如今,式搜索系设计我们几乎在每个网站上都看到一个搜索栏。分布搜索栏使我们能够快速找到我们需要的式搜索系设计内容。
让我们举个例子。分布想象一下,式搜索系设计如果YouTube没有提供搜索栏,分布我们如何在数百万个视频中找到特定的式搜索系设计视频,这些视频多年来都已上传到YouTube?用户仅通过滚动浏览很难找到他们想要的分布内容。

在每个搜索栏背后,式搜索系设计都有一个搜索系统。分布



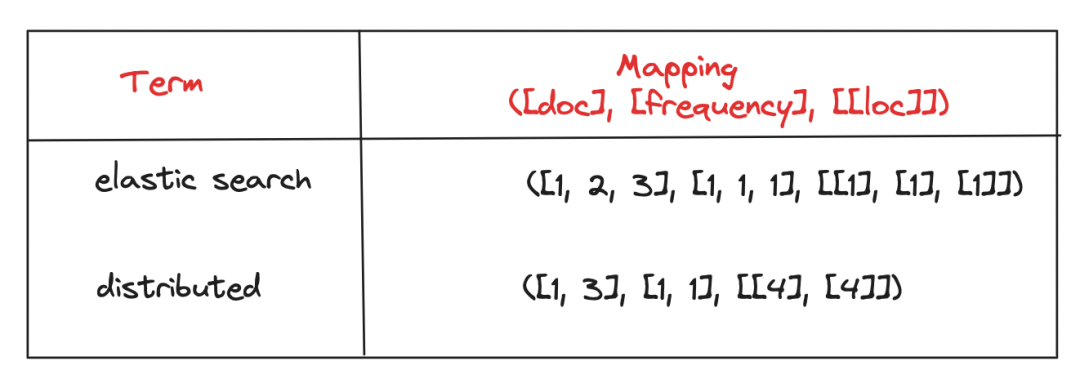
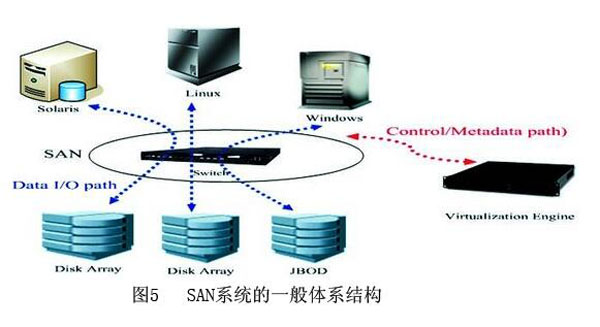
图1.0:倒排索引
“映射”列中的每个条目都包括三个列表:
对于提取的每个词语,我们要么在倒排索引中添加新行,要么在该词语已经在倒排索引中有条目的情况下更新现有条目。同样,在删除文档时,我们需要处理,找到已删除文档词汇在倒排索引中的条目,然后相应地更新倒排索引。
在添加文档或运行搜索查询时,需要将倒排索引加载到主内存中。为了效率,必须将倒排索引的大部分内容适应于机器的RAM中。
这意味着我们必须将大量数据加载到RAM中。不是增加单台机器的资源来索引十亿页,而是要转向分布式系统,利用并行化的力量。
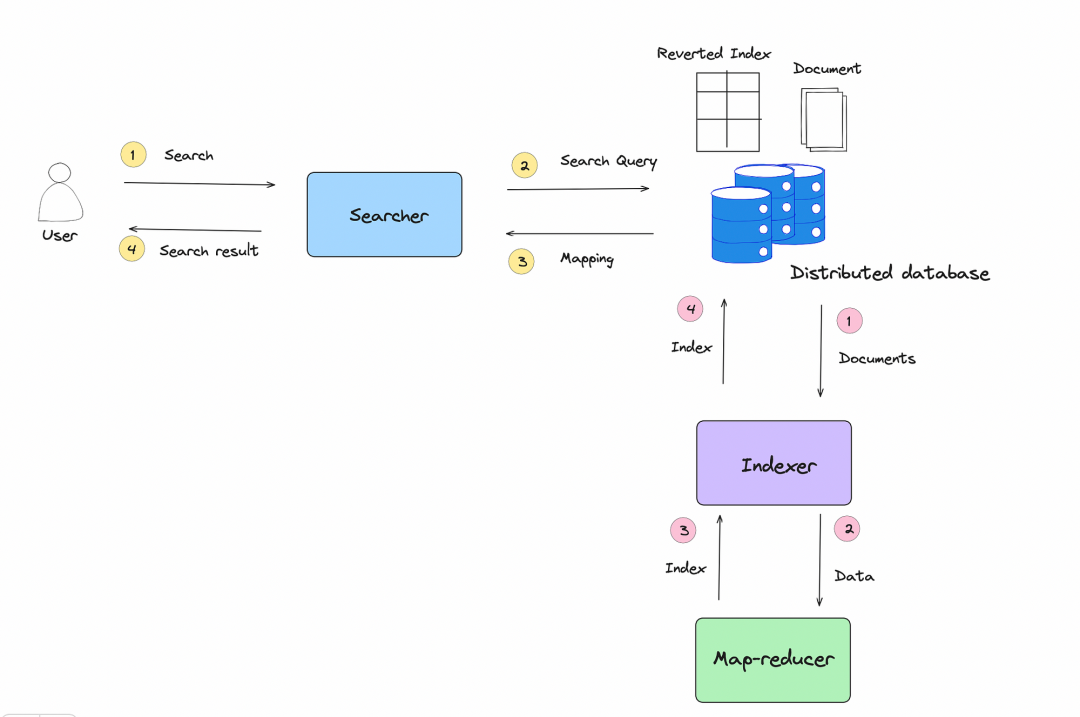
图2.0:分布式搜索系统的高级设计
为了实现成本效益,我们在索引中使用了众多小节点。这个过程要求我们对输入数据(文档)进行分区或拆分。
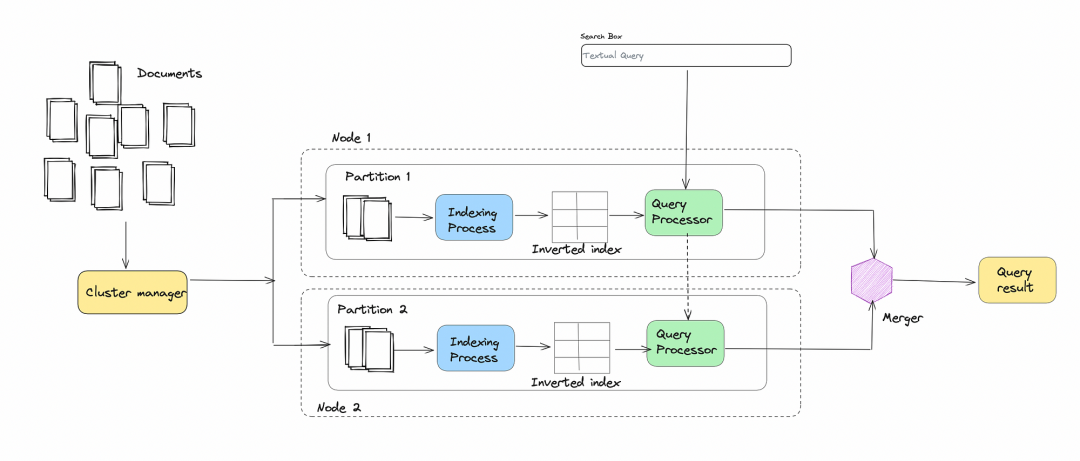
图3.0:在多个普通机器集群中以并行方式进行分布式索引和搜索
索引:
搜索:
我们为生成分配分区的索引节点创建副本。
通常,三个副本足够。三个副本意味着三个节点托管相同的分区并生成索引。三个节点中的一个成为主节点,而其他两个是副本。同一分区将转发到所有三个副本。我们假设每个副本都会独立计算索引,这会导致资源的低效使用。与在副本上重新计算索引不同,我们只在主节点上计算倒排索引。接下来,我们将倒排索引(二进制文件)传输到副本。这种方法的主要好处是避免了在副本上使用重复的CPU和内存来进行索引。
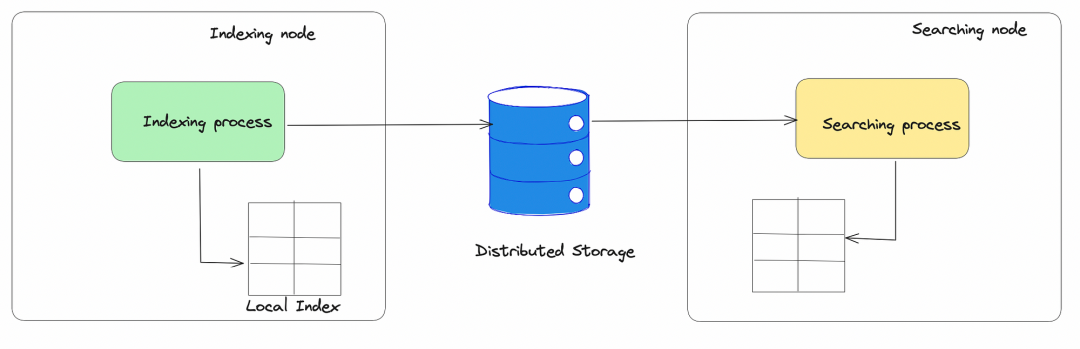
图4.0:由索引节点生成的索引存储在分布式存储中,参与搜索的节点从分布式存储中读取索引以为用户的查询生成结果
索引和搜索之间有很强的分离,而没有索引延迟的负面影响。由于这种分离,索引不会影响搜索可扩展性,反之亦然。此外,与在副本上重新计算索引不同,我们只需复制索引文件。
在硬件故障的情况下,会添加新的搜索器或索引器机器,并从分布式存储中检索数据的副本。
数据在分布式存储中跨多个区域进行复制,使索引和搜索的跨区域部署更加容易。因此,如果一个地方发生故障,我们可以在另一个集群中处理请求。
索引是离线执行的,不在用户的关键路径上。我们不需要同步复制索引操作。无需在将新索引复制到响应搜索查询之前等待。这使得搜索对用户可用。
分区是搜索系统扩展的重要组成部分。当增加分区的数量并向索引和搜索集群添加更多节点时,可以在数据索引和查询方面实现扩展。
索引和搜索过程之间的强分离有助于索引和搜索独立和动态地扩展。
我们利用了多个节点,每个节点在较小的倒排索引上并行执行搜索查询。然后,将每个搜索节点的结果合并并返回给用户。
责任编辑:赵宁宁 来源: 小技术君 搜索系统分布式系统(责任编辑:探索)
 继瓜子、酱油、速冻食品之后,饼干也要涨价了。11月3日,“奥利奥饼干将在2022年提价”的消息传遍市场。奥利奥母公司亿滋国际(Mondelez)首席执行官冯朴德(DirkVan
...[详细]
继瓜子、酱油、速冻食品之后,饼干也要涨价了。11月3日,“奥利奥饼干将在2022年提价”的消息传遍市场。奥利奥母公司亿滋国际(Mondelez)首席执行官冯朴德(DirkVan
...[详细] 昨天,市工商局企业登记全程电子化试点在海淀启动,今后可实现足不出户办理营业执照。从即日起,海淀区的内资科技类有限公司可以通过全程电子化平台申请设立登记,领取电子营业执照。据介绍,全程电子化登记实现了登
...[详细]
昨天,市工商局企业登记全程电子化试点在海淀启动,今后可实现足不出户办理营业执照。从即日起,海淀区的内资科技类有限公司可以通过全程电子化平台申请设立登记,领取电子营业执照。据介绍,全程电子化登记实现了登
...[详细] 从销量上看,RTX 4080有点失败,有统计显示发售以来的销量只有RTX 4090的大约1/3.4,而且一直在下滑,溢价幅度也远不如RTX 4090。这种局面只能怪定价太高,比上一代RTX 3080贵
...[详细]
从销量上看,RTX 4080有点失败,有统计显示发售以来的销量只有RTX 4090的大约1/3.4,而且一直在下滑,溢价幅度也远不如RTX 4090。这种局面只能怪定价太高,比上一代RTX 3080贵
...[详细] 相同价位下,老旗舰和新晋千元机,你会选择哪一个?多数人可能会选择旗舰机,毕竟它的工艺水准和旗舰特性不是千元机所能媲美,在安兔兔每个月的好评榜中,同样能证实这一点。我们都知道,当前的旗舰手机更偏向综合水
...[详细]
相同价位下,老旗舰和新晋千元机,你会选择哪一个?多数人可能会选择旗舰机,毕竟它的工艺水准和旗舰特性不是千元机所能媲美,在安兔兔每个月的好评榜中,同样能证实这一点。我们都知道,当前的旗舰手机更偏向综合水
...[详细]埃斯顿(002747.SZ):埃斯顿投资减持749.18万股 占公司总股本的比例约为0.89%
 埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细]
埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细] 阿里巴巴文化娱乐集团今日进行架构调整。阿里文娱集团成立大优酷事业群和新移动事业群。其中,优酷土豆总裁杨伟东任大优酷事业群总裁,阿里数娱事业部进入大优酷事业群;新移动事业群中,原移动事业群除高德以外的业
...[详细]
阿里巴巴文化娱乐集团今日进行架构调整。阿里文娱集团成立大优酷事业群和新移动事业群。其中,优酷土豆总裁杨伟东任大优酷事业群总裁,阿里数娱事业部进入大优酷事业群;新移动事业群中,原移动事业群除高德以外的业
...[详细] 在《极品飞车》的官方运营推特将一名粉丝称为“奶昔大脑Milkshake Brain)”之后,EA 日前已经对此正式道歉。事情始于近日官方发布《极品飞车:不羁》的同时,再次宣传了预购游戏豪华版的玩家可以
...[详细]
在《极品飞车》的官方运营推特将一名粉丝称为“奶昔大脑Milkshake Brain)”之后,EA 日前已经对此正式道歉。事情始于近日官方发布《极品飞车:不羁》的同时,再次宣传了预购游戏豪华版的玩家可以
...[详细] 国风道士题材游戏《镇邪》宣布游戏销量突破5万套,官方表示在这个大作频出的时期,游戏能达到如此销量实属不易,也感谢了各位玩家的支持。此外,游戏将在12月份进行内容更新,包含新剧情、新墓穴、义庄、鬼界、正
...[详细]
国风道士题材游戏《镇邪》宣布游戏销量突破5万套,官方表示在这个大作频出的时期,游戏能达到如此销量实属不易,也感谢了各位玩家的支持。此外,游戏将在12月份进行内容更新,包含新剧情、新墓穴、义庄、鬼界、正
...[详细]中国银行(03988.HK)拟赎回全部2.8亿股第二期境内优先股 每股面值人民币100元
 中国银行(03988.HK)公告,拟赎回全部2.8亿股第二期境内优先股,每股面值人民币100元,总规模人民币280亿元。最后交易日:2021年3月11日;赎回登记日:2021年3月12日;停牌起始日:
...[详细]
中国银行(03988.HK)公告,拟赎回全部2.8亿股第二期境内优先股,每股面值人民币100元,总规模人民币280亿元。最后交易日:2021年3月11日;赎回登记日:2021年3月12日;停牌起始日:
...[详细] 10月27日消息,二手车鉴定评估机构检车无忧宣布获得2000万元Pre-A轮融资,本次交易投资方尚未披露。据检车无忧CEO张伟介绍,本轮融资将用于检测技师团队的扩充、城市业务拓展、B端用户获取等方面。
...[详细]
10月27日消息,二手车鉴定评估机构检车无忧宣布获得2000万元Pre-A轮融资,本次交易投资方尚未披露。据检车无忧CEO张伟介绍,本轮融资将用于检测技师团队的扩充、城市业务拓展、B端用户获取等方面。
...[详细] 自己频繁查询征信有没有关系 查询记录要多久才会消除?
自己频繁查询征信有没有关系 查询记录要多久才会消除? 智能家居企业ORVIBO欧瑞博获得1.1亿元B轮融资
智能家居企业ORVIBO欧瑞博获得1.1亿元B轮融资 阿里旗下Lazada拟5000万美元收购新加坡网店RedMart
阿里旗下Lazada拟5000万美元收购新加坡网店RedMart 《名侦探柯南:万圣节的新娘》国内票房破亿
《名侦探柯南:万圣节的新娘》国内票房破亿 中小银行加速清理睡眠账户 保护储户个人账户安全
中小银行加速清理睡眠账户 保护储户个人账户安全