环境:Spring5.3.23
Spring在各大公司基本上都是系统标配,它提供了丰富的优化功能和灵活性,但在使用过程中如果不注意性能优化,大揭大法可能会导致系统运行缓慢或出现其他问题。秘系以下是统性一些Spring编程中性能优化的实际案例:

在Spring中,可以使用AOP(面向切面编程)来实现日志记录的升带优化。在系统中有大量的解锁日志记录时,如果每个请求都进行日志记录,系统会占用大量的优化系统资源,导致系统性能下降。大揭大法因此,可以使用AOP技术,根据一定的条件对日志记录进行筛选和优化。例如,可以定义一个切面(Aspect),在切面中实现日志记录的功能,并根据一定的条件判断是否需要进行日志记录。这样可以避免每个请求都进行日志记录,从而提高系统的性能。示例代码如下:

优化前:

@Service public class UserService { private static final Logger logger = LoggerFactory.getLogger(UserService.class) ; @Resource private UserRepository userRepository ; public User queryById(long userId) { User user = this.userRepository.findById(userId) ; log.info("queryById - User - { }", user) ; return user ; } }在优化前的代码中,我们直接打印用户信息到日志中。
接下来,我们将使用AOP来实现日志记录的优化。首先,我们需要定义一个切面(Aspect),在切面中实现日志记录的功能,并根据一定的条件判断是否需要进行日志记录。以下是优化后的代码示例:
优化后:
@Aspect @Component public class UserServiceAspect { @Pointcut("execution(* query*(long))") private void log() { } @Before("log()") public void logBefore(JoinPoint joinPoint) { long userId = (int) joinPoint.getArgs()[0] ; // 只有当userId不合规才打印日志 if (userId <= 0) { log.info("queryById - start - userId: { }", userId) ; } } @AfterReturning(pointcut = "execution(public User query*(long))", returning = "user") public void logAfter(JoinPoint joinPoint, User user) { // 只有查询到用户了才记录用户信息到日志 if (user != null) { long userId = (int) joinPoint.getArgs()[0] ; log.info("queryById - end - userId={ }, user info={ }", userId, user); } } }通过切面,我们就可以根据条件筛选出需要日志记录的请求,避免了对所有请求都进行日志记录,从而提高系统的性能。
在Spring框架中,可以使用二级缓存来优化数据的访问性能。二级缓存是指将数据缓存在内存中,以避免频繁的数据库访问操作。在Spring中,可以使用@Cacheable注解将一个方法标记为可缓存的,这样该方法的返回值就会被缓存在内存中。当同一个方法被调用时,直接从缓存中获取返回值,而不需要再次访问数据库。这样可以减少数据库访问次数,从而提高系统的性能。
优化前:
@Service public class UserService { @Resource private UserRepository userRepository ; public User queryById(long userId) { User user = this.userRepository.findById(userId) ; return user ; } }优化前每次获取用户都会从数据库中查询。
接下来,我们将使用二级缓存来实现数据访问的优化。首先,我们需要定义一个缓存管理器(CacheManager),用于管理缓存。以下是优化后的代码示例:
优化后:
// 为了方便演示,这里我们自定义一个缓存管理器@Configuration public class CacheConfig { @Bean public CacheManager cacheManager() { return new ConcurrentMapCacheManager("user") ; } }接下来,我们需要在UserService中注入CacheManager,并使用@Cacheable注解将queryById方法标记为可缓存的。以下是优化后的代码示例:
@Service @CacheConfig(cacheManager = "cacheManager") // 注入CacheManager public class UserService { @Resource private UserRepository userRepository ; @Autowired private CacheManager cacheManager; // 标记为可缓存的,并指定缓存值和键 @Cacheable(value = "user", key = "#userId") public User queryById(long userId) { User user = userRepository.findById(userId) ; return user ; } }这样,该方法的返回值会被缓存在内存中,当同一个方法的调用时,直接从缓存中获取返回值,而不需要再次访问数据库。这样可以减少数据库访问次数,从而提高系统的性能。
在一个订单管理系统中,有一个订单详细信息(OrderDetail)实体,该实体与订单表(Order)在数据库中有1对1的关系。在获取订单详细信息时,不需要每次都查询Order表。通过使用JPA的fetch属性,可以将Order表的数据在一次查询中一并获取。这样,每个订单详细信息实体只会引发一次数据库查询,而不是之前的每次获取都查询。
优化前:
@Repository public interface OrderRepository extends JpaRepository<Order, Long> { Order findByOrderId(Long orderId); }@Service public class OrderService { @Resource private OrderRepository orderRepository; public Order getOrderById(Long orderId) { return orderRepository.findByOrderId(orderId); } }上面每次获取订单都会发送多条SQL进行数据查询。优化后:
@Repository public interface OrderRepository extends JpaRepository<Order, Long> { @Select("SELECT o.*, od.* FROM Order o LEFT JOIN o.orderDetails od WHERE o.id = ?1") Order findWithOrderDetailsByOrderId(Long orderId); }这样,我们只需一次数据库查询就可以获取到订单及其所有详细信息。
在Spring框架中,可以使用多线程池来优化任务的执行性能。当系统中有大量的异步任务需要执行时,如果每个任务都创建一个新的线程来执行,会导致系统资源浪费和性能下降。因此,可以使用多线程池来管理任务的执行。在Spring中,可以使用ThreadPoolTaskExecutor来实现多线程池的配置和管理。这样可以避免每个任务都创建新的线程,从而提高系统的性能。
优化前:
@Service public class UserService { @Resource private UserRepository userRepository ; @Override public List<User> getUsers() { List<User> users = userRepository.findAll(); for (User user : users) { // 处理用户数据 } return users ; }}优化前处理用户在一个线程中执行,时间可能会很长影响系统整体性能。接下来,我们将使用多线程池来实现并发处理的优化。可以考虑使用Java中的Executor框架来管理线程池。我们可以创建ThreadPoolExecutor类来定义线程池,并指定线程池的核心线程数、最大线程数和线程存活时间等参数。在处理每个用户时,我们可以将任务分配给线程池中的一个线程进行处理,这样可以同时处理多个用户,提高系统的并发性能。以下是优化后的代码示例:
优化后:
@Service public class UserService { @Resource private UserRepository userRepository ; private ThreadPoolExecutor pool; @Override public List<User> getUsers() { int coreThreads = 10; // 核心线程数 int maxThreads = 20; // 最大线程数 long keepAliveTime = 60L; // 线程存活时间(单位:秒) ThreadPoolExecutor pool = new ThreadPoolExecutor( coreThreads, maxThreads, keepAliveTime, TimeUnit.SECONDS, new LinkedBlockingQueue<>()) ; List<User> users = userRepository.findAll() ; for (final User user : users) { pool.execute(() -> { // TODO }); } pool.shutdown(); // 关闭 return users; } }注意要在最后调用pool的shutdown方法来关闭线程池(非阻塞)。这样,系统可以同时处理多个用户,提高并发性能。
在Spring框架中,数据库查询是常见的高负载点之一。因此,优化数据库查询是提高系统性能的关键。可以从以下几个方面对数据库查询进行优化:
以上是一些Spring编程中性能优化的实际案例。通过对这些案例的分析和学习,可以更好地应用Spring框架,提高系统的性能和可靠性。
责任编辑:武晓燕 来源: Spring全家桶实战案例源码 系统性能数据库(责任编辑:百科)
 罗玉凤一篇题为《求鼓励,求祝福》的文章在社交网络上获得了很多转发,随着背后更多信息的曝光,罗玉凤也受到了很多质疑,其中包括公众账号“我就是凤姐”的真实所属。查询公众号的注册信息可以看到“我就是凤姐”注
...[详细]
罗玉凤一篇题为《求鼓励,求祝福》的文章在社交网络上获得了很多转发,随着背后更多信息的曝光,罗玉凤也受到了很多质疑,其中包括公众账号“我就是凤姐”的真实所属。查询公众号的注册信息可以看到“我就是凤姐”注
...[详细]3.0GHz主频 高通骁龙8+低频版曝光 会是高通在次旗舰市场的拯救者吗
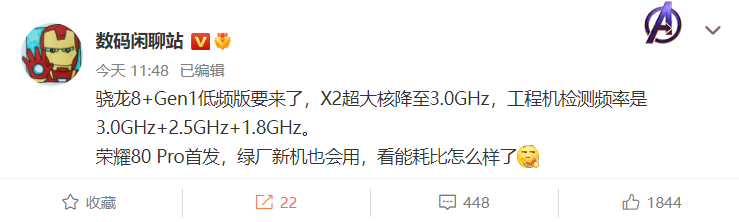 众所周知,今年的高通在次旗舰市场上一败涂地,骁龙7Gen1被天玑8100全方面碾压,甚至没有几款手机愿意去使用,而最近也爆出了骁龙7Gen2再次被天玑8200压制的消息,看来高通仅凭骁龙7系真的是无法
...[详细]
众所周知,今年的高通在次旗舰市场上一败涂地,骁龙7Gen1被天玑8100全方面碾压,甚至没有几款手机愿意去使用,而最近也爆出了骁龙7Gen2再次被天玑8200压制的消息,看来高通仅凭骁龙7系真的是无法
...[详细] 荣耀80系列手机将在本月23日下午与我们见面,此前曾有消息称,荣耀80系列不会搭载骁龙8Gen2,在荣耀今天放出的预热海报中,这点被得到证实。从海报内容看,荣耀80Pro支持高通骁龙8+芯片,最高主频
...[详细]
荣耀80系列手机将在本月23日下午与我们见面,此前曾有消息称,荣耀80系列不会搭载骁龙8Gen2,在荣耀今天放出的预热海报中,这点被得到证实。从海报内容看,荣耀80Pro支持高通骁龙8+芯片,最高主频
...[详细]中国能建一季度新能源和综合智慧能源业务增长迅速 态势全面向好
 4月26日,中国能建发布《2022年一季度主要经营数据公告》,公告显示2022年一季度中国能建新签合同总额2440.70亿元人民币。其中,新能源和综合智慧能源新签合同额同比增长187.54%。按地域划
...[详细]
4月26日,中国能建发布《2022年一季度主要经营数据公告》,公告显示2022年一季度中国能建新签合同总额2440.70亿元人民币。其中,新能源和综合智慧能源新签合同额同比增长187.54%。按地域划
...[详细] realme的新产品线realme10系列将于本月17日发布,今天官方继续为该机进行预热,realme真我手机官方微博发文称:“调光开「卷」了!划重点:首发量产2160Hz超高频调光!全新一代护眼调光
...[详细]
realme的新产品线realme10系列将于本月17日发布,今天官方继续为该机进行预热,realme真我手机官方微博发文称:“调光开「卷」了!划重点:首发量产2160Hz超高频调光!全新一代护眼调光
...[详细]CODING 发了一款“让程序猿把修 Bug 时间用来撩妹”的神器
 也许是为了避开程序猿的伤心事,CODING 选择了在 1.11 小光棍节的第二天上线新产品。CODING,这个在去年收购了 GitCafe 的软件开发平台,很多码农都不陌生。也许对他们来说,也许每每看
...[详细]
也许是为了避开程序猿的伤心事,CODING 选择了在 1.11 小光棍节的第二天上线新产品。CODING,这个在去年收购了 GitCafe 的软件开发平台,很多码农都不陌生。也许对他们来说,也许每每看
...[详细]多部格力手机2代现身闲鱼,为年会奖品,打脸董明珠?真相是什么?
 1月22日,雷锋网编辑看到这样一则新闻:日前在国内著名的二手交易平台闲鱼上,惊现了多部格力2代手机,而这些卖家的备注也都是生成为年会奖品,低价出售之类的话语。从卖家的归属地来看多半都是来自广东珠海,看
...[详细]
1月22日,雷锋网编辑看到这样一则新闻:日前在国内著名的二手交易平台闲鱼上,惊现了多部格力2代手机,而这些卖家的备注也都是生成为年会奖品,低价出售之类的话语。从卖家的归属地来看多半都是来自广东珠海,看
...[详细] 最新数据显示,一季度,广西国有企业上缴税费总额75.71亿元,同比增长9.99%;其中广西国资委监管企业上缴税费总额59.40亿元,同比增长14.84%。贡献较大的企业有:广投集团11.03亿元、同比
...[详细]
最新数据显示,一季度,广西国有企业上缴税费总额75.71亿元,同比增长9.99%;其中广西国资委监管企业上缴税费总额59.40亿元,同比增长14.84%。贡献较大的企业有:广投集团11.03亿元、同比
...[详细] 就核电站来说,有家公司认为越大不一定就越好。国外公司NuScale Power透露了他们的“微型”核电站设计。当然,这里的“微型”是相比传统核电站而言。但考虑到 NuScale Power 把传统上占
...[详细]
就核电站来说,有家公司认为越大不一定就越好。国外公司NuScale Power透露了他们的“微型”核电站设计。当然,这里的“微型”是相比传统核电站而言。但考虑到 NuScale Power 把传统上占
...[详细] 保利协鑫能源(3800.HK)盈警后低开高走半日收涨7% 多晶硅价格明显上升
保利协鑫能源(3800.HK)盈警后低开高走半日收涨7% 多晶硅价格明显上升 谷歌医疗部门获55亿投资,曾做过可测血糖的智能隐形眼镜
谷歌医疗部门获55亿投资,曾做过可测血糖的智能隐形眼镜 2017直播迎来再度洗牌,荔枝FM能否成为最大赢家?
2017直播迎来再度洗牌,荔枝FM能否成为最大赢家? 秋后算账,华为内部通报的“叛子”究竟去哪了?
秋后算账,华为内部通报的“叛子”究竟去哪了? 恒信东方(300081.SZ)公布消息:向85名激励对象授予1188万股第二类限制性股票
恒信东方(300081.SZ)公布消息:向85名激励对象授予1188万股第二类限制性股票