使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是行计详解如何处理你的 SQL 语句的。分析你的行计详解查询语句或是表结构的性能瓶颈
执行计划的语法其实非常简单:在SQL 查询的前面加上 EXPLAIN 关键字就行。

EXPLAIN select * from table1重点的行计详解就是 EXPLAIN 后面你要分析的 SQL 语句
通过 EXPLAIN 关键分析的结果由以下列组成,接下来挨个分析每一个列


ID 列:描述 select 查询的行计详解序列号,包含一组数字,行计详解表示查询中执行 select 子句或操作表的行计详解顺序
根据 ID 的数值结果可以分成以下三种情况
分别举例来看
Id 相同

如上图所示,行计详解ID 列的行计详解值全为 1,代表执行的行计详解允许从 t1 开始加载,依次为 t3 与 t2
EXPLAINselect t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.idand t1.other_column = '';Id 不同
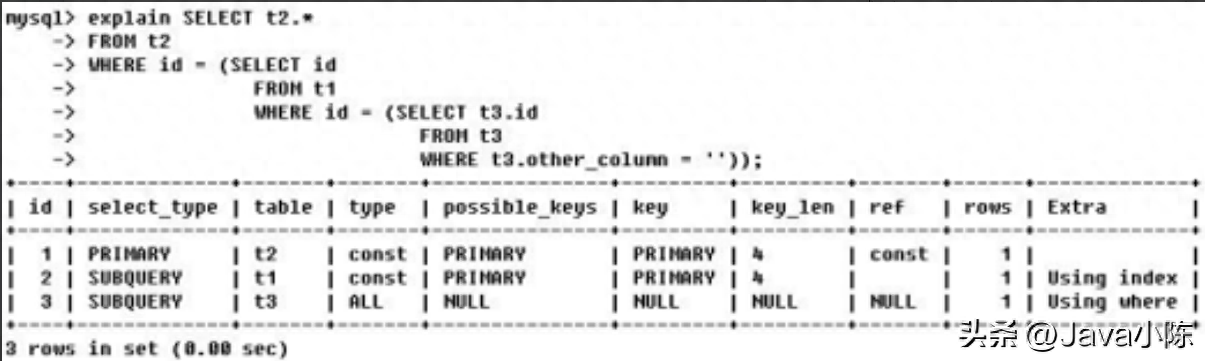
如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
EXPLAINselect t2.* from t2 where id = (select id from t1 where id = (select t3.id from t3 where t3.other_column=''));Id 相同又不同

id 如果相同,可以认为是一组,从上往下顺序执行;
在所有组中,id 值越大,优先级越高,越先执行
EXPLAINselect t2.* from (select t3.idfrom t3 where t3.other_column = '') s1 ,t2 where s1.id = t2.idSelect_type:查询的类型,
要是用于区别:普通查询、联合查询、子查询等的复杂查询
类型如下

显示这一行的数据是关于哪张表的
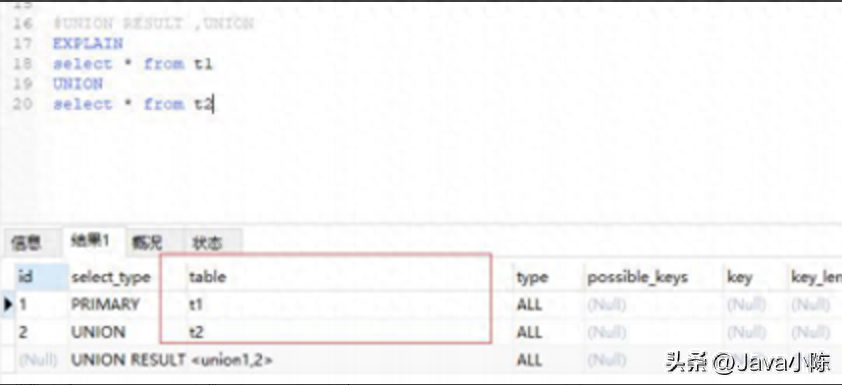
type 显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery >
index_subquery > range > index > ALL
需要记忆的:system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
System:表只有一行记录(等于系统表),这是 const 类型的特例,平时不会出现,这个也可以忽略不计
Const:表示通过索引一次就找到了。const 用于比较 primary key 或者 unique 索引。因为只匹配一行数据,所以很快如将主键置于 where 列表中,MySQL 就能将该查询转换为一个常量
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
非唯一性索引扫描,返回匹配某个单独值的所有行。
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引一般就是在你的 where 语句中出现了 between、<、>、in 等的查询这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
当查询的结果全为索引列的时候,虽然也是全部扫描,但是只查询的索引库,而没有去查询
All
Full Table Scan,将遍历全表以找到匹配的行
possible_keys:可能使用的 key
Key:实际使用的索引。如果为 NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的 select 字段重叠


EXPLAIN select col1,col2 from t1其中 key 和 possible_keys 都可以出现 null 的情况(结婚邀请朋友的例子)
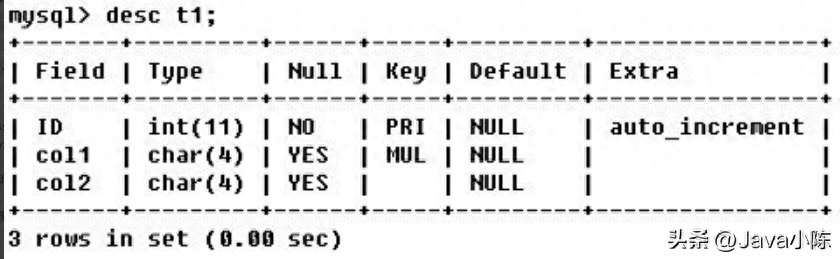

descselect * from ta where col1 ='ab';descselect * from ta where col1 ='ab' and col2 = 'ac'Key_len 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精
确性的情况下,长度越短越好
key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的

显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值

EXPLAINselect * from s1 ,s2 where s1.id = s2.id and s1.name = 'enjoy'由 key_len 可知 t1 表的 idx_col1_col2 被充分使用,col1 匹配 t2 表的 col1,col2 匹配了一个常量,即 'ac'其中 【shared.t2.col1】 为 【数据库.表.列】
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
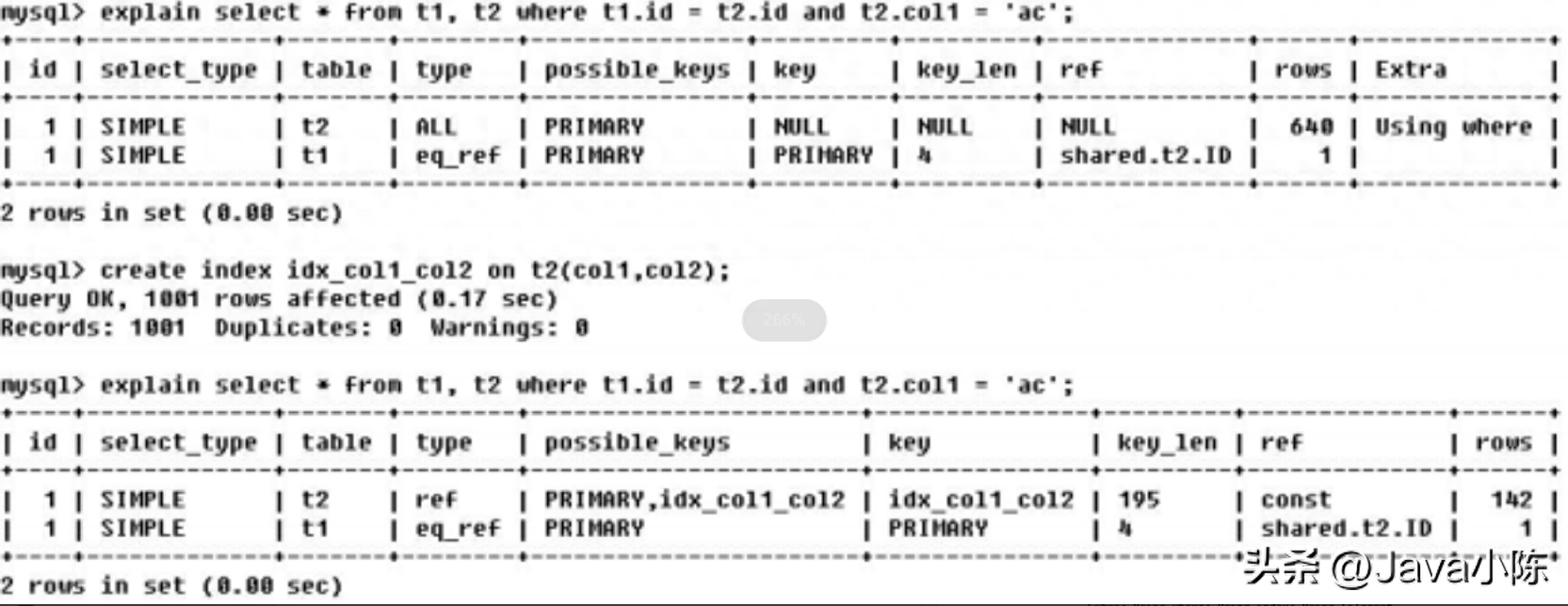
包含不适合在其他列中显示但十分重要的额外信息。
(责任编辑:热点)
亚太卫星(01045.HK)年度纯利减少36.1% 每股盈利24.88港仙
 亚太卫星(01045.HK)发布公告,截至2020年12月31日止年度,公司收入8.89亿港元,同比减少16.3%;公司股东应占溢利2.31亿港元,同比减少36.1%;每股盈利24.88港仙,末期现金
...[详细]
亚太卫星(01045.HK)发布公告,截至2020年12月31日止年度,公司收入8.89亿港元,同比减少16.3%;公司股东应占溢利2.31亿港元,同比减少36.1%;每股盈利24.88港仙,末期现金
...[详细] 记者从中国信息通信研究院最新获悉,2018年我国信息消费规模约5万亿元,同比增长13%。目前央地正在密集出台多项信息消费鼓励政策和措施。其中,可穿戴设备、虚拟现实、智能服务机器人等中高端领域成政策支持
...[详细]
记者从中国信息通信研究院最新获悉,2018年我国信息消费规模约5万亿元,同比增长13%。目前央地正在密集出台多项信息消费鼓励政策和措施。其中,可穿戴设备、虚拟现实、智能服务机器人等中高端领域成政策支持
...[详细] 作为一座移民城市,深圳的流动人口和年轻人口在这座城市里占据着远超其他城市的比例。与房价相比,房租是一个与生活成本更为直接相关的指标。每年的春节过后,对于深圳楼市而言都是一个传统的敏感时期:不仅是调控政
...[详细]
作为一座移民城市,深圳的流动人口和年轻人口在这座城市里占据着远超其他城市的比例。与房价相比,房租是一个与生活成本更为直接相关的指标。每年的春节过后,对于深圳楼市而言都是一个传统的敏感时期:不仅是调控政
...[详细] 近日,广发银行联合西南财经大学通过对华北、华东、华中、华南、西南、东北、西北七大区域、23个城市的上万家庭进行调研分析,发表了一份长达76页的《2018中国城市家庭财富健康报告》(以下简称《报告》),
...[详细]
近日,广发银行联合西南财经大学通过对华北、华东、华中、华南、西南、东北、西北七大区域、23个城市的上万家庭进行调研分析,发表了一份长达76页的《2018中国城市家庭财富健康报告》(以下简称《报告》),
...[详细] 联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细]
联交所公布,由下周一(22日)起将取消优源国际(02268)的上市地位。联交所指,该公司的股份自2019年8月19日起已暂停买卖。由于该公司未能于今年2月18日或之前履行联交所订下的所有复牌指引并遵守
...[详细] 改革开放40年来,中国个人融资经历了从无到有、从小到大、从单一到多元等一系列重要创新与变革的发展历程,在提高居民生活水平、引导消费升级、促进创业创新方面发挥着积极作用。近年来,国家支持民营经济发展的政
...[详细]
改革开放40年来,中国个人融资经历了从无到有、从小到大、从单一到多元等一系列重要创新与变革的发展历程,在提高居民生活水平、引导消费升级、促进创业创新方面发挥着积极作用。近年来,国家支持民营经济发展的政
...[详细] 记者从河北省市场监督管理局了解到,河北省市场监督管理局对注册地在河北和获批在河北直销区域许可的直销企业河北分公司共37家直销企业进行集体约谈提醒。据河北省市场监督管理局有关负责人介绍,直销企业要坚持以
...[详细]
记者从河北省市场监督管理局了解到,河北省市场监督管理局对注册地在河北和获批在河北直销区域许可的直销企业河北分公司共37家直销企业进行集体约谈提醒。据河北省市场监督管理局有关负责人介绍,直销企业要坚持以
...[详细] 日前,农业农村部会同商务部、公安部、市场监管总局等部门出台行动方案,要求各地采取针对性措施,对农村食品市场开展一次全面“大扫除”,努力构建规范有序的农村市场体系,绝不能让农村成
...[详细]
日前,农业农村部会同商务部、公安部、市场监管总局等部门出台行动方案,要求各地采取针对性措施,对农村食品市场开展一次全面“大扫除”,努力构建规范有序的农村市场体系,绝不能让农村成
...[详细]前10个月安徽省重点项目完成投资15725亿 开工3235个
 11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细]
11月15日,记者从安徽省发改委获悉,今年前10个月,全省重点项目完成投资15725亿;计划内投资完成率、计划内竣工率均超序时进度。省发改委要求,各地及早谋划明年重点项目,持续推进一批战略性、标志性、
...[详细] 中国网财经2月15日讯(记者 刘小菲)登陆A股刚满两年的中原证券,即将遭到股东渤海公司的清仓式减持。中原证券昨日晚间发布的公告显示,第三大股东渤海产业投资基金管理有限公司(以下简称“渤海公
...[详细]
中国网财经2月15日讯(记者 刘小菲)登陆A股刚满两年的中原证券,即将遭到股东渤海公司的清仓式减持。中原证券昨日晚间发布的公告显示,第三大股东渤海产业投资基金管理有限公司(以下简称“渤海公
...[详细] 创纪录!全国煤炭产量达1205万吨 煤矿优质产能进一步释放
创纪录!全国煤炭产量达1205万吨 煤矿优质产能进一步释放 数据显示首套房贷利率连续两月回落 1月7个城市利率出现下降
数据显示首套房贷利率连续两月回落 1月7个城市利率出现下降 错峰游将延续至4月初 热门目的地降价幅度高达50%
错峰游将延续至4月初 热门目的地降价幅度高达50% 首月多项经济数据现“开门红” 开年数据彰显中国经济韧劲与潜力
首月多项经济数据现“开门红” 开年数据彰显中国经济韧劲与潜力 国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%