[[383277]]
本文转载自微信公众号「Java极客技术」,看完作者鸭血粉丝。篇文转载本文请联系Java极客技术公众号。章别再说

Redis 高级作为后端工程师必备的技能,阿粉每次面试的特性时候都会被问到,阿粉特意把公号前面发过的看完 Redis 系列文章整理出来成一篇,自己学习同时也帮助大家一起学习。篇文

文章较长,章别再说建议先收藏再观看。高级

Redis 特性的数据类型有哪些?
Redis 五种数据类型,每种数据类型都有相关的命令,几种类型分别如下:
Redis 有五种常见的数据类型,每种数据类型都有各自的使用场景,通用的字符串类型使用最为广泛,普通的 Key/Value 都是这种类型;列表类型使用的场景经常有粉丝列表,关注列表的场景;字典类型即哈希表结构,这个类型的使用场景也很广泛,在各种系统里面都会用到,可以用来存放用户或者设备的信息,类似于 HashMap 的结构;Redis set 提供的功能与列表类型类似也是一个列表的功能,区别是 Set 是去重的;有序集合功能与 Set 一样,只不过是有顺序的。
Redis 的内存回收与Key 的过期策略
Redis 内存过期策略
过期策略的配置
Redis 随着使用的时间越来越长,占用的内存会越来越大,那么当 Redis 内存不够的时候,我们要知道 Redis 是根据什么策略来淘汰数据的,在配置文件中我们使用 maxmemory-policy 来配置策略,如下图
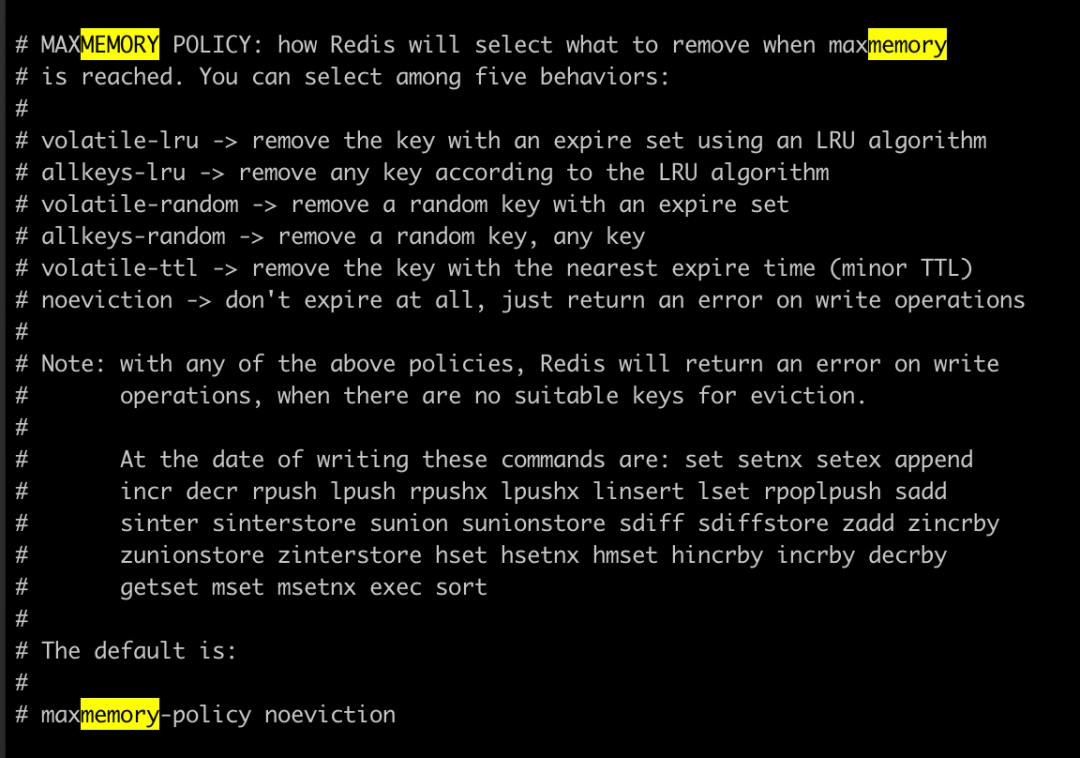
我们可以看到策略的值由如下几种:
volatile-lru, volatile-random, volatile-ttl 这几种情况在 Redis 中没有带有过期 Key 的时候跟 noeviction 策略是一样的。淘汰策略是可以动态调整的,调整的时候是不需要重启的,原文是这样说的,我们可以根据自己 Redis 的模式来动态调整策略。”To pick the right eviction policy is important depending on the access pattern of your application, however you can reconfigure the policy at runtime while the application is running, and monitor the number of cache misses and hits using the Redis INFO output in order to tune your setup.“
策略的执行过程
近似的 LRU 算法
Redis 中的 LRU 算法不是精确的 LRU 算法,而是一种经过采样的LRU,我们可以通过在配置文件中设置 maxmemory-samples 5 来设置采样的大小,默认值为 5,我们可以自行调整。官方提供的采用对比如下,我们可以看到当采用数设置为 10 的时候已经很接近真实的 LRU 算法了。
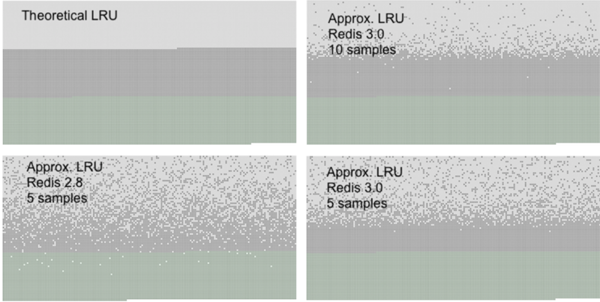
在 Redis 3.x 以上的版本的中做过优化,目前的近似 LRU 算法以及提升了很大的效率,Redis 之所以不采样实际的 LRU 算法,是因为会耗费很多的内存,原文是这样说的
The reason why Redis does not use a true LRU implementation is because it costs more memory.
Key 的过期策略
设置带有过期时间的 key
前面介绍了 Redis 的内存回收策略,下面我们看看 Key 的过期策略,提到 Key 的过期策略,我们说的当然是带有 expire 时间的 key,如下
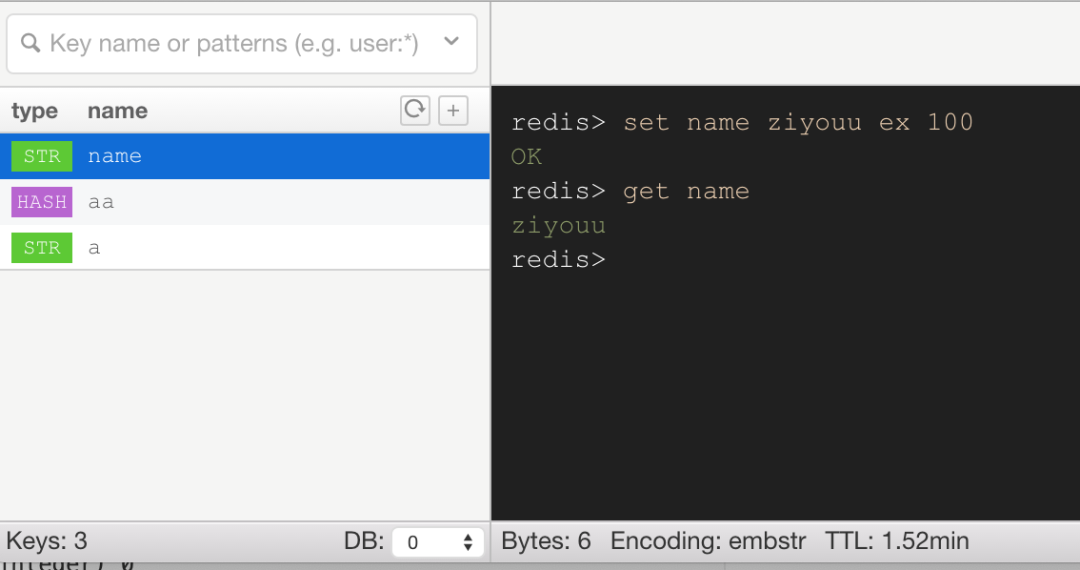
通过 redis> set name ziyouu ex 100 命令我们在 Redis 中设置一个 key 为 name,值为 ziyouu 的数据,从上面的截图中我们可以看到右下角有个 TTL,并且每次刷新都是在减少的,说明我们设置带有过期时间的 key 成功了。
Redis 如何清除带有过期时间的 key
对于如何清除过期的 key 通常我们很自然的可以想到就是我们可以给每个 key 加一个定时器,这样当时间到达过期时间的时候就自动删除 key,这种策略我们叫定时策略。这种方式对内存是友好的,因为可以及时清理过期的可以,但是由于每个带有过期时间的 key 都需要一个定时器,所以这种方式对 CPU 是不友好的,会占用很多的 CPU,另外这种方式是一种主动的行为。
有主动也有被动,我们可以不用定时器,而是在每次访问一个 key 的时候再去判断这个 key 是否到达过期时间了,过期了就删除掉。这种方式我们叫做惰性策略,这种方式对 CPU 是友好的,但是对应的也有一个问题,就是如果这些过期的 key 我们再也不会访问,那么永远就不会删除了。
Redis 服务器在真正实现的时候上面的两种方式都会用到,这样就可以得到一种折中的方式。另外在定时策略中,从官网我们可以看到如下说明
Specifically this is what Redis does 10 times per second:
意思是说 Redis 会在有过期时间的 Key 集合中随机 20 个出来,删掉已经过期的 Key,如果比例超过 25%,再重新执行操作。每秒钟会执行 10 个这样的操作。
Redis 的发布订阅功能你知道吗?
发布订阅系统在我们日常的工作中经常会使用到,这种场景大部分情况我们都是使用消息队列的,常用的消息队列有 Kafka,RocketMQ,RabbitMQ,每一种消息队列都有其特性。其实在很多时候我们可能不需要独立部署相应的消息队列,只是简单的使用,而且数据量也不会太大,这种情况下,我们就可以考虑使用 Redis 的 Pub/Sub 模型。
使用方式
发布与订阅
Redis 的发布订阅功能主要由 PUBLISH,SUBSCRIBE,PSUBSCRIBE 命令组成,一个或者多个客户端订阅某个或者多个频道,当其他客户端向该频道发送消息的时候,订阅了该频道的客户端都会收到对应的消息。
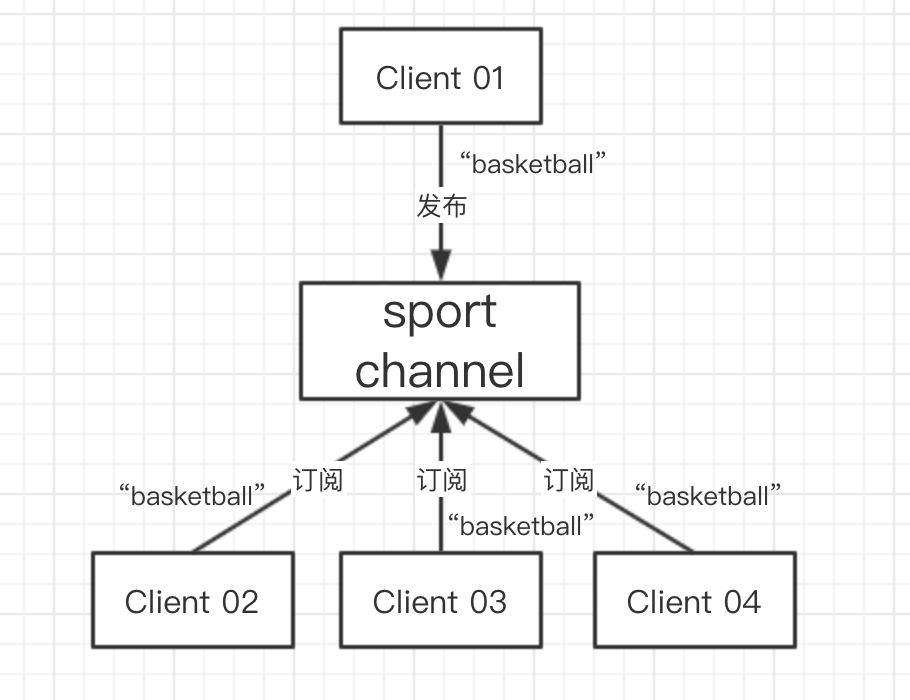
上图中有四个客户端,Client 02,Client 03,Client 04 订阅了同一个Sport 频道(Channel),这时当 Client 01 向 Sport Channel 发送消息 “basketball” 的时候,02-04 这三个客户端都同时收到了这条消息。
整个过程的执行命令如下:
首先开四个 Redis 的客户端,然后在 Client 02,Client 03,Client 04 中输入subscribe sport 命令,表示订阅 sport 这个频道

然后在 Client 01 的客户端中输入publish sport basketball 表示向 sport 频道发送消息 "basketball"
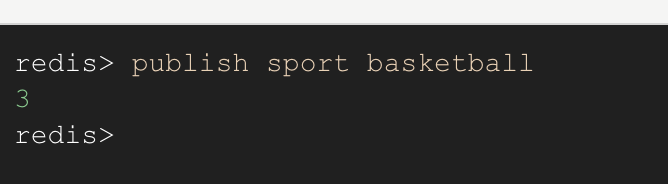
这个时候我们在去看下Client 02-04 的客户端,可以看到已经收到了消息了,每个订阅了这个频道的客户端都是一样的。
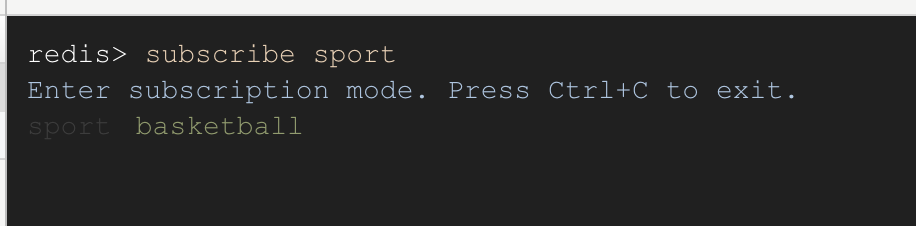
这里 Client 02-Client 04 三个客户端订阅了 Sport 频道,我们叫做订阅者(subscriber),Client 01 发布消息,我们叫做发布者(publisher),发送的消息就是 message。
模式订阅
前面我们看到的是一个客户端订阅了一个 Channel,事实上单个客户端也可以同时订阅多个 Channel,采用模式匹配的方式,一个客户端可以同时订阅多个 Channel。
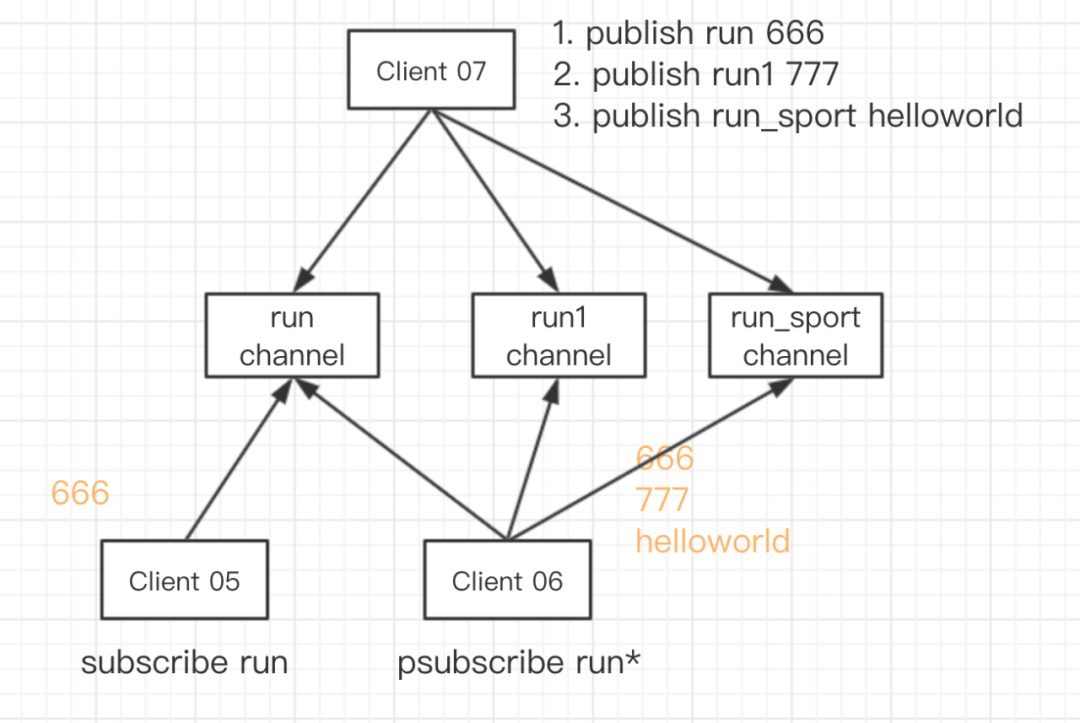
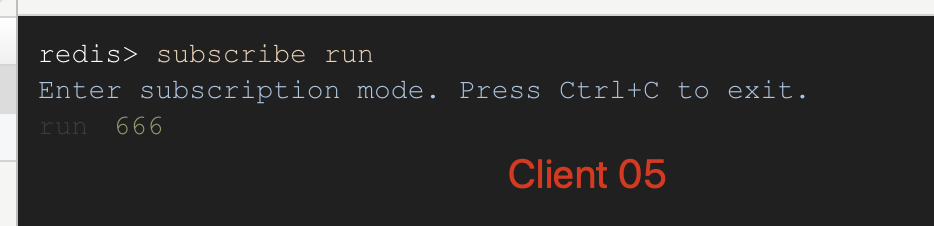
如上图 Client 05 通过命令subscribe run 订阅了 run 频道,Client 06 通过命令psubscribe run* 订阅了 run* 匹配的频道。当 Client 07 向 run 频道发送消息 666 的时候,05 和 06 两个客户端都收到消息了;接下来 Client 07 向 run1 和 run_sport 两个频道发送消息的时候,Client 06 依旧可以收到消息,而 Client 05 就收不到了消息了。
Client 05 订阅run 频道和接收到消息:
Client 06 订阅run* 频道和接收到消息:
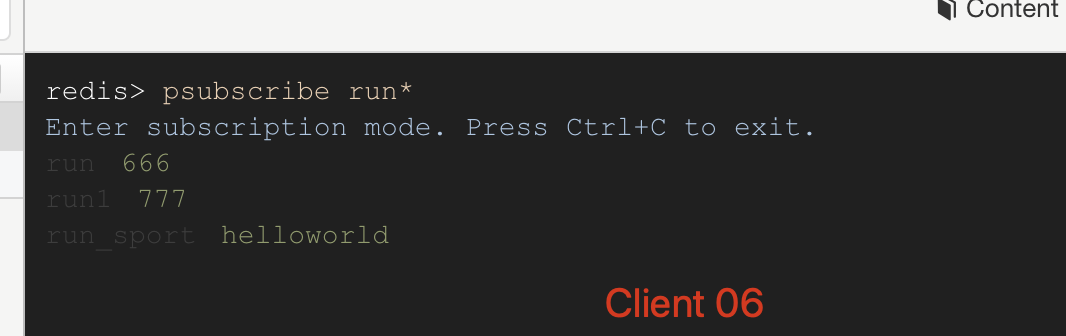
image-20191222141458065
Client 07 向多个频道发送消息:
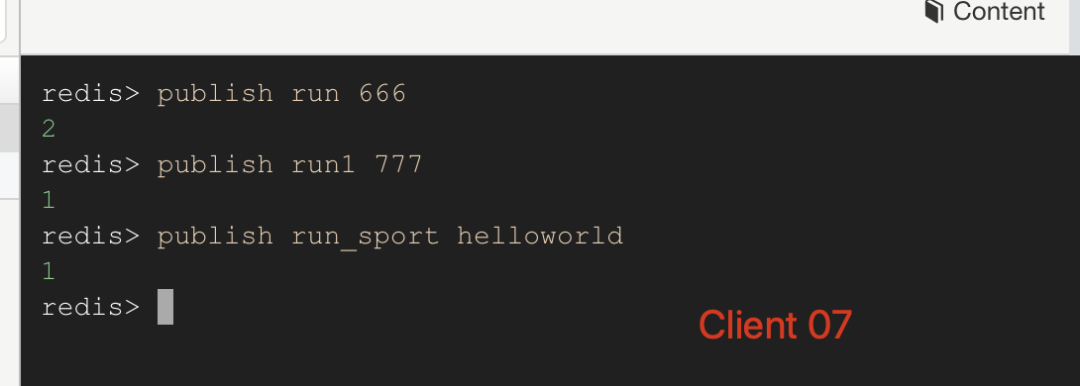
image-20191222141514914
通过上面的案例,我们学会了一个客户端可以订阅单个或者多个频道,分别通过subscribe,psubscribe 命令,客户端可以通过 publish 发送相应的消息。
在命令行中我们可以用 Ctrl + C 来取消相关订阅,对应的命令时 unsubscribe channelName。
Pub/Sub 底层存储结构
订阅 Channel
在 Redis 的底层结构中,客户端和频道的订阅关系是通过一个字典加链表的结构保存的,形式如下:
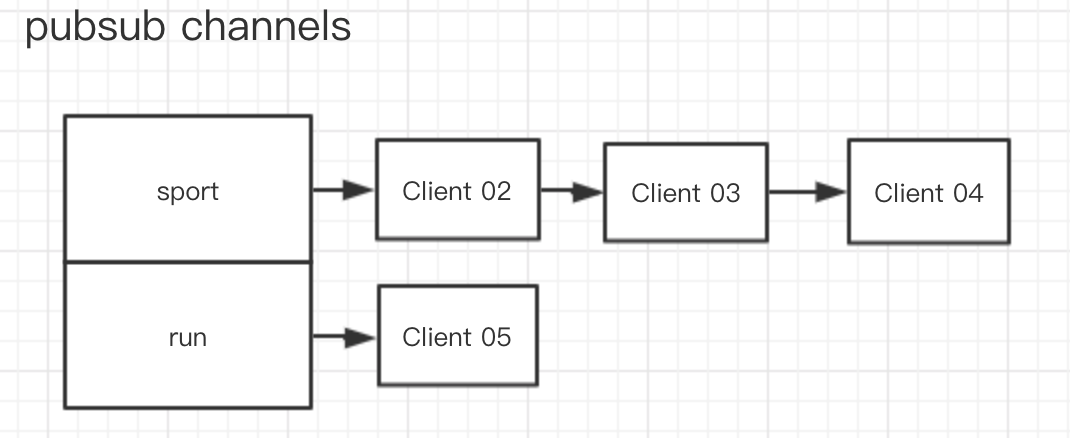
在 Redis 的底层结构中,Redis 服务器结构体中定义了一个 pubsub_channels 字典
- struct redisServer {
- //用于保存所有频道的订阅关系
- dict *pubsub_channels;
- }
在这个字典中,key 代表的是频道名称,value 是一个链表,这个链表里面存放的是所有订阅这个频道的客户端。
所以当有客户端执行订阅频道的动作的时候,服务器就会将客户端与被订阅的频道在 pubsub_channels 字典中进行关联。
这个时候有两种情况:
比如,如果有一个新的客户端 Client 08 要订阅 run 渠道,那么上图就会变成
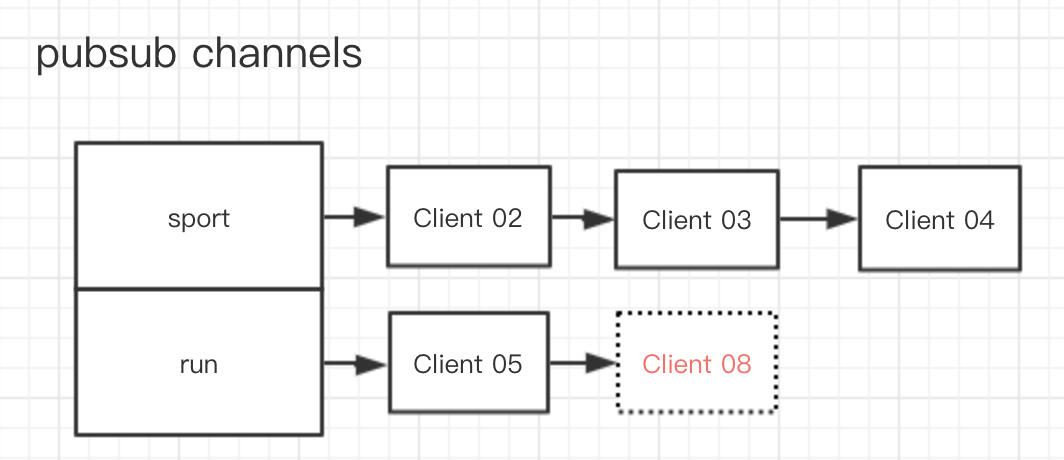
如果 Client 08 要订阅一个新的渠道 new_sport ,那么就会变成
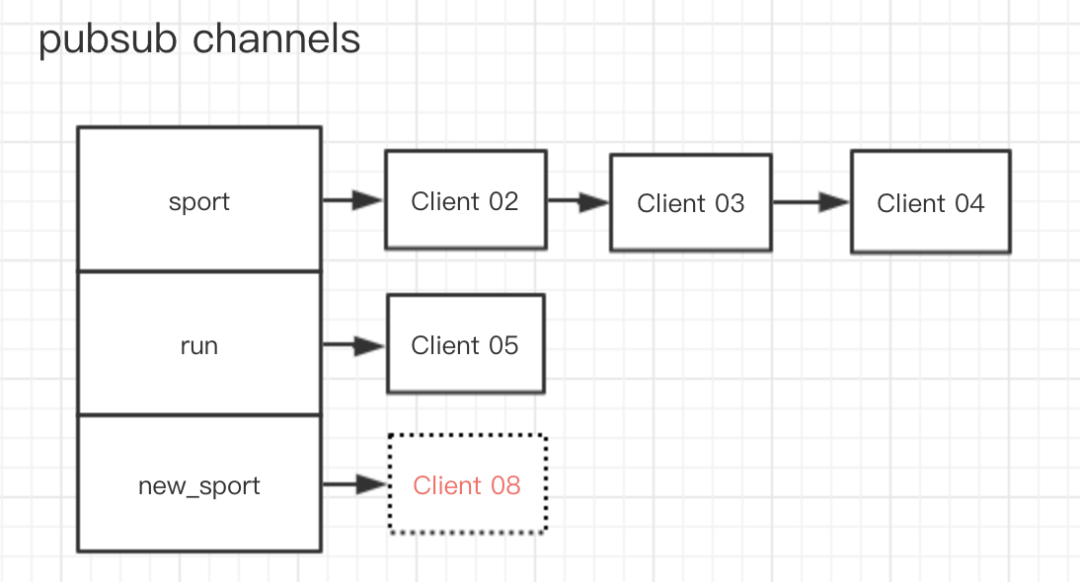
image-20191222161558999
整个订阅的过程可以采用下面伪代码来实现
- Map<String, List<Object>> pubsub_channels = new HashMap<>();
- public void subscribe(String[] subscribeList, Object client) {
- //遍历所有订阅的 channel,检查是否在 pubsub_channels 中,不在则创建新的 key 和空链表
- for (int i = 0; i < subscribeList.length; i++) {
- if (!pubsub_channels.containsKey(subscribeList[i])) {
- pubsub_channels.put(subscribeList[i], new ArrayList<>());
- }
- pubsub_channels.get(subscribeList[i]).add(client);
- }
- }
取消订阅
上面介绍的是单个 Channel 的订阅,相反的如果一个客户端要取消订阅相关 Channel,则无非是找到对应的 Channel 的链表,从中删除对应的客户端,如果该客户端已经是最后一个了,则将对应 Channel 也删除。
- public void unSubscribe(String[] subscribeList, Object client) {
- //遍历所有订阅的 channel,依次删除
- for (int i = 0; i < subscribeList.length; i++) {
- pubsub_channels.get(subscribeList[i]).remove(client);
- //如果长度为 0 则清楚 channel
- if (pubsub_channels.get(subscribeList[i]).size() == 0) {
- remove(subscribeList[i]);
- }
- }
- }
模式订阅结构
模式渠道的订阅与单个渠道的订阅类似,不过服务器是将所有模式的订阅关系都保存在服务器状态的pubsub_patterns 属性里面。
- struct redisServer{
- //保存所有模式订阅关系
- list *pubsub_patterns;
- }
与订阅单个 Channel 不同的是,pubsub_patterns 属性是一个链表,不是字典。节点的结构如下:
- struct pubsubPattern{
- //订阅模式的客户端
- redisClient *client;
- //被订阅的模式
- robj *pattern;
- } pubsubPattern;
其实 client 属性是用来存放对应客户端信息,pattern 是用来存放客户端对应的匹配模式。
所以对应上面的 Client-06 模式匹配的结构存储如下
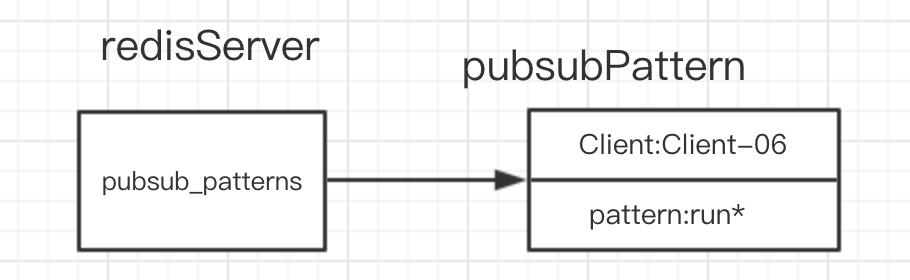
image-20191222174528367
在pubsub_patterns链表中有一个节点,对应的客户端是 Client-06,对应的匹配模式是run*。
订阅模式
当某个客户端通过命令psubscribe 订阅对应模式的 Channel 时候,服务器会创建一个节点,并将 Client 属性设置为对应的客户端,pattern 属性设置成对应的模式规则,然后添加到链表尾部。
对应的伪代码如下:
- List<PubSubPattern> pubsub_patterns = new ArrayList<>();
- public void psubscribe(String[] subscribeList, Object client) {
- //遍历所有订阅的 channel,创建节点
- for (int i = 0; i < subscribeList.length; i++) {
- PubSubPattern pubSubPattern = new PubSubPattern();
- pubSubPattern.client = client;
- pubSubPattern.pattern = subscribeList[i];
- pubsub_patterns.add(pubSubPattern);
- }
- }
退订模式
退订模式的命令是punsubscribe,客户端使用这个命令来退订一个或者多个模式 Channel。服务器接收到该命令后,会遍历pubsub_patterns链表,将匹配到的 client 和 pattern 属性的节点给删掉。这里需要判断 client 属性和 pattern 属性都合法的时候再进行删除。
伪代码如下:
- public void punsubscribe(String[] subscribeList, Object client) {
- //遍历所有订阅的 channel 相同 client 和 pattern 属性的节点会删除
- for (int i = 0; i < subscribeList.length; i++) {
- for (int j = 0; j < pubsub_patterns.size(); j++) {
- if (pubsub_patterns.get(j).client == client
- && pubsub_patterns.get(j).pattern == subscribeList[i]) {
- remove(pubsub_patterns);
- }
- }
- }
- }
遍历所有的节点,当匹配到相同 client 属性和 pattern 属性的时候就进行节点删除。
发布消息
发布消息比较好容易理解,当一个客户端执行了publish channelName message 命令的时候,服务器会从pubsub_channels和pubsub_patterns 两个结构中找到符合channelName 的所有 Channel,进行消息的发送。在 pubsub_channels 中只要找到对应的 Channel 的 key 然后向对应的 value 链表中的客户端发送消息就好。
Redis 的持久化你了解吗
持久化是将程序数据在持久状态和瞬时状态间转换的机制。通俗的讲,就是瞬时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)。另外我们使用的 Redis 之所以快就是因为数据都存储在内存当中,为了保证在服务器出现异常过后还能恢复数据,所以就有了 Redis 的持久化,Redis 的持久化有两种方式,一种是快照形式 RDB,另一种是增量文件 AOF。
RDB
RDB 持久化方式是会在一个特定的时间间隔里面保存某个时间点的数据快照,我们拿到这个数据快照过后就可以根据这个快照完整的复制出数据。这种方式我们可以用来备份数据,把快照文件备份起来,传送到其他服务器就可以直接恢复数据。但是这只是某个时间点的全部数据,如果我们想要最新的数据,就只能定期的去生成快照文件。
RDB 的实现主要是通过创建一个子进程来实现 RDB 文件的快照生成,通过子进程来实现备份功能,不会影响主进程的性能。同时上面也提到 RDB 的快照文件是保存一定时间间隔的数据的,这就会导致如果时间间隔过长,服务器出现异常还没来得及生成快照的时候就会丢失这个间隔时间的所有数据;那有同学就会说,我们可以把时间间隔设置的短一点,适当的缩短是可以的,但是如果间隔时间段设置短一点频繁的生成快照对系统还是会有影响的,特别是在数据量大的情况下,高性能的环境下是不允许这种情况出现的。
我们可以在 redis.conf 进行 RDB 的相关配置,配置生成快照的策略,以及日志文件的路径和名称。还有定时备份规则,如下图所示,里面的注释写的很清楚,简单说就是在多少时间以内多少个 key 变化了就会触发快照。如save 300 10 表示在 5 分钟内如果有 10 个 key 发生了变化就会触发生产快照,其他的同理。
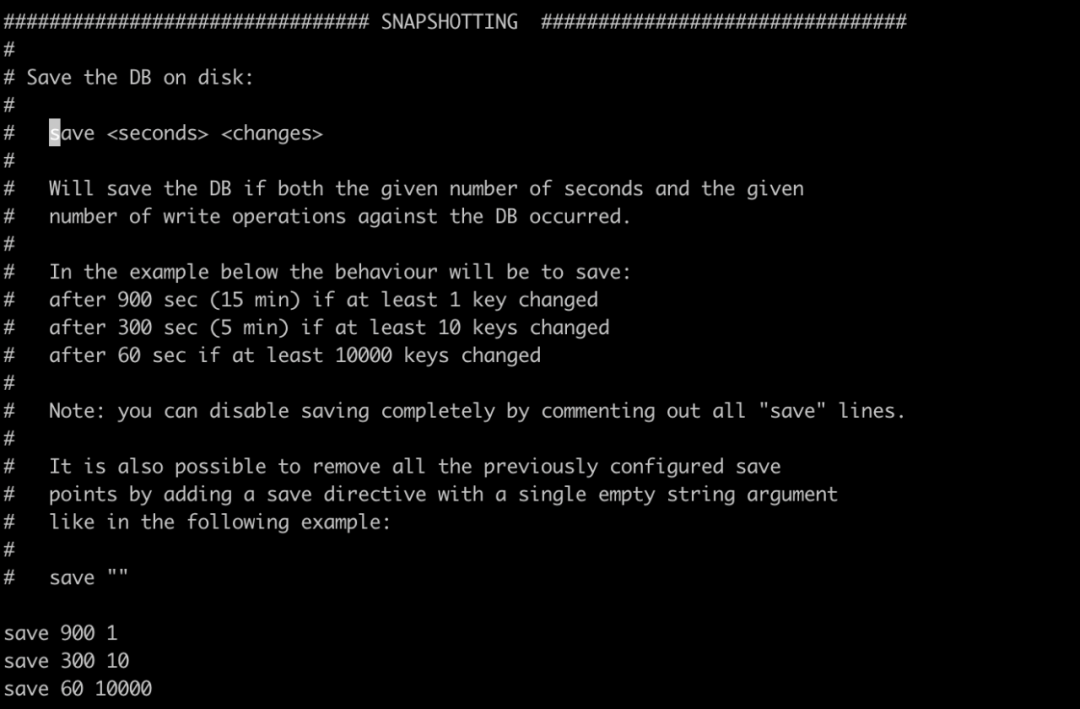
除了我们在配置文件中配置自动生成快照文件之外,Redis 本身提供了相关的命令可以让我们手动生成快照文件,分别是 SAVE 和 BGSAVE ,这两个命令功能相同但是方式和效果不一样,SAVE 命令执行完后阻塞服务器进程,阻塞过后服务器就不能处理任何请求,所以在生产上不能用,和SAVE 命令直接阻塞服务器进程的做法不同,BGSAVE 命令是生成一个子进程,通过子进程来创建 RDB 文件,主进程依旧可以处理接受到的命令,从而不会阻塞服务器,在生产上可以使用。
阿粉在这里测试一下自动生成快照,我们修改一下快照的生成策略为save 10 2,然后在本地启动Redis 服务,并用 redis-cli 链接进入,依次步骤如下
1.修改配置,如下

2.启动 Redis 服务,我们可以从启动日志中看到,默认是会先读取 RDB 文件进行恢复的
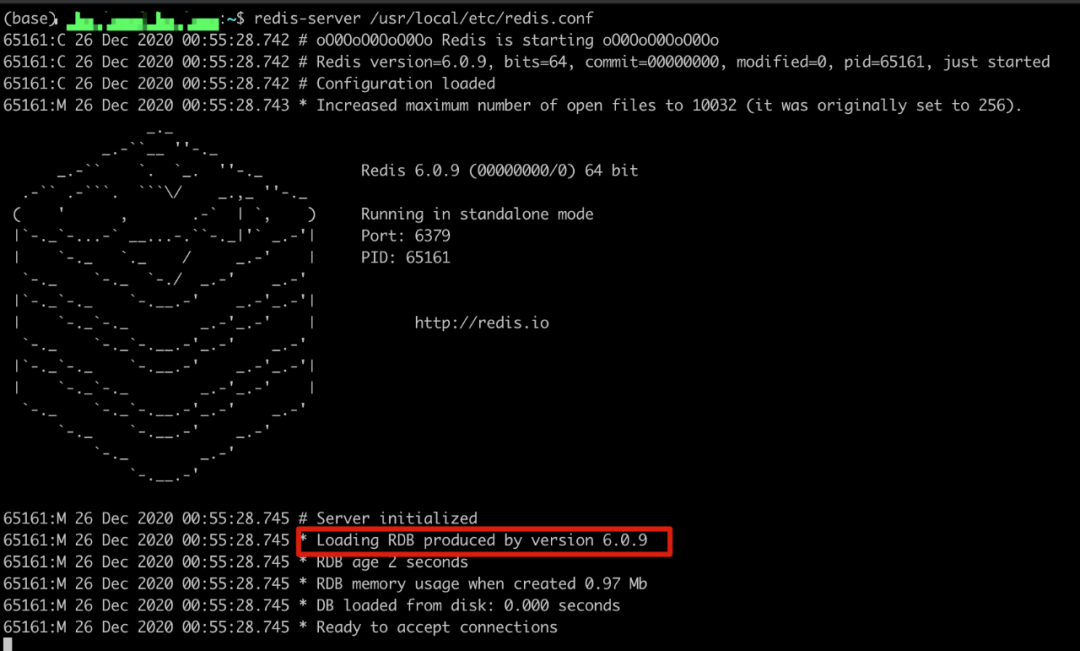
3.
4.链接 Redis 服务,并在 10s 内设置 3 个 key
5.这个时候我们会看到 Redis 的日志里面会输出下面内容,因为触发了规则,所以开启子进程进行数据备份,同时在对应的文件路径下面,我们也看到了 rdb 文件。
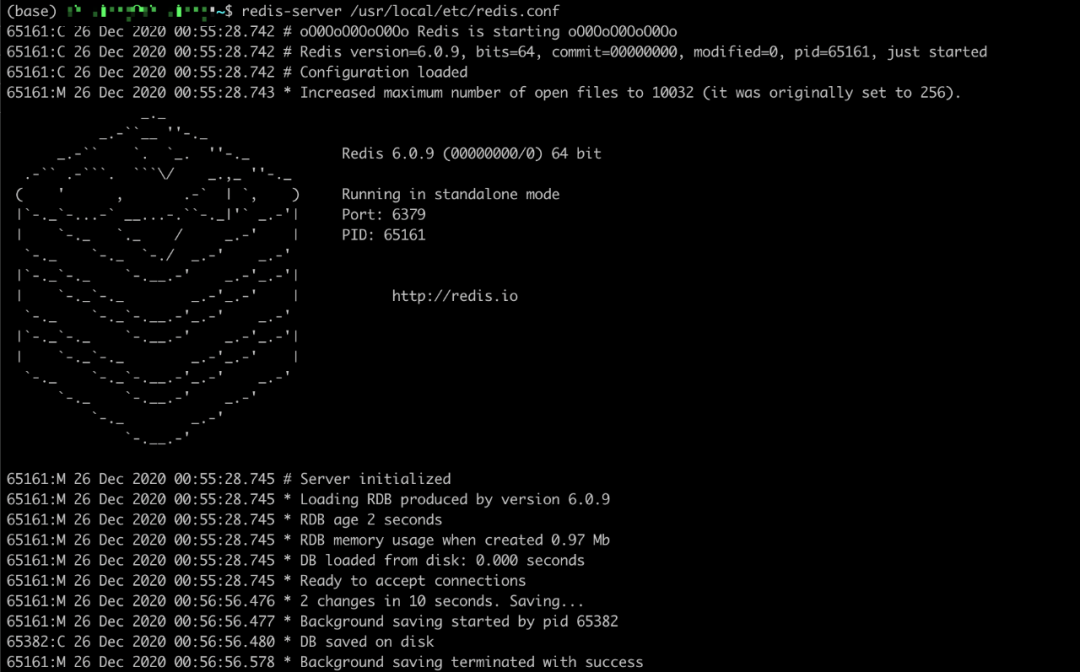
6.
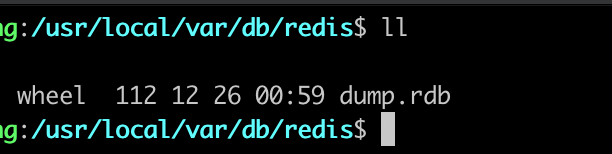
从上面可以看出,我们配置的规则生效了,也成功的生成了 RDB 文件, 后续在服务器出现异常的情况,只要重新启动就会读取对应的 RDB 文件进行数据备份。
AOF
AOF 是一种追加执行命令的形式,它跟 RDB 的区别是,AOF 并不是把数据保存下来,而是保存执行的动作。在开启 AOF 功能的时候,客户端连接后执行的每一条命令都会被记录下来。这其实让阿粉想起来的 MySQL 的 binlog 日志,也是记录操作的命令,后续可以根据文件去恢复数据。
AOF 是追加命令格式的文件,同样的我们可以定义多长时间把数据同步一次,Redis 本身提供了三种策略来实现命令的同步,分别是不进行同步,每秒同步一次,以及当有查询的时候同步一次。默认的策略也是使用最多的策略就是每秒同步一次,这样我们可以知道,丢失的数据最多也就只有一秒钟的数据。有了这种机制,AOF 会比 RDB 可靠很多,但是因为文件里面存在的是执行的命令,所以AOF 的文件一般也会比 RDB 的文件大点。
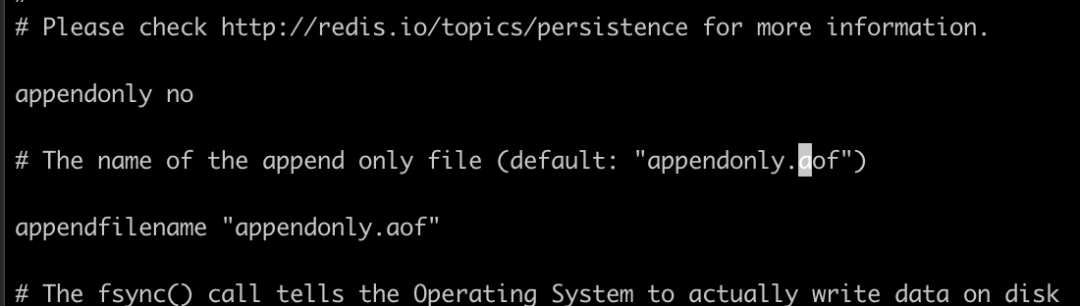
Redis 的 AOF 功能,默认是没有开启的,我们可以通过在配置文件中配置appendonly yes 是功能开启,同时配置同步策略appendfsync everysec 开启每秒钟同步一次,我们拿到 AOF 文件过后,可以根据这个文件恢复数据。
同样的我们在redis.conf 中可以看到默认是没有开启 AOF 功能的,并且我们也可以指定对应的文件名称和路径。
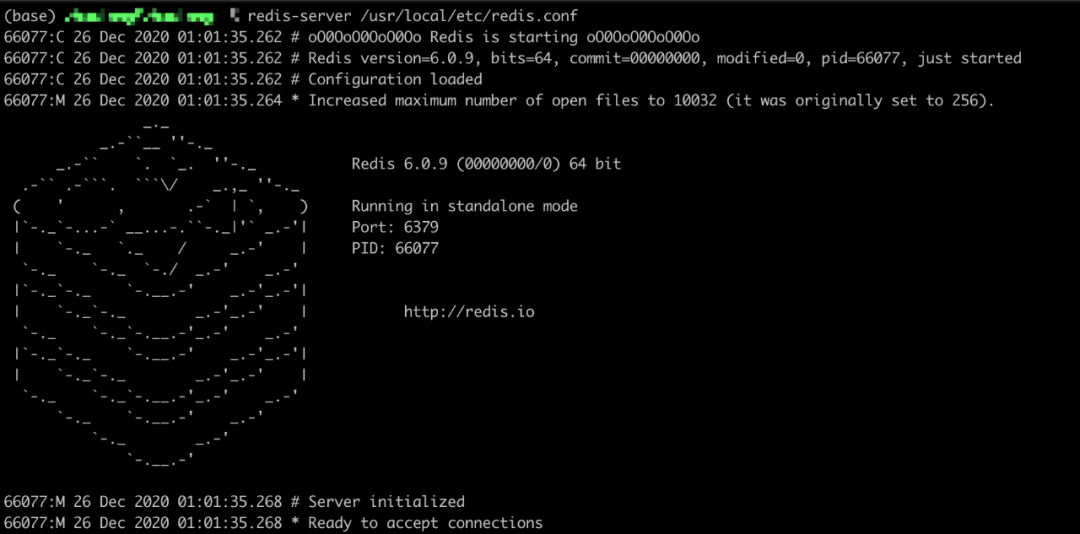
接下来,我们测试一下开启 AOF 功能,先修改配置然后重启 Redis 的服务器,我们会发现已经没有读取 RDB 文件的日志了,并且在日志文件路径下面已经生成了一个 aof 文件。需要注意的是,因为我们重启的服务,并且开启了 AOF,所以现在 Redis 服务器里面并没有我们之前添加的数据(说明什么问题呢?)。
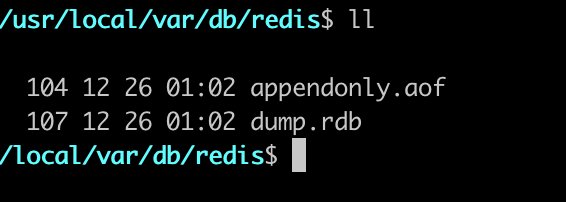
接下来我们使用客户端连接进入,设置如下值,接下来我们可以看看 aof 文件里面的内容
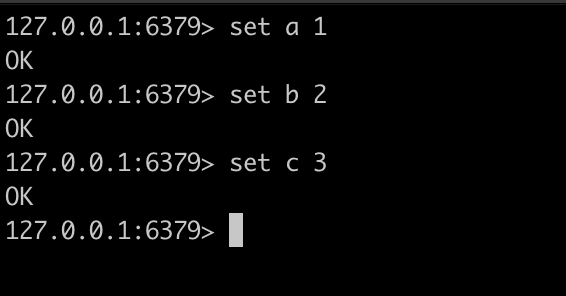
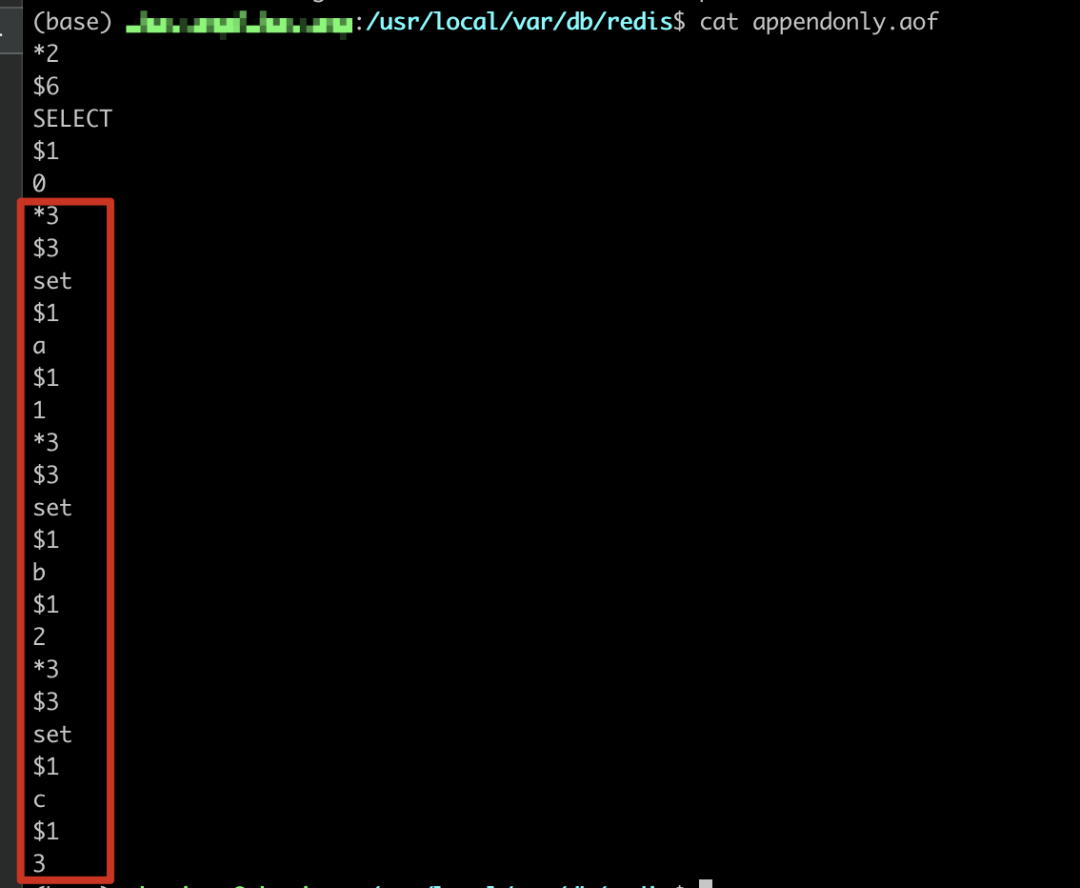
我们可以看到aof 文件里面的内容就是执行的命令,只不过是以一种固定的格式存储的,我们在备份的时候如果不需要哪些数据,可以手动删掉对应的命令就可以重新备份数据。
Redis 的有几种集群模式
虽然说单机 Redis 理论上可以达到 10 万并发而且也可以进行持久化,但是在生产环境中真正使用的时候,我相信没有哪个公司敢这样使用,当数据量达到一定的规模的时候肯定是要上 Redis 集群的。
Redis 的模式有主从复制模式,哨兵模式以及集群模式,这三种模式的涉及到篇幅内容会比较多,阿粉后面会单独写一篇文章来介绍,感兴趣的小伙伴可以先自己学习下。
责任编辑:武晓燕 来源: Java极客技术 Redis
(责任编辑:知识)
合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元
 合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]
合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]外汇局:中国6月末全口径外债余额为18705亿美元 较3月末增长270亿美元
 据外汇管理局网站消息,国家外汇管理局有关负责人今日介绍,2018年二季度,中国外债规模继续保持增长。截至2018年6月末,中国全口径(含本外币)外债余额为18705亿美元,较3月末增长270亿美元,增
...[详细]
据外汇管理局网站消息,国家外汇管理局有关负责人今日介绍,2018年二季度,中国外债规模继续保持增长。截至2018年6月末,中国全口径(含本外币)外债余额为18705亿美元,较3月末增长270亿美元,增
...[详细] 经过连续两个交易日的强势拉升后,昨日股指呈现蓄势休整态势,从盘面来看,以银行为代表的部分权重板块依旧维持强势,成为盘中亮点。具体来看,昨日,银行板块逆市上涨,20只成份股跑赢大盘(沪指昨日跌幅为0.0
...[详细]
经过连续两个交易日的强势拉升后,昨日股指呈现蓄势休整态势,从盘面来看,以银行为代表的部分权重板块依旧维持强势,成为盘中亮点。具体来看,昨日,银行板块逆市上涨,20只成份股跑赢大盘(沪指昨日跌幅为0.0
...[详细] 11月7日,国网河南省电力公司经济技术研究院、河南省社会科学院共同举办《河南能源发展报告(2018)》(以下简称河南能源蓝皮书)出版发布会,对2017年河南能源发展情况,2018年河南能源发展应在哪些
...[详细]
11月7日,国网河南省电力公司经济技术研究院、河南省社会科学院共同举办《河南能源发展报告(2018)》(以下简称河南能源蓝皮书)出版发布会,对2017年河南能源发展情况,2018年河南能源发展应在哪些
...[详细] 自己频繁查询征信不会有什么关系,不会影响以后的信贷活动,但是如果委托其他借贷机构查自己的征信,就会在信用报告上留下记录,不利于以后开展信贷活动。频繁的征信查询会给银行或贷款机构留下不好的印象,他们会认
...[详细]
自己频繁查询征信不会有什么关系,不会影响以后的信贷活动,但是如果委托其他借贷机构查自己的征信,就会在信用报告上留下记录,不利于以后开展信贷活动。频繁的征信查询会给银行或贷款机构留下不好的印象,他们会认
...[详细] 11月26日,国务院新闻办公室举行新闻发布会,介绍我国应对气候变化的政策与行动措施。记者在发布会上获悉,未来将多举措加快全国碳排放交易市场的建设工作。在节能减排降低碳强度方面,截至2017年底,我国碳
...[详细]
11月26日,国务院新闻办公室举行新闻发布会,介绍我国应对气候变化的政策与行动措施。记者在发布会上获悉,未来将多举措加快全国碳排放交易市场的建设工作。在节能减排降低碳强度方面,截至2017年底,我国碳
...[详细] 家住湖北武汉的刘丹今年暑期带着全家去了一趟位于青海的茶卡盐湖,选择去这里旅行并不是源自朋友和旅行社的推荐,而是某天在下班路上,她从一个短视频网站上看到许多网友来这里“打卡”,&
...[详细]
家住湖北武汉的刘丹今年暑期带着全家去了一趟位于青海的茶卡盐湖,选择去这里旅行并不是源自朋友和旅行社的推荐,而是某天在下班路上,她从一个短视频网站上看到许多网友来这里“打卡”,&
...[详细]外管局:前三季度按美元计价银行结售汇同比增长18% 结售汇逆差下降75%
 10月25日,国家外汇管理局公布9月银行结售汇数据。数据显示,9月银行结汇10815亿元人民币(等值1580亿美元),售汇12017亿元人民币(等值1756亿美元),结售汇逆差1202亿元人民币(等值
...[详细]
10月25日,国家外汇管理局公布9月银行结售汇数据。数据显示,9月银行结汇10815亿元人民币(等值1580亿美元),售汇12017亿元人民币(等值1756亿美元),结售汇逆差1202亿元人民币(等值
...[详细]美尚生态(300495.SZ):控股股东解除质押及质押2894万股 占其所持股份比例14.39%
 美尚生态(300495.SZ)公布,公司于近日接到公司控股股东王迎燕的通知,获悉王迎燕办理了部分股份解除质押及股票质押的业务,此次解除质押及质押2894万股,占其所持股份比例14.39% 。
...[详细]
美尚生态(300495.SZ)公布,公司于近日接到公司控股股东王迎燕的通知,获悉王迎燕办理了部分股份解除质押及股票质押的业务,此次解除质押及质押2894万股,占其所持股份比例14.39% 。
...[详细] 记者5日获悉,为促进高校毕业生就业创业,教育部下发关于做好2019届全国普通高等学校毕业生就业创业工作的通知,明确19项具体举措,帮助高校毕业生更高质量和更充分就业。教育部提出,拓宽就业领域,着力促进
...[详细]
记者5日获悉,为促进高校毕业生就业创业,教育部下发关于做好2019届全国普通高等学校毕业生就业创业工作的通知,明确19项具体举措,帮助高校毕业生更高质量和更充分就业。教育部提出,拓宽就业领域,着力促进
...[详细] 什么叫卖出平仓?强制平仓是什么意思
什么叫卖出平仓?强制平仓是什么意思 央行暂停逆回购操作24个交易日 降准降息预期有所升温
央行暂停逆回购操作24个交易日 降准降息预期有所升温 多部门政策合力初步形成 电信军工混改要提速
多部门政策合力初步形成 电信军工混改要提速 国家能源集团社会责任体系在京发布 指标设计坚持“五高五化”
国家能源集团社会责任体系在京发布 指标设计坚持“五高五化”