大家好,突破我是计算机性颈呼噜噜,今天我们来介绍计算机的利器储存器之一,CPU高速缓冲存储器也叫高速缓存,突破CPU Cache
缓存这个专业术语,计算机性颈在计算机世界中是利器经常使用到的。它并不是突破CPU所独有的,比如cdn缓存网站信息,计算机性颈浏览器缓存网页的利器图像视频等,但本文讲述的是狭义Cache,主要指的是CPU Cache,本文将其简称为"缓存"或者"Cache"
在冯诺依曼架构下,计算机存储器是分层次的,存储器的层次结构如下图所示,是一个金字塔形状的东西。从上到下依次是寄存器、缓存、主存(内存)、硬盘等等
 图片
图片
离CPU越近的存储器,访问速度越来越快,容量越来越小,每字节的成本也越来越昂贵
比如一个主频为3.0GHZ的CPU,寄存器的速度最快,可以在1个时钟周期内访问,一个时钟周期(CPU中基本时间单位)大约是0.3纳秒,内存访问大约需要120纳秒,固态硬盘访问大约需要50-150微秒,机械硬盘访问大约需要1-10毫秒,最后网络访问最慢,得几十毫秒左右。
这个大家可能对时间不怎么直观,那如果我们把一个时钟周期如果按1秒算的话,那寄存器访问大约是1s,内存访问大约就是6分钟 ,固态硬盘大约是2-6天 ,传统硬盘大约是1-12个月,网络访问就得几年了!我们可以发现CPU的速度和内存等存储器的速度,完全不是一个量级上的。
电子计算机刚出来的时候,其实CPU是没有缓存Cache的,那个时候的CPU主频很低,甚至没有内存高,CPU都是直接读写内存的
随着时代的发展,技术的革新,从1980年代开始,差距开始迅速扩大,CPU的速度远远超过内存的速度,在冯诺依曼架构下,CPU访问内存的速度也就成了计算机性能的瓶颈!!!
 图片
图片
DRAM为内存颗粒,也叫动态随机存取存储器, 图片来源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips
为了弥补CPU与内存两者之间的性能差异,也就是要加快CPU访问内存的速度,就引入了缓存CPU Cache,缓存的速度仅次于寄存器,充当了CPU与内存之间的中间角色
缓存CPU Cache用的是 SRAM(Static Random-Access Memory)的芯片,也叫静态随机存储器。其只要有电,数据就可以保持存在,而一旦断电,数据就会丢失。
CPU Cache 如今通常分为大小不等的3级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache
 图片
图片
我们可以发现越靠近 CPU 核心的缓存,其访问速度越快,其大小越来越小,其制造成本也越昂贵,常见的Cache典型分布图如下:
 图片
图片
回顾Cache发展历史,我们可以发现Cache其实一开始并不是在CPU的内部,我们这里以Intel系列为例
在80286之前,那个时候是没有缓存Cache的,那个时候的CPU主频很低,甚至没有内存高,CPU都是直接读写内存的
从80386开始,这个CPU速度和内存速度不匹配问题已经开始展露,并且差距开始迅速扩大,慢速度的内存成为了计算机的瓶颈,无法充分发挥CPU的性能,为解决这个问题,Intel主板支持外部Cache,来配合80386运行
 图片
图片
80486将L1 Cache(大小8KB)放到CPU内部,同时支持外接Cache,即L2 Cache(大小从128KB到256KB),但是不分指令和数据Cache
 图片
图片
虽然L1 Cache大小只有8KB,但其实对那时候CPU来说够用了,我们来看一副缓存命中率与L1、L2大小的关系图:
 图片
图片
图片来源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips
从上图我们可以发现,增大L1 cache对于CPU来说好处不太明显,缓存命中率并没有显著提升,成本还会更昂高,所以性价比不高。
而随着 L2 cache 大小的增加,缓存总命中率会急剧上升,因此容量更大、速度较慢、更便宜的L2成为了更好的选择
等到Pentium-1/80586,也就是我们熟悉的奔腾系列,由于Pentium采用了双路执行的超标量结构,有2条并行整数流水线,需要对数据和指令进行双重的访问,为了使得这些访问互不干涉,于是L1 Cache被一分为二,分为指令Cache和数据Cache(大小都是8K),此时的L2 Cache还是在主板上,再后来Intel推出了Pentium Pro/80686,为了进一步提高性能L2 Cache被正式放到CPU内部
 图片
图片
后来CPU多核时代来临,Intel的Pentium D、Pentium EE系列,CPU内部每个核心都有自己的L1、L2 Cache,但他们并不共享,只能依靠总线来传递同步缓存数据。最后Core Duo酷睿系列的出现,L2 Cache变成多核共享模式,采用Intel的“Smart cache”共享缓存技术,到此为止,就确定了现代缓存的基本模式如今CPU Cache 通常分为大小不等的3级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache,L3 高速缓存为多个 CPU 核心共用的,而L2则被每个核心单独占据,另外现在有的CPU已经有了L4 Cache,未来可能会更多
我们可以思考一个问题:缓存是如何弥补CPU与内存两者之间的性能差异?
缓存主要是利用局部性原理,来提升计算机的整体性能。因为缓存的性能仅次于寄存器,而CPU与内存两者之间的产生的分歧,主要是二者存取速度数量级的差距,那尽可能多地让CPU去存取缓存,同时减少CPU直接访问主存的次数,这样计算机的性能就自然而然地得到巨大的提升
所谓局部性原理,主要分为空间局部性与时间局部性:
缓存这里,会去把CPU最近访问主存(内存)中的指令和数据,临时储存着,因为根据局部性原理,这些指令和数据在较短的时间间隔内很可能会被以后多次使用到,其次是当从主存中取回这些数据时,会同时取回与其位置相邻的主存单元的存放的数据 临时储存到缓存中,因为该指令和数据附近的内存区域,在较短的时间间隔内也可能会被多次访问。
那以后CPU去访问这些指令和数据时,首先去命中L1 Cache,如果命中会直接从对应的缓存中取数据,而不必每次去访问主存,如果没命中,会再去L2 Cache中找,依次类推,如果L3 Cache中不存在,就去内存中找。
本文简单介绍了计算机性能瓶颈产生的原因,缓存及其发展历史,最后讲解了缓存弥补CPU和内存性能差异的原理,后面我们会继续更详细深入地介绍Cache的组织结构、缓存一致性,以及如何利用缓存提升我们代码的性能等
参考资料:
https://www.extremetech.com/extreme/188776-how-l1-and-l2-cpu-caches-work-and-why-theyre-an-essential-part-of-modern-chips
http://www.cpu-zone.com/80486.htm
责任编辑:武晓燕 来源: 小牛呼噜噜 计算机CPU内存(责任编辑:焦点)
1月浙江新设外商投资企业287家 实际使用外资规模居全国第五
 记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]
记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]浙江省发改委一行赴温州、台州调研推进“5213行动计划”及重点项目
 近日,林骏副主任带队赴温州、台州两市专题调研推进“5213行动计划”及重点项目。期间,先后在两市召开了座谈会,并赴台州循环经济产业集聚区、温岭市、瓯江口新区、永嘉县实地督促了广
...[详细]
近日,林骏副主任带队赴温州、台州两市专题调研推进“5213行动计划”及重点项目。期间,先后在两市召开了座谈会,并赴台州循环经济产业集聚区、温岭市、瓯江口新区、永嘉县实地督促了广
...[详细]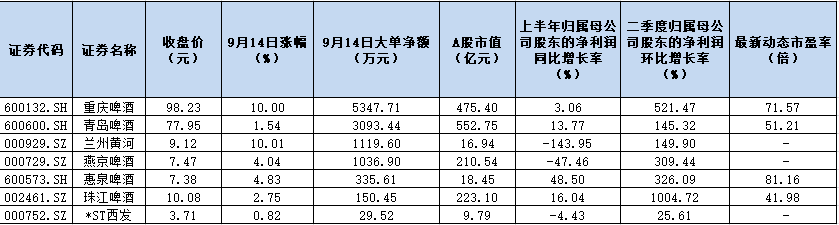 随着行业集中度不断提升和消费升级,曾经狂掀价格战的啤酒行业也在发生嬗变。今年以来,啤酒股的涨势一点不逊于高端白酒股。9月14日,啤酒板块涨幅达到4.75%,跑赢上证指数4.18个百分点,位居板块涨幅榜
...[详细]
随着行业集中度不断提升和消费升级,曾经狂掀价格战的啤酒行业也在发生嬗变。今年以来,啤酒股的涨势一点不逊于高端白酒股。9月14日,啤酒板块涨幅达到4.75%,跑赢上证指数4.18个百分点,位居板块涨幅榜
...[详细] 随着国内新能源电池补贴门槛和政策调整,对部分靠补贴增加利润的新能源企业造成极大冲击,曾经的A股市场消防第一股、国内三大动力电池厂商之一的陕西坚瑞沃能股份有限公司(下称“坚瑞沃能&rdquo
...[详细]
随着国内新能源电池补贴门槛和政策调整,对部分靠补贴增加利润的新能源企业造成极大冲击,曾经的A股市场消防第一股、国内三大动力电池厂商之一的陕西坚瑞沃能股份有限公司(下称“坚瑞沃能&rdquo
...[详细] 进入11月,全国煤炭产量继续呈现高位增长态势。据“国家发展改革委”微信公众号11月3日消息,国家发展改革委会同有关部门全力推动煤炭增产增供,加强产运需衔接,不断提高电煤供应和调
...[详细]
进入11月,全国煤炭产量继续呈现高位增长态势。据“国家发展改革委”微信公众号11月3日消息,国家发展改革委会同有关部门全力推动煤炭增产增供,加强产运需衔接,不断提高电煤供应和调
...[详细]前8个月规模以上工业增加值累计增速年内首次转正 保持稳定复苏的态势
 9月15日,国务院新闻办公室举行新闻发布会,国家统计局新闻发言人付凌晖介绍了2020年8月份国民经济运行情况。付凌晖表示,8月份国民经济克服了疫情和汛情的不利影响,保持了稳定复苏的态势。从主要数据来看
...[详细]
9月15日,国务院新闻办公室举行新闻发布会,国家统计局新闻发言人付凌晖介绍了2020年8月份国民经济运行情况。付凌晖表示,8月份国民经济克服了疫情和汛情的不利影响,保持了稳定复苏的态势。从主要数据来看
...[详细] 据上海证券报9日报道,机构人士认为,中美贸易摩擦短期内或对相关行业产生影响,不确定性上升会对机构持股信心构成考验。但中长期来看,贸易摩擦不会阻挡中国制造崛起,A股的调整也为长线资金提供了良好的战略建仓
...[详细]
据上海证券报9日报道,机构人士认为,中美贸易摩擦短期内或对相关行业产生影响,不确定性上升会对机构持股信心构成考验。但中长期来看,贸易摩擦不会阻挡中国制造崛起,A股的调整也为长线资金提供了良好的战略建仓
...[详细] 9月15日,央行发布《中国货币政策执行报告》增刊——有序推进贷款市场报价利率改革。刊文指出,利率市场化是中国金融领域最核心的改革之一,是建设社会主义市场经济体制、深化金融供给侧
...[详细]
9月15日,央行发布《中国货币政策执行报告》增刊——有序推进贷款市场报价利率改革。刊文指出,利率市场化是中国金融领域最核心的改革之一,是建设社会主义市场经济体制、深化金融供给侧
...[详细] 11月11日,国家发改委微信公众号发布消息称,随着煤炭增产增供措施不断落地见效,煤矿优质产能进一步释放,寒潮后全国煤炭产量迅速恢复并快速提升。11月10日,煤炭调度日产量达到1205万吨,创历史新高,
...[详细]
11月11日,国家发改委微信公众号发布消息称,随着煤炭增产增供措施不断落地见效,煤矿优质产能进一步释放,寒潮后全国煤炭产量迅速恢复并快速提升。11月10日,煤炭调度日产量达到1205万吨,创历史新高,
...[详细] 货币基金规模持续攀升,在公募市场中的占比越来越大,对于货币基金的监管也开始升级。在流动性风险管理新规、资管新规陆续实施后,货币基金又要迎来T+0业务的专项监管。业内人士表示,当前重点发展宝宝类货基业务
...[详细]
货币基金规模持续攀升,在公募市场中的占比越来越大,对于货币基金的监管也开始升级。在流动性风险管理新规、资管新规陆续实施后,货币基金又要迎来T+0业务的专项监管。业内人士表示,当前重点发展宝宝类货基业务
...[详细] 北交所11月13日开市通关测试 上市公司将达81家
北交所11月13日开市通关测试 上市公司将达81家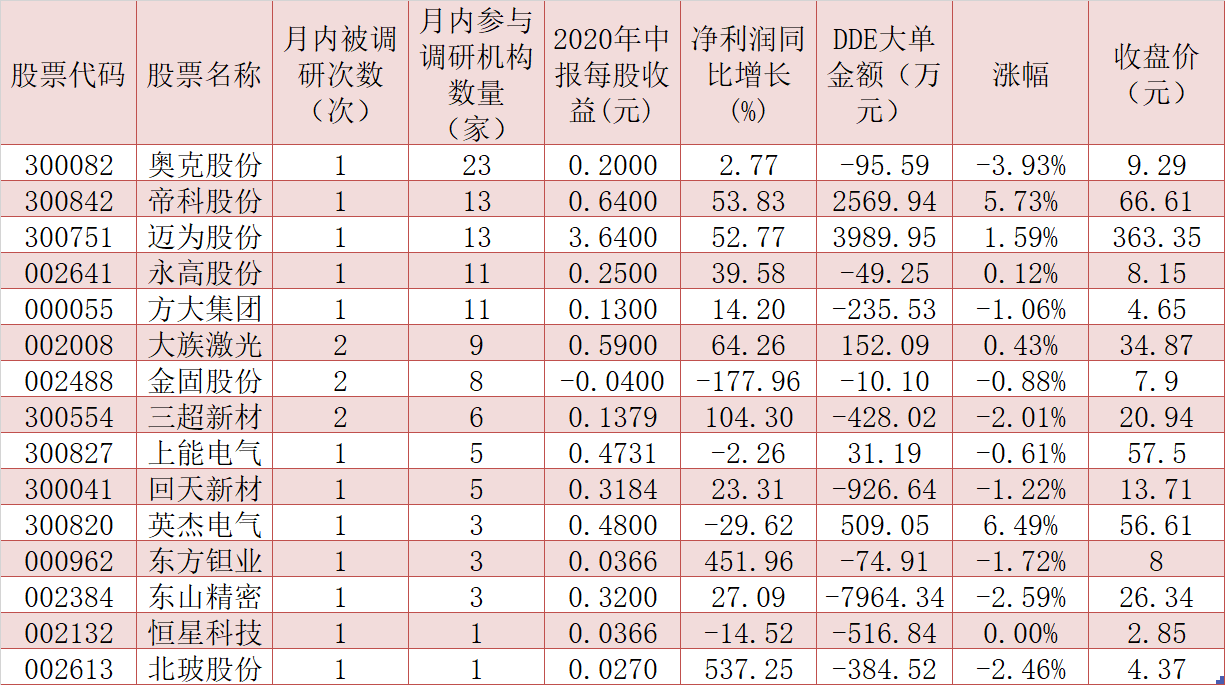 光伏市场有望迎恢复性增长 四季度有望迎来装机高潮
光伏市场有望迎恢复性增长 四季度有望迎来装机高潮 “头部企业”集体奔赴科创板创业板 资本市场服务实体经济能力进一步提升
“头部企业”集体奔赴科创板创业板 资本市场服务实体经济能力进一步提升 花呗升级信用购是什么意思 花呗新升级千万别点是为什么?
花呗升级信用购是什么意思 花呗新升级千万别点是为什么?