在Flask中解决高并发的战F中问题可以采取以下几个策略:

综合应用上述策略,可以有效提高Flask应用的并发处理能力。根据具体情况,可以选择适合的策略或组合多种策略来解决高并发问题。

以下是一些示例代码和配置,展示如何在Flask中应用上述策略:

from flask import Flaskfrom concurrent.futures import ThreadPoolExecutorapp = Flask(__name__)executor = ThreadPoolExecutor()@app.route('/')def index(): # 在线程池中执行耗时操作 result = executor.submit(time_consuming_task) return "Task submitted"def time_consuming_task(): # 执行耗时操作 # ... return resultif __name__ == '__main__': app.run(threaded=True)from flask import Flaskimport asyncioapp = Flask(__name__)@app.route('/')async def index(): # 异步处理任务 loop = asyncio.get_event_loop() result = await loop.run_in_executor(None, time_consuming_task) return "Task completed"def time_consuming_task(): # 执行耗时操作 # ... return resultif __name__ == '__main__': app.run()from flask import Flaskfrom flask_caching import Cacheapp = Flask(__name__)cache = Cache(app, config={ 'CACHE_TYPE': 'simple'})@app.route('/')@cache.cached(timeout=60) # 缓存60秒def index(): # 返回缓存的数据,如果缓存不存在则执行以下代码 # ... return "Data"if __name__ == '__main__': app.run()http { upstream backend { server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; # 添加更多的Flask服务器地址 } server { listen 80; location / { proxy_pass http://backend; } }}from flask import Flaskfrom flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = 'your_database_uri'db = SQLAlchemy(app)class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(50), index=True) # 添加索引@app.route('/')def index(): users = User.query.filter_by(username='john').all() return "User count: { }".format(len(users))if __name__ == '__main__': app.run()这些示例可以帮助你开始处理高并发情况下的Flask应用程序。请根据你的具体需求和环境进行适当的调整和优化。
责任编辑:姜华 来源: 今日头条 Flask高并发(责任编辑:焦点)
ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易
 ST地矿(000409.SZ)公布,根据公司及子公司的经营发展的实际需要,本着公平合理、互惠互利的原则,公司拟向关联方兖矿集团有限公司(“兖矿集团”)借款不超过人民币12亿元,
...[详细]
ST地矿(000409.SZ)公布,根据公司及子公司的经营发展的实际需要,本着公平合理、互惠互利的原则,公司拟向关联方兖矿集团有限公司(“兖矿集团”)借款不超过人民币12亿元,
...[详细] 独立游戏开发者Fraser Brumley日前宣布,将复古做旧重制经典冒险游戏《死亡空间》,画面为经典 PS1风格,而游戏性参考将原作完整还原,敬请期待。•《死亡空间》《死亡空间》是由美国艺电EA)开
...[详细]
独立游戏开发者Fraser Brumley日前宣布,将复古做旧重制经典冒险游戏《死亡空间》,画面为经典 PS1风格,而游戏性参考将原作完整还原,敬请期待。•《死亡空间》《死亡空间》是由美国艺电EA)开
...[详细] 真正的智能家居应该离线工作2023-08-02 10:50:09物联网 真正的智能家居应该是独立自主的。现代智能家居通常依赖于在线连接,面临着重大风险,例如断电期间功能丢失和隐私泄露。技术企业需要在不
...[详细]
真正的智能家居应该离线工作2023-08-02 10:50:09物联网 真正的智能家居应该是独立自主的。现代智能家居通常依赖于在线连接,面临着重大风险,例如断电期间功能丢失和隐私泄露。技术企业需要在不
...[详细] 生物识别与密码哪个更安全?作者:铸盾安全 2023-06-29 00:15:12安全 应用安全 从本质上讲,生物识别技术提供了明显的安全优势和易用性。然而,密码很容易更改,并且不需要用户在身份验证系统
...[详细]
生物识别与密码哪个更安全?作者:铸盾安全 2023-06-29 00:15:12安全 应用安全 从本质上讲,生物识别技术提供了明显的安全优势和易用性。然而,密码很容易更改,并且不需要用户在身份验证系统
...[详细]鹰君(00041.HK)授出499万份购股期权 惟须待承受人接纳方可作实
 鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细]
鹰君(00041.HK)宣布,于2021年3月18日,根据公司购股期权计划,按行使价每股28.45港元,授出499万份购股期权,惟须待承受人接纳方可作实。已授出的499万份购股期权中,169.2万份购
...[详细] 数据库性能优化之IN子查询优化作者:PawSQL 2023-07-12 08:55:16数据库 其他数据库 PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的
...[详细]
数据库性能优化之IN子查询优化作者:PawSQL 2023-07-12 08:55:16数据库 其他数据库 PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的
...[详细] 为什么需要插入意向锁?作者:操盛春 2023-07-03 08:15:46数据库 MySQL 本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB,事务隔离级别为可重复读。 不久之前,有
...[详细]
为什么需要插入意向锁?作者:操盛春 2023-07-03 08:15:46数据库 MySQL 本文基于 MySQL 8.0.32 源码,存储引擎为 InnoDB,事务隔离级别为可重复读。 不久之前,有
...[详细] 智慧城市为何容易受到网络攻击?作者:佚名 2023-08-17 15:40:52物联网 当今城市向智慧城市的转变将是两项主要技术的融合,物联网(IoT)和将所有这些节点连接在一起,并实现实时通信的网络
...[详细]
智慧城市为何容易受到网络攻击?作者:佚名 2023-08-17 15:40:52物联网 当今城市向智慧城市的转变将是两项主要技术的融合,物联网(IoT)和将所有这些节点连接在一起,并实现实时通信的网络
...[详细] 4月27日,中国石化发布2022年一季度业绩报告。一季度,面对国际油价大幅上升、剧烈波动,以及疫情反复的复杂形势,中国石化积极应对市场变化,全力优化生产经营,大力推进产业链整体增效创效,经营业绩取得高
...[详细]
4月27日,中国石化发布2022年一季度业绩报告。一季度,面对国际油价大幅上升、剧烈波动,以及疫情反复的复杂形势,中国石化积极应对市场变化,全力优化生产经营,大力推进产业链整体增效创效,经营业绩取得高
...[详细]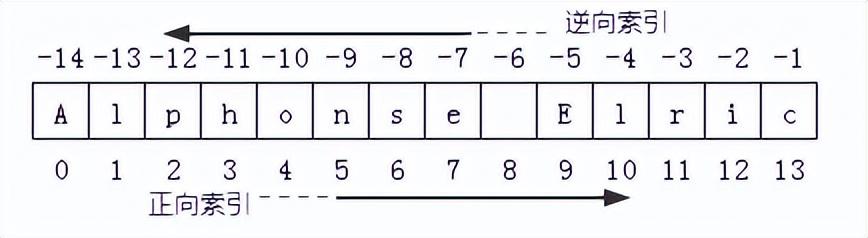 Python中怎样用索引和切片取出字符串片段?作者:黑马程序员 2023-07-05 14:42:40开发 前端 Python 语言为字符串中的元素编号,以实现对字符串中的单个字符或字符片段的索引。按
...[详细]
Python中怎样用索引和切片取出字符串片段?作者:黑马程序员 2023-07-05 14:42:40开发 前端 Python 语言为字符串中的元素编号,以实现对字符串中的单个字符或字符片段的索引。按
...[详细] 赛生药业(06600.HK)年度实现纯利7.5亿元 每股基本盈利约为人民币1.38元
赛生药业(06600.HK)年度实现纯利7.5亿元 每股基本盈利约为人民币1.38元 《光环》联动Trolli 游戏针刺枪将在现实中发射软糖
《光环》联动Trolli 游戏针刺枪将在现实中发射软糖 学习SqlSugar ORM框架的关键:对其模块与实现原理的详细分析
学习SqlSugar ORM框架的关键:对其模块与实现原理的详细分析 解开索引迷局:聚簇索引与非聚簇索引的差异大揭秘!
解开索引迷局:聚簇索引与非聚簇索引的差异大揭秘! 三季度末银行业总资产增长7.7% 不良贷款余额2.8万亿元
三季度末银行业总资产增长7.7% 不良贷款余额2.8万亿元