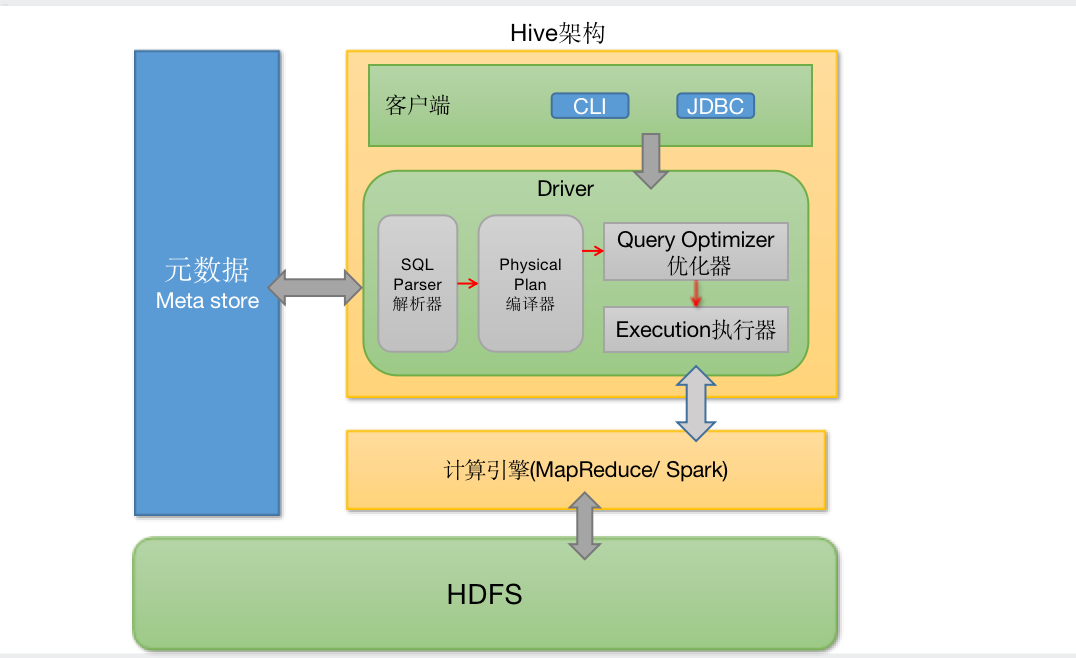
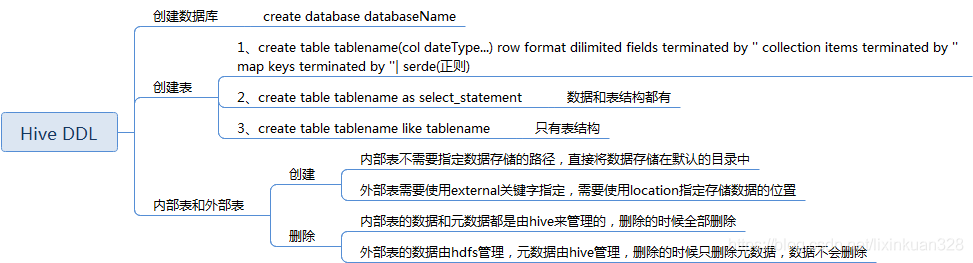
Hive是操作建立在Hadoop上的数据仓库工具,它允许用户通过类SQL的视图语法来查询和管理数据。在Hive中,大数DDL(数据定义语言)和视图操作是据H讲解非常常见的。
表和视图都是操作数据存储的逻辑表示方式。它们之间有以下关系:
总之,表和视图都是数据存储和管理的方式,它们有各自的优点和适用场景。在Hive中,用户可以根据实际需要选择使用表还是视图来满足不同的数据访问和管理需求。
在Hive中,表和视图也是数据存储的逻辑表示方式,但它们之间存在以下区别:
总之,在Hive中,表和视图都有各自的优点和适用场景。用户可以根据实际需求选择使用哪种方式来存储和管理数据,以及在查询数据时使用哪种方式来提高效率和简化操作。
如果已经有了环境了,可以忽略,如果想快速部署环境可以参考我这篇文章:通过 docker-compose 快速部署 Hive 详细教程
# 登录容器docker exec -it hive-hiveserver2 bash# 连接hivebeeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoopHive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括数组,map,struct。
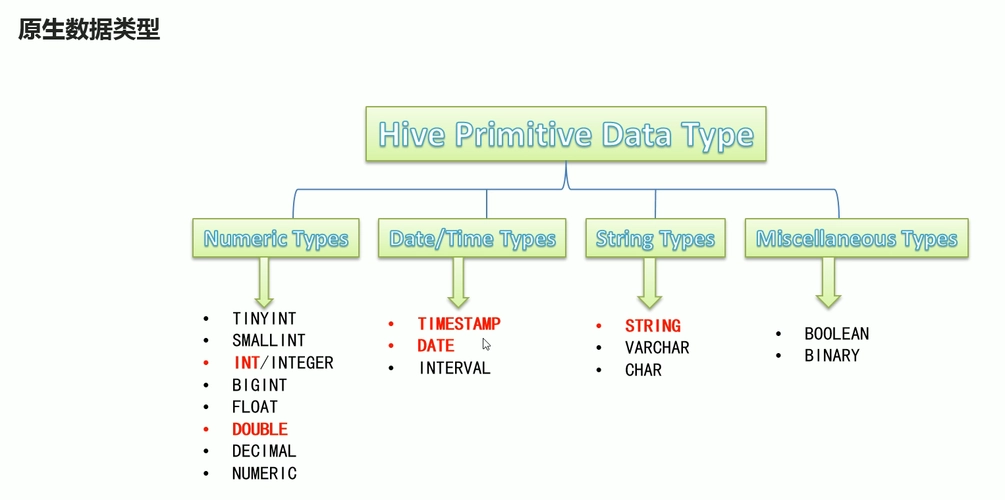
下面是Hive数据类型汇总:
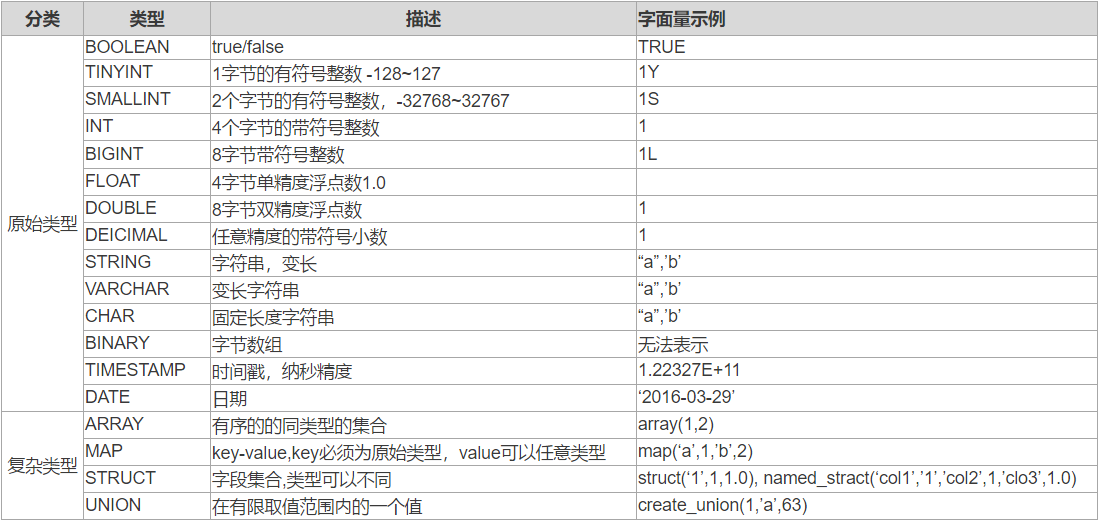
在Hive中,你可以使用HiveQL语言来创建表。下面是一些创建表的基本语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [column_constraint_specification] [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES]] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]其中,[] 表示可选项,...表示省略的内容。
以下是一些常见的参数解释:
### hive文件存储格式包括以下几类(STORED AS TEXTFILE):1.TEXTFILE:按行存储的文本文件格式。默认为TEXTFILE。2.SEQUENCEFILE:二进制序列文件格式,其中键和值都是可以序列化的任意类型。3.PARQUET:列式存储文件格式,支持读取和写入列式存储的数据。4.ORC:高效列式存储文件格式,具有高压缩率和高性能的特点。5.AVRO:自描述数据序列化格式。6.JSONFILE:按行存储的JSON文件格式。#其中TEXTFILE为默认格式,建表时不指定,默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。1.SNAPPY:快速压缩技术,具有较快的压缩速度和较高的压缩比。2.GZIP:广泛使用的压缩算法,具有很高的压缩比,但是较慢。3.BZIP2:典型的通用文件压缩算法,具有较高的压缩比和较慢的压缩速度。4.LZO:快速Lempel-Ziv-Oberhumer压缩算法,具有高压缩比和快速的压缩速度。其中,Hive默认支持的压缩方式只有GZIP、LZO和Snappy。如果要使用其他压缩方式,需要在配置文件中手动添加。例如,我们可以使用以下命令将一张表存储为ORC文件格式,并使用Snappy压缩:CREATE TABLE mytable ( column1 INT, column2 STRING)STORED AS ORCTBLPROPERTIES ("orc.compress"="SNAPPY");关于分区和分桶的介绍可以参考我这篇文章:【大数据】Hive 分区和分桶的区别及示例讲解
在Hive中,ROW FORMAT DELIMITED 是用于指定表中数据的列分隔符和行分隔符的关键字,默认的列分隔符是制表符(Tab键),默认的行分隔符是换行符(\n)。
通过指定这些分隔符,用户可以将不同格式的数据导入到Hive表中,并在查询表时正确地解析数据。使用 ROW FORMAT DELIMITED,用户可以指定以下参数:
例如,以下是使用 ROW FORMAT DELIMITED 指定逗号作为列分隔符和换行符作为行分隔符来创建一个Hive表的示例:
CREATE TABLE mytable ( id INT, name STRING, age INT, address STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n';在Hive中,可以使用 INSERT 语句来向表中添加数据。Hive支持多种数据来源和格式,包括文本文件、CSV文件、JSON文件等。内部表(管理表)的数据只能通过 INSERT INTO 命令进行插入,而不能直接修改原始数据。普通表在被删除时,会将表中的数据一并删除。
以下是使用 INSERT 语句向Hive表中添加数据的基本语法:
INSERT INTO TABLE tablename [PARTITION (partition_column = partition_value, ...)][ROW FORMAT row_format][STORED AS file_format]SELECT ...;下面是向一个Hive表中添加数据的示例:
假设有一个Hive表mytable,其中包含四个字段:id、name、age和gender,用户可以使用以下命令向该表中添加数据:
INSERT INTO mytable VALUES (1, 'Alice', 25, 'F'), (2, 'Bob', 30, 'M'), (3, 'Charlie', 35, 'M');该命令将向mytable表中插入三行数据,每行数据包含四个字段。
用户也可以从其他表或查询结果中插入数据。例如,以下命令从另一个表yourtable中选择一些数据插入到mytable中:
INSERT INTO mytable (id, name, age, gender)SELECT id, name, age, genderFROM yourtableWHERE age > 25;该命令将从yourtable表中选择年龄大于25的数据,并将其插入到mytable表中。
【注意】向Hive表中添加数据时,数据格式和分隔符需要与表定义中的一致,否则会导致数据无法正确解析。可以使用 ROW FORMAT 和FIELDS TERMINATED BY等关键字来指定数据格式和分隔符。
使用LOAD DATA语句可以将本地或HDFS上的数据加载到Hive表中。具体语法和示例请见下面的示例:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partition_column = partition_value, ...)][ROW FORMAT row_format][FIELDS TERMINATED BY field_delim][LINES TERMINATED BY line_delim][STORED AS file_format];【注意】
例如,以下命令从本地文件系统加载数据文件到一个Hive表中:
# 导入本地文件系统文件数据到表,LOCALLOAD DATA LOCAL INPATH '/path/to/datafile' INTO TABLE mytable;在Hive中,可以创建外部表,这样可以将数据存储在HDFS或本地文件系统中,并且不会影响到原始数据文件。
CREATE EXTERNAL TABLE mytable (col1 INT, col2 STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION '/path/to/datafile';其中,mytable 是外部表的名称,col1 和 col2 是表的两个列,ROW FORMAT 和 FIELDS TERMINATED BY 关键字指定了数据格式和分隔符,LOCATION 关键字指定了数据存储位置,可以是HDFS或本地文件系统路径。
SELECT * FROM mytable;【注意】:
需要注意的是,向Hive表中添加数据时,数据格式和分隔符需要与表定义中的一致,否则会导致数据无法正确解析。可以使用 ROW FORMAT 和FIELDS TERMINATED BY等关键字来指定数据格式和分隔符。
使用 CREATE TABLE 语句来创建表。
语法:
CREATE TABLE table_name (col1 data_type, col2 data_type, ...)示例:
CREATE TABLE employee (id INT, name STRING, age INT, salary FLOAT);# 添加数据,不建议使用INSERT 效率很低,一般使用LOAD DATA方式导入数据INSERT INTO employee VALUES (1, 'Alice', 25, 5000.00), (2, 'Bob', 30, 6000.00), (3, 'Charlie', 35, 7000.00);# 导入数据(HDFS)LOAD DATA INPATH '/path/to/input/data' INTO TABLE employee;使用 ALTER TABLE 语句来修改表结构。
语法:
ALTER TABLE table_name ADD COLUMN col_name data_typeALTER TABLE table_name DROP COLUMN col_nameALTER TABLE table_name RENAME TO new_table_name示例:
ALTER TABLE employee ADD COLUMN gender STRING;使用 DROP TABLE 语句来删除表。
语法:
DROP TABLE table_name示例:
DROP TABLE employee用 CREATE TABLE ... PARTITIONED BY 语句来创建分区表。
语法:
CREATE TABLE table_name (col1 data_type, col2 data_type, ...)PARTITIONED BY (partition_col1 data_type, partition_col2 data_type, ...)示例:
CREATE TABLE employee_partitioned (id INT, name STRING, age INT, salary FLOAT)PARTITIONED BY (gender STRING);用 CREATE EXTERNAL TABLE 语句来创建外部表。
语法:
CREATE EXTERNAL TABLE table_name (col1 data_type, col2 data_type, ...)LOCATION '/path/to/table'示例:
CREATE EXTERNAL TABLE employee_external (id INT, name STRING, age INT, salary FLOAT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION '/user/hive/warehouse/employee_external';用 CREATE VIEW 语句来创建视图。
语法:
CREATE VIEW view_name AS SELECT col1, col2, ... FROM table_name示例:
CREATE VIEW employee_view AS SELECT id, name, age FROM employee WHERE age > 25;用 ALTER VIEW 语句来修改视图。
语法:
ALTER VIEW view_name AS SELECT col1, col2, ... FROM table_name WHERE condition示例:
ALTER VIEW employee_view AS SELECT id, name, age, salary FROM employee WHERE age > 25;用 DROP VIEW 语句来修改视图。
语法:
DROP VIEW view_name示例:
DROP VIEW employee_view;用 DESCRIBE VIEW 语句来查看视图定义。
语法:
DESCRIBE VIEW view_name示例:
DESCRIBE VIEW employee_view;总之,Hive中的DDL操作和视图操作可以帮助用户定义和管理表、视图等数据结构,从而更加灵活和高效地管理和查询数据。用户可以根据实际需求选择使用哪种操作方式,以达到更好的数据管理和操作效果。
责任编辑:武晓燕 来源: 今日头条 HiveDDL管理表(责任编辑:百科)
*ST康得(002450.SZ)2020年度实现归母净亏损32.05亿元 公司总资产81.01亿元
 *ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细]
*ST康得(002450.SZ)发布2020年年度报告,实现营业收入11.07亿元,与去年同比降低25.16%;利润总额亏损32.07亿元,归属于母公司净利润亏损32.05亿元,报告期末,公司总资产8
...[详细] 雷柏V708多模游戏键盘外观大气稳重,注塑上盖做工十分扎实,触感细腻略带有磨砂质感,而且不容易留下指纹,同时这款键盘采用104键全尺寸布局,搭配超窄边框体现出简约高效的设计理念。雷柏V708多模游戏键
...[详细]
雷柏V708多模游戏键盘外观大气稳重,注塑上盖做工十分扎实,触感细腻略带有磨砂质感,而且不容易留下指纹,同时这款键盘采用104键全尺寸布局,搭配超窄边框体现出简约高效的设计理念。雷柏V708多模游戏键
...[详细]华为Mate 60系列销售火爆 多家产业链公司被机构密集调研
 本报记者 李雯珊见习记者 解世豪继9月10日晚华为Mate 60系列正式开放全款购买后,9月11日上午10时08分,华为商城开启新一波下单抢购,不出意料,开售几秒内即售罄。受华为Mate 60系列正式
...[详细]
本报记者 李雯珊见习记者 解世豪继9月10日晚华为Mate 60系列正式开放全款购买后,9月11日上午10时08分,华为商城开启新一波下单抢购,不出意料,开售几秒内即售罄。受华为Mate 60系列正式
...[详细]《2021 Bots自动化威胁报告》深度解读之 自动化威胁4大特征 & 5大场景
 《2021 Bots自动化威胁报告》深度解读之 自动化威胁4大特征 & 5大场景作者:佚名 2021-07-20 12:21:20网络 自动化 自动化 瑞数信息在《2021年Bots自动化威胁
...[详细]
《2021 Bots自动化威胁报告》深度解读之 自动化威胁4大特征 & 5大场景作者:佚名 2021-07-20 12:21:20网络 自动化 自动化 瑞数信息在《2021年Bots自动化威胁
...[详细]1月浙江新设外商投资企业287家 实际使用外资规模居全国第五
 记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细]
记者3月2日从浙江省商务厅获悉,按商务部统计口径,2021年1月浙江新设外商投资企业287家,合同外资26.7亿美元,同比增长4.6%;浙江实际使用外资14亿美元,同比增长1.7%,实际使用外资规模居
...[详细] 回想过去,AMD FX系处理器已经陪伴我们走过了十几年的DIY时光。去年AMD推出Ryzen之后,FX系列似乎也走向了终结。沉浮之间,FX系列都经历了哪些兴衰?FX曾经的辉煌 惜败之后的沉沦说到AMD
...[详细]
回想过去,AMD FX系处理器已经陪伴我们走过了十几年的DIY时光。去年AMD推出Ryzen之后,FX系列似乎也走向了终结。沉浮之间,FX系列都经历了哪些兴衰?FX曾经的辉煌 惜败之后的沉沦说到AMD
...[详细] 学习效率翻倍,用ChatGPT来学习SQL数据分析作者:学研君 2023-05-04 12:41:30人工智能 在今天这个数据驱动的世界里,SQL是一项有价值的技能。通过使用ChatGPT来学习基础知
...[详细]
学习效率翻倍,用ChatGPT来学习SQL数据分析作者:学研君 2023-05-04 12:41:30人工智能 在今天这个数据驱动的世界里,SQL是一项有价值的技能。通过使用ChatGPT来学习基础知
...[详细] 漫步者W800BT立体声蓝牙耳机外形时尚动感,拥有苍穹黑、珍珠白和烈焰红三种配色,其轮廓曲线十分流畅,从上至下一气呵成,耳机外壳覆盖有高品质塑胶喷涂金属漆,再经特殊工艺处理后呈现精密螺旋车刀纹,因此极
...[详细]
漫步者W800BT立体声蓝牙耳机外形时尚动感,拥有苍穹黑、珍珠白和烈焰红三种配色,其轮廓曲线十分流畅,从上至下一气呵成,耳机外壳覆盖有高品质塑胶喷涂金属漆,再经特殊工艺处理后呈现精密螺旋车刀纹,因此极
...[详细] “换手率”也称"周转率",指在一定时间内市场中股票转手买卖的频率,是反映股票流通性强弱的指标之一。以样本总体的性质不同有不同的指标类型,如股票交易所所有上市
...[详细]
“换手率”也称"周转率",指在一定时间内市场中股票转手买卖的频率,是反映股票流通性强弱的指标之一。以样本总体的性质不同有不同的指标类型,如股票交易所所有上市
...[详细] 【智车派新闻】9月18日,智车派注意到,高合汽车品牌及传播总经理徐斌今日宣布,高合自研的高算力智能座舱平台将于明日的“高合展翼日”上亮相。他表示,这颗高合的高算力智能座舱实测最高算力跑分可达117万分
...[详细]
【智车派新闻】9月18日,智车派注意到,高合汽车品牌及传播总经理徐斌今日宣布,高合自研的高算力智能座舱平台将于明日的“高合展翼日”上亮相。他表示,这颗高合的高算力智能座舱实测最高算力跑分可达117万分
...[详细]
 受跟踪指数下调影响 “10月最惨基金”一月跌超30%
受跟踪指数下调影响 “10月最惨基金”一月跌超30% 中信银行的高质量增长与价值重估
中信银行的高质量增长与价值重估 统信软件打造核心生态攻坚战略,着力发展从量到质的生态圈
统信软件打造核心生态攻坚战略,着力发展从量到质的生态圈 微信8.0.8来了,App Store使用微信充值可享10%优惠!
微信8.0.8来了,App Store使用微信充值可享10%优惠! “放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞