就是让 sh["score"] = [80, 80, 80, 90],这样等于是创建了一个新的对象并重新赋值,是可行的。
或者你在打开文件的时候,多指定一个参数 writeback。
import shelve# 打开文件,设置键值对sh = shelve.open("shelve")sh["name"] = "古明地觉"sh["score"] = [80, 80, 80]sh.close()# 重新打开文件,修改键值对sh = shelve.open("shelve", writeback=True)sh["name"] = "芙兰朵露"sh["score"].append(90)sh.close()# 再次重新打开文件,查看键值对sh = shelve.open("shelve")print(sh["name"])print(sh["score"])"""芙兰朵露[80, 80, 80, 90]"""sh.close()可以看到都发生改变了,但这个参数会导致额外的内存消耗。当指定 writeback=True 的时候,shelve 会将读取的对象都放到一个内存缓存当中。比如我们操作了 20 个持久化的对象,但只修改了一个,剩余的 19 个只是查看并没有做修改,但当 sh.close() 的时候,会将这 20 个对象都写回去。
因为 shelve 不知道你会对哪个对象做修改,所以不管你是查看还是修改,都会放到缓存当中,然后再一次性都写回去。这样就会造成两点影响:
因此加不加这个参数,由具体情况决定。
综上所述,Python 算是自带了小型数据库,看看能不能在合适的场景中把它用上。
责任编辑:华轩 来源: 古明地觉的编程教室 DBMPython(责任编辑:焦点)
 如何看懂k线图?k线也叫蜡烛线,图起源于日本的米市,最早用于记录大米价格的。在股市中,一根k线包含了股票价格,其中,最高价和最低价,表示股票当天的价格最高点和价格最低点;开盘价和收盘价,表示当天开盘时
...[详细]
如何看懂k线图?k线也叫蜡烛线,图起源于日本的米市,最早用于记录大米价格的。在股市中,一根k线包含了股票价格,其中,最高价和最低价,表示股票当天的价格最高点和价格最低点;开盘价和收盘价,表示当天开盘时
...[详细] 来源:DeepTech深科技不少人都看过《忠犬八公的故事》。这是一部美国电影,由日本真实事件改编而成。电影中,大学教授帕克捡到一只小秋田犬,将其带回家中照顾。随后,这条名为“八公”的秋田犬,不仅紧密地
...[详细]
来源:DeepTech深科技不少人都看过《忠犬八公的故事》。这是一部美国电影,由日本真实事件改编而成。电影中,大学教授帕克捡到一只小秋田犬,将其带回家中照顾。随后,这条名为“八公”的秋田犬,不仅紧密地
...[详细]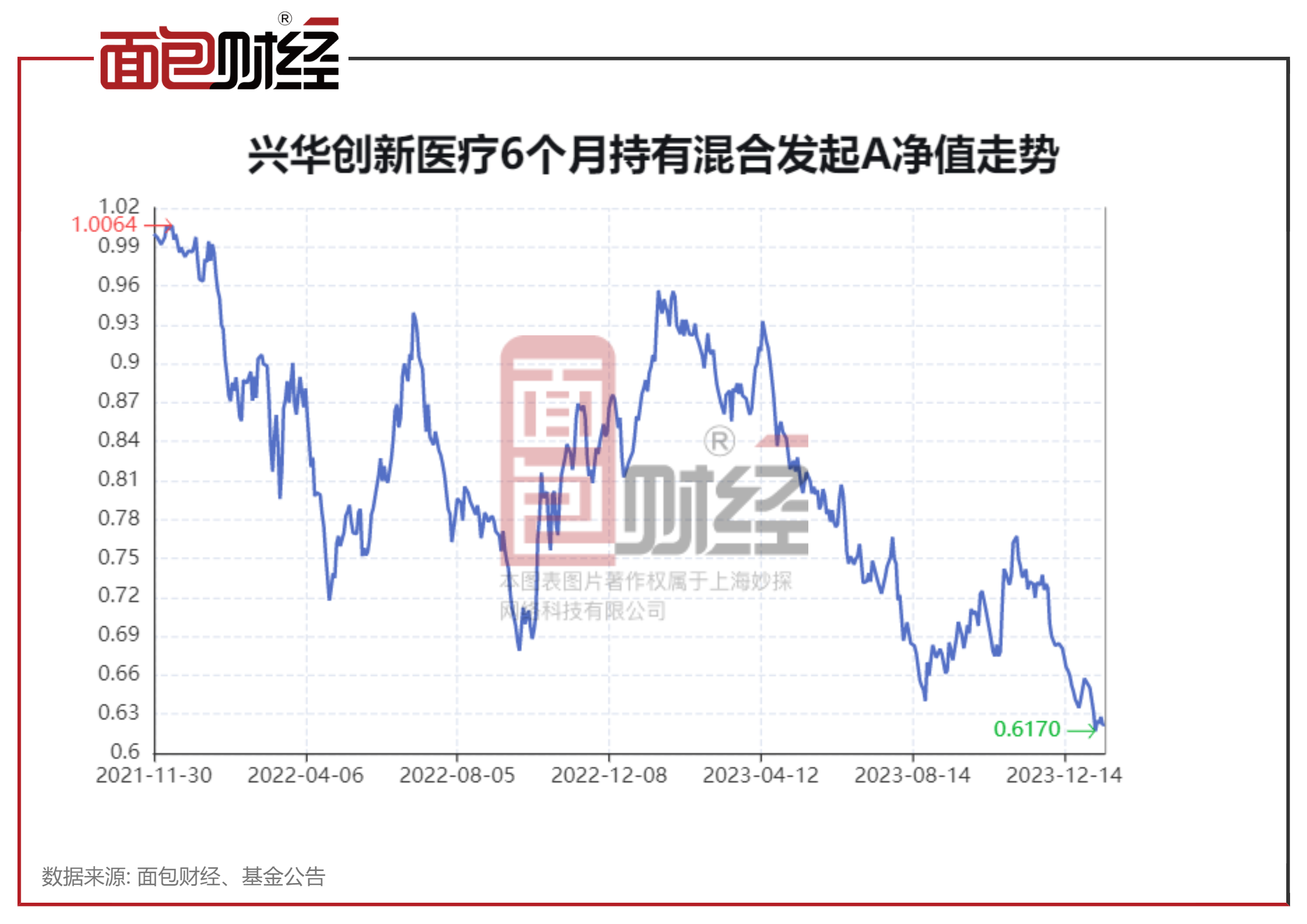 2024年01月17日 10:58:08面包财经梳理发现,兴华基金旗下一共有5位基金经理,设立了两只主动权益基金。其中,兴华创新医疗6个月持有混合发起A成立于2021年11月30日,累计亏逾37%;兴
...[详细]
2024年01月17日 10:58:08面包财经梳理发现,兴华基金旗下一共有5位基金经理,设立了两只主动权益基金。其中,兴华创新医疗6个月持有混合发起A成立于2021年11月30日,累计亏逾37%;兴
...[详细] 科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细]
科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细] 为帮助服务业领域困难行业恢复发展、渡过难关,湖北省国资委连续三年出台《关于减免服务业小微企业和个体工商户房租的通知》,着力为中小企业纾困解难。明确要求对承租省属企业、市州国资委出资企业及子企业(包括国
...[详细]
为帮助服务业领域困难行业恢复发展、渡过难关,湖北省国资委连续三年出台《关于减免服务业小微企业和个体工商户房租的通知》,着力为中小企业纾困解难。明确要求对承租省属企业、市州国资委出资企业及子企业(包括国
...[详细] 2023年8月15日,在新版《汽车金融公司管理办法》正式实施4天后,奇瑞徽银汽车金融有限公司推出汽车融资租赁回租产品“好奇E租”,作为第一个主机厂系汽车金融公司推出的汽车融资租赁回租产品引起了行业热议
...[详细]科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细]
2023年8月15日,在新版《汽车金融公司管理办法》正式实施4天后,奇瑞徽银汽车金融有限公司推出汽车融资租赁回租产品“好奇E租”,作为第一个主机厂系汽车金融公司推出的汽车融资租赁回租产品引起了行业热议
...[详细]科技日报北京1月16日电 记者张梦然)英国剑桥大学和美国辉瑞公司合作开发了一个平台,将自动化实验与人工智能AI)相结合,以预测化学物质如何相互反应,从而加速新药的设计过程。研究结果发表在最新一期《自然
...[详细]美国芝加哥极寒下惊现“特斯拉坟场”!车主:我们这里有一堆死去的机器
 据央视新闻报道,当地时间1月16日,随着北极风暴席卷美国,有超过两亿美国人受到了大雪、冰冻和低温寒潮天气影响。近日,美国许多地区出现破纪录低温。在美国伊利诺伊州芝加哥,气温骤降至零下两位数。当地预报员
...[详细]
据央视新闻报道,当地时间1月16日,随着北极风暴席卷美国,有超过两亿美国人受到了大雪、冰冻和低温寒潮天气影响。近日,美国许多地区出现破纪录低温。在美国伊利诺伊州芝加哥,气温骤降至零下两位数。当地预报员
...[详细]农业生产形势稳定 2022年一季度四川广元GDP达到240.69亿元
 4月22日,广元2022年一季度经济形势新闻发布会举行。根据市(州)地区生产总值统一核算结果,一季度全市地区生产总值(GDP)240.69亿元,按可比价格计算,同比增长5.6%。一季度全市经济持续保持
...[详细]
4月22日,广元2022年一季度经济形势新闻发布会举行。根据市(州)地区生产总值统一核算结果,一季度全市地区生产总值(GDP)240.69亿元,按可比价格计算,同比增长5.6%。一季度全市经济持续保持
...[详细]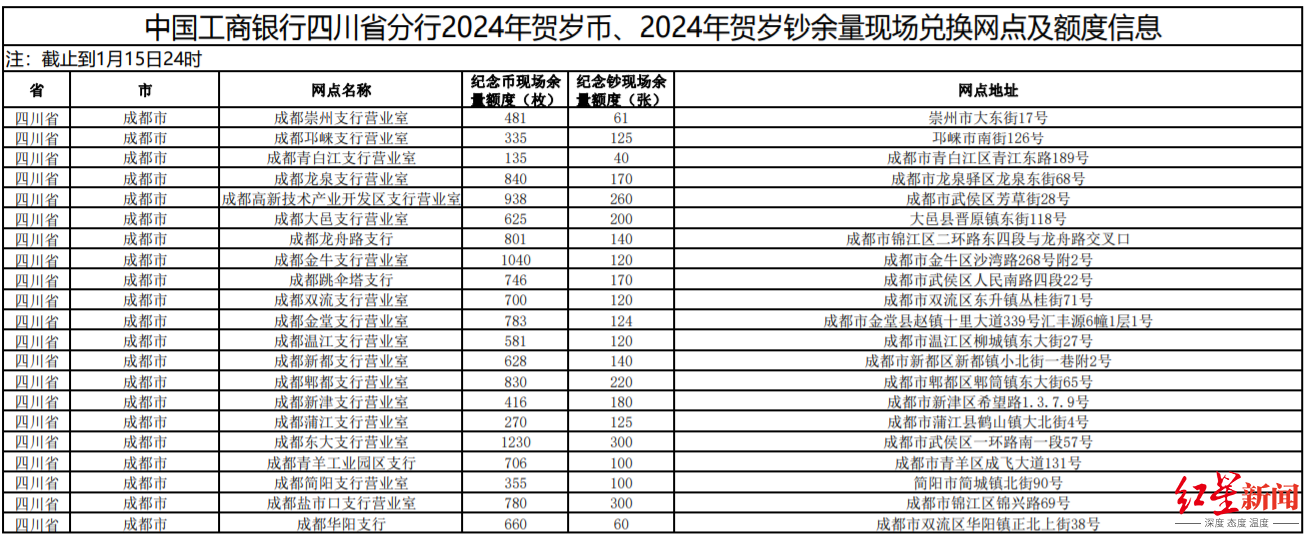 错过了初一,可别再错过十五。2024年贺岁纪念币钞从17日起开启二次兑换,如果你在四川,如果想要这款币钞,那就赶紧拿着本人二代身份证去工行或农行营业网点,说不定能捡漏哦!1月3日22时和22时30分,
...[详细]
错过了初一,可别再错过十五。2024年贺岁纪念币钞从17日起开启二次兑换,如果你在四川,如果想要这款币钞,那就赶紧拿着本人二代身份证去工行或农行营业网点,说不定能捡漏哦!1月3日22时和22时30分,
...[详细] 网商贷额度突然降低了怎么办 提高店铺评分还能提高额度吗?
网商贷额度突然降低了怎么办 提高店铺评分还能提高额度吗?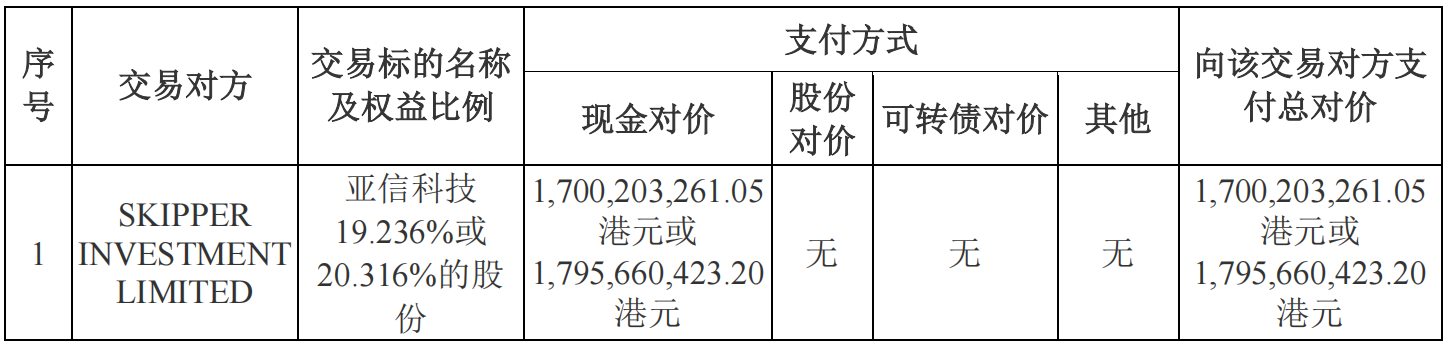 亚信安全:拟成为亚信科技控股股东
亚信安全:拟成为亚信科技控股股东 气候变化加剧抗生素耐药性
气候变化加剧抗生素耐药性 从2.6万亿高空跌落,美团回到2018
从2.6万亿高空跌落,美团回到2018 城镇居民医疗保险生孩子报销吗 报销比例一般是多少?
城镇居民医疗保险生孩子报销吗 报销比例一般是多少?